EDITING OF CCR5 RECEPTOR GENE TO PROTECT AGAINST HIV
INFECTION
RELATED APPLICATIONS
[0001] This application claims priority under 35 U.S.C. § 119(e) to U.S. provisional patent application, U.S. S.N. 62/438,827, filed December 23, 2016, which is incorporated herein by reference.
GOVERNMENT SUPPORT
[0002] This invention was made with government support under grant number
GM065865, awarded by the National Institutes of Health (NIH). The government has certain rights in the invention.
BACKGROUND
[0003] C-C chemokine receptor type 5 (also commonly known as CCR5 or CD 195) is a protein found on the surface of white blood cells. CCR5 acts as a receptor for chemokines and has demonstrated involvement in several different disease states including, but not limited to, human immunodeficiency virus (HIV) and acquired immune deficiency syndrome (AIDS). Many strains of HIV, the virus that causes AIDS, initially use CCR5 to enter and infect host cells. A mutation known as CCR5-A32 in the CCR5 gene has been shown to protect those individuals that carry it against these strains of HIV. Loss-of-function CCR5 mutants have generated significant interest in the biotech and pharmaceutical industries in light of the widespread and devastating effects of HIV/AIDS ("HIV/AIDS Fact sheet Updated July 2016" from the World Health Organization). However, existing methods and technologies for creating CCR5 loss-of-function mutants in vivo have been ineffective due to the large number of cells that need to be modified. Other concerns involve off-target effects, genome instability, or oncogenic modifications that may be caused by genome-editing treatments.
SUMMARY
[0004] Provided herein are systems, compositions, kits, and methods for modifying a polynucleotide (e.g. DNA) encoding a CCR5 protein to produce a loss-of-function CCR5 variant. Also provided are systems, compositions, kits, and methods for modifying a polynucleotide encoding a CCR2 protein to produce loss-of-function CCR2 mutants. The methodology relies on CRISPR/Cas9-based base-editing technology. The precise targeting
methods described herein are superior to previously proposed strategies that create random indels in the CCR5 or CCR2 genomic locus using engineered nucleases. The methods also have a more favorable safety profile, due to low probability of off-target effects. Thus, the base editing methods described herein have a low impact on genomic stability, including oncogene activation or tumor suppressor inactivation. The loss-of-function CCR5 and/or CCR2 variants generated have a protective function against HIV infection (including prevention of HIV infection), decrease one or more sympotoms of HIV infection, halt or delay progression of HIV to AIDS, and/or decrease one or more sympotoms of AIDS.
[0005] Some aspects of the present disclosure provide a method of editing a polynucleotide encoding a C-C chemokine receptor type five (CCR5) protein, the method comprising contacting the CCR5-encoding polynucleotide with: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; and (ii) a guide nucleotide sequence targeting the fusion protein of (i) to a target cytosine (C) base in the CCR5-encoding polynucleotide; wherein the contacting results in deamination of the the target C base is by the fusion protein, resulting in a cytosine-guanine pair (C:G) to thymine- adenine pair (T:A) change in the CCR5-encoding polynucleotide. This may occur in any manner, and is not bound by any particular theory.
[0006] In one embodiment, the guide nucleotide sequence-programmable DNA binding protein domain is selected from the group consisting of: a nuclease inactive Cas9 (dCas9) domain, a nuclease inactive Cpfl domain, a nuclease inactive Argonaute domain, and variants and combinations thereof. As a set of non limiting examples, any of the fusion proteins described herein that include a Cas9 domain, can use another guide nucleotide sequence-programmable DNA binding protein, such as CasX, CasY, Cpfl, C2cl, C2c2, C2c3, and Argonaute, in place of the Cas9 domain. Guide nucleotide sequence- programmable DNA binding protein include, without limitation, Cas9 (e.g., dCas9 and nCas9), CasX, CasY, Cpfl, C2cl, C2c2, C2C3, Argonaute, and any of suitable protein described herein.
[0007] In another embodiment, the guide nucleotide sequence-programmable DNA- binding protein domain comprises a nuclease inactive Cas9 (dCas9) domain. In some embodiments, the amino acid sequence of the dCas9 domain comprises mutations
corresponding to D10A and/or H840A mutation(s) in SEQ ID NO: 1. In another
embodiment, the amino acid sequence of the dCas9 domain comprises a mutation
corresponding to a D10A mutation in SEQ ID NO: 1, and wherein the dCas9 domain
comprises a histidine at the position corresponding to amino acid 840 of SEQ ID NO: 1.
[0008] In certain embodiments, the guide nucleotide sequence-programmable DNA- binding protein domain comprises a nuclease inactive Cpfl (dCpfl) domain. In some embodiments, the dCpf ldomain is from a species of Acidaminococcus or Lachnospiraceae. In an embodiment, the guide nucleotide sequence-programmable DNA-binding protein domain comprises a nuclease inactive Argonaute (dAgo) domain. In a further embodiment, the dAgo domain is from Natronobacterium gregoryi.
[0009] As a set of non limiting examples, any of the fusion proteins described herein that include a Cas9 domain can use another guide nucleotide sequence-programmable DNA binding protein, such as CasX, CasY, Cpfl, C2cl, C2c2, C2c3, and Argonaute, in place of the Cas9 domain. These may be nuclease inactive variants of the proteins. Guide nucleotide sequence-programmable DNA binding protein include, without limitation, Cas9 (e.g., dCas9 and nCas9), saCas9 (e.g., saCas9d, saCas9n, saKKH Cas9), CasX, CasY, Cpfl, C2cl, C2c2, C2C3, Argonaute, and any of suitable protein described herein. In some embodiments, the fusion protein described herein comprises a Gam protein, a guide nucleotide sequence- programmable DNA binding protein, and a cytidine deaminase domain.
[0010] In some embodiments, the cytosine deaminase domain comprises an apolipoprotein B mRNA-editing complex (APOBEC) family deaminase. In an embodiment, the cytosine deaminase is selected from the group consisting of APOBEC 1, APOBEC2, APOBEC3A, APOBEC3B, APOBEC3C, APOBEC3D, APOBEC3F, APOBEC3G deaminase, APOBEC3H deaminase, APOBEC4 deaminase, activation-induced deaminase (AID), and pmCDAl. In an embodiment, the cytosine deaminase comprises an amino acid sequence of any one of SEQ ID NOs: 270-292.
[0011] In some embodiments, the fusion protein of (a) further comprises a uracil glycosylase inhibitor (UGI) domain. In certain embodiments, the cytosine deaminase domain is fused to the N-terminus of the guide nucleotide sequence-programmable DNA-binding protein domain. In an embodiment, the UGI domain is fused to the C-terminus of the guide nucleotide sequence-programmable DNA-binding protein domain.
[0012] In some embodiments, the cytosine deaminase and the guide nucleotide sequence-programmable DNA-binding protein domain are fused via an optional linker. In another embodiment, the UGI domain is fused to the dCas9 domain via an optional linker.
[0013] In certain embodiments, the fusion protein comprises the structure NH2-
[cytosine deaminase domain] -[optional linker sequence] -[guide nucleotide sequence- programmable DNA-binding protein domain] -[optional linker sequence] -[UGI domain] -
COOH.
[0014] In some embodiments, the linker comprises (GGGS)n (SEQ ID NO: 303),
(GGGGS)n (SEQ ID NO: 304), (G)„, (EAAAK)„ (SEQ ID NO: 305), (GGS)„,
SGSETPGTSESATPES (SEQ ID NO: 306), or (XP)n motif, or a combination of any of these, wherein n is independently an integer between 1 and 30, and wherein X is any amino acid. In an embodiment, the linker comprises the amino acid sequence SGSETPGTSESATPES (SEQ ID NO: 306). In another embodiment, the linker is (GGS)n, and wherein n is 1, 3, or 7.
[0015] In certain embodiments, the fusion protein comprises the amino acid sequence of any one of SEQ ID NO: 293-302.
[0016] In an embodiment, the polynucleotide encoding the CCR5 protein comprises a coding strand and a complementary strand. In some embodiments, the polynucleotide encoding the CCR5 protein comprises a coding region and a non-coding region. In an embodiment, the C to T change occurs in the coding sequence of the CCR5-encoding polynucleotide. In some embodiments, the C to T change leads to a mutation in the CCR5 protein.
[0017] In some embodiments, the mutation in the CCR5 protein is a loss-of-function mutation. In certain embodiments, the mutation is selected from the mutations listed in Tables 1-10. In one embodiment, the guide nucleotide sequence is selected from the guide nucleotide sequences listed in Tables 3-5 and 8-10. In certain embodiments, the loss-of- function mutation introduces a premature stop codon in the CCR5 coding sequence that leads to a truncated or non-functional CCR5 protein. In certain embodiments, the premature stop codon is TAG (Amber), TGA (Opal), or TAA (Ochre).
[0018] In some embodiments, the premature stop codon is generated from a CAG to
TAG change via the deamination of the first C on the coding strand. In certain embodiments, the premature stop codon is generated from a CGA to TGA change via the deamination of the first C on the coding strand. In an embodiment, the premature stop codon is generated from a CAA to TAA change via the deamination of the first C on the coding strand. In certain embodiments, the premature stop codon is generated from a TGG to TAG change via the deamination of the second C on the complementary strand. In an embodiment, the premature stop codon is generated from a TGG to TGA change via the deamination of the third C on the complementary strand. In an embodiment, the premature stop codon is generated from a TGG to TAA change via the deamination of the second C and third C on the complementary strand. In another embodiment, the premature stop codon is generated from a CGG to TAG or CGA to TAA change via the deamination of C on the coding strand and the deamination of
C on the complementary strand.
[0019] In some embodiments, the guide nucleotide sequence is selected from the guide nucleotide sequences (SEQ ID NO: 381-657) listed in Table 3, Table 4, Table 5, Table 8, or Table 9. In certain embodiments, tandem premature stop codons are introduced. In one embodiment, the mutation is selected from the group consisting of: Q186X/Q188X,
Q277X/Q288X, Q328X/Q329X, Q329X/R334X, or R341X/Q346X. In certain embodiments, the guide nucleotide sequence is selected from the group consisting of: SEQ ID NOs: 381- 657. In some embodiments, two guide nucleotides are selected from SEQ ID NOs: 381-657. In some embodiments, three or more guide nucleotides are selected from SEQ ID NOs: 381- 657.
[0020] In some embodiments, the loss-of-function mutation destabilizes CCR5 protein folding. In certain embodiments, the loss-of-function mutation is selected from the mutations listed in Tables 1-9. In specific embodiments, the guide nucleotide sequence is selected from the guide nucleotide sequences listed in Tables 3-5 and 8-9 (SEQ ID NO: 381- 657).
[0021] In some embodiments, the C to T change modifies a splicing site in the non- coding region of the CCR5-encoding polynucleotide. In one embodiment, the C to T change modifies at an intron-exon junction. In another embodiment, the C to T change modifies a splicing donor site. In another embodiment, the C to T change modifies a splicing acceptor site. In certain embodiments, the C to T changes occurs at a C base-paired with the G base in a start codon (AUG). In some embodiments, the C to T change prevents CCR5 mRNA maturation or abrogates CCR5 expression.
[0022] In some embodiments, the C to T change is selected from the C to T changes listed in Table 2, 8, or 9. In certain embodiments, the guide nucleotide sequence is selected from the guide nucleotide sequences (SEQ ID NOs: 577-657) listed in Tables 8 and 9.
[0023] In some embodiments, the C to T change results in a codon change in the
CCR5-encoding polynucleotide listed in Table 7. In certain embodiments, a PAM sequence is located 3' of the C being changed. In certain embodiments, a PAM sequence is located 5' of the C being changed. In specific embodiments, the PAM sequence is selected from the group consisting of: NGG, NGAN, NGNG, NGAG, NGCG, NNGRRT, NGRRN, NNNRRT, NNNGATT, NNAGAA, NAAAC, NNT, NNNT, and YNT, wherein Y is pyrimidine, R is purine, and N is any nucleobase.
[0024] In some embodiments, no PAM sequence is located 3' of the C being changed.
In some embodiments, no PAM sequence is located 5' of the C being changed. In certain
embodiments, no PAM sequence is located 5 Or 3 Of the C being changed. In some embodiments, at least 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 mutations are introduced into the CCR5- encoding polynucleotide. In certain embodiments, the guide nucleotide sequence is RNA (guide RNA or gRNA). In some embodiments, the guide nucleotide sequence is ssDNA (guide DNA or gDNA).
[0025] In some aspects, the disclosure provides a method of editing a polynucleotide encoding a C-C chemokine receptor type 2 (CCR2) protein, the method comprising contacting the CCR2-encoding polynucleotide with: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; and (ii) a guide nucleotide sequence targeting the fusion protein of (i) to a target cytosine (C) base in the CCR2-encoding polynucleotide, wherein the contacting results in the deamination of the target C base by the fusion protein, resulting in a cytosine - guanine (C:G) to thymine-adenine pair (T:A) change in the CCR2-encoding polynucleotide. In some embodiments, the fusion protein of (i) comprises a Gam protein.
[0026] In some embodiments, the C to T change is in the coding sequence of the
CCR2-encoding polynucleotide. In some embodiments, the C to T change leads to leads to a mutation in the CCR2 protein.
[0027] In some embodiments, the mutation in the CCR2 protein is a loss-of-function mutation. In certain embodiments, the mutation is selected from the mutations listed in Table 1.
[0028] In certain embodiments, the method is carried out in vitro. In some embodiments, the method is carried out in a cultured cell. In some embodiments, the method is carried out in vivo. In other embodiments, the method is carried out ex vivo.
[0029] In certain embodiments, the method is carried out in a mammal. In some embodiments, the mammal is a rodent. In some embodiments, the mammal is a primate. In some embodiments, the mammal is human.
[0030] In some aspects, the disclosure provides a method of editing a polynucleotide encoding a C-C chemokine receptor type five (CCR2) protein, the method comprising contacting the CCR2-encoding polynucleotide with: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; and (ii) a guide nucleotide sequence targeting the fusion protein of (i) to a target cytosine (C) base in the CCR2-encoding polynucleotide; wherein the target C base is deaminated by the fusion protein, resulting in a cytosine-guanine pair (C:G) to thymine- adenine pair (T:A) change in the CCR2-encoding polynucleotide. In some embodiments, the
fusion protein of (i) comprises a Gam protein.
[0031] In some embodiments, the guide nucleotide sequence-programmable DNA binding protein domain is selected from the group consisting of: a nuclease inactive Cas9 (dCas9) domain, a nuclease inactive Cpfl domain, a nuclease inactive Argonaute domain, and variants and combinations thereof. In certain embodiments, the guide nucleotide sequence-programmable DNA-binding protein domain comprises a nuclease inactive Cas9 (dCas9) domain.
[0032] In some embodiments, the amino acid sequence of the dCas9 domain comprises mutations corresponding to DIOA and/or H840A mutation(s) in SEQ ID NO: 1. In specific embodiments, the amino acid sequence of the dCas9 domain comprises a mutation corresponding to a DIOA mutation in SEQ ID NO: 1, and wherein the dCas9 domain comprises a histidine at the position corresponding to amino acid 840 of SEQ ID NO: 1. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein domain comprises a nuclease inactive Cpfl (dCpfl) domain. In a specific embodiment, the dCpfl domain is from a species of Acidaminococcus or Lachnospiraceae. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein domain comprises a nuclease inactive Argonaute (dAgo) domain. In an embodiment, the dAgo domain is from Natronobacterium gregoryi.
[0033] As a set of non limiting examples, any of the fusion proteins described herein that include a Cas9 domain can use another guide nucleotide sequence-programmable DNA binding protein, such as CasX, CasY, Cpfl, C2cl, C2c2, C2c3, and Argonaute, in place of the Cas9 domain. These may be nuclease inactive variants of the proteins. Guide nucleotide sequence-programmable DNA binding protein include, without limitation, Cas9 {e.g., dCas9 and nCas9), saCas9 {e.g., saCas9d, saCas9n, and saKKH Cas9), CasX, CasY, Cpfl, C2cl, C2c2, C2C3, Argonaute, and any of suitable protein described herein. In some embodiments, the fusion protein described herein comprises a Gam protein, a guide nucleotide sequence- programmable DNA binding protein, and a cytidine deaminase domain.
[0034] In some embodiments, the cytosine deaminase domain comprises an apolipoprotein B mRNA-editing complex (APOBEC) family deaminase. In specific embodiments, the cytosine deaminase is selected from the group consisting of APOBEC 1, APOBEC2, APOBEC3A, APOBEC3B, APOBEC3C, APOBEC3D, APOBEC3F,
APOBEC3G deaminase, APOBEC3H deaminase, APOBEC4 deaminase, activation-induced deaminase (AID), and pmCDAl. In an embodiment, the cytosine deaminase comprises an amino acid sequence of any one of SEQ ID NOs: 270-292.
[0035] In some embodiments, the fusion protein of (a) further comprises a uracil glycosylase inhibitor (UGI) domain. In certain embodiments, the cytosine deaminase domain is fused to the N-terminus of the guide nucleotide sequence-programmable DNA-binding protein domain. In specific embodiments, the UGI domain is fused to the C-terminus of the guide nucleotide sequence-programmable DNA-binding protein domain. In some
embodiments, the cytosine deaminase and the guide nucleotide sequence-programmable DNA-binding protein domain are fused via an optional linker. In an embodiment, the UGI domain is fused to the dCas9 domain via an optional linker.
[0036] In certain embodiments, the fusion protein comprises the structure N¾-
[cytosine deaminase domain] -[optional linker sequence] -[guide nucleotide sequence- programmable DNA-binding protein domain] -[optional linker sequence] -[UGI domain] - COOH.
[0037] In some embodiments, the linker comprises (GGGS)n (SEQ ID NO: 303),
(GGGGS)n (SEQ ID NO: 304), (G)„, (EAAAK)n (SEQ ID NO: 305), (GGS)„,
SGSETPGTSESATPES (SEQ ID NO: 306), or (XP)n motif, or a combination of any of these, wherein n is independently an integer between 1 and 30, and wherein X is any amino acid. In an embodiment, linker comprises the amino acid sequence SGSETPGTSESATPES (SEQ ID NO: 306). In some embodiments, the linker is (GGS)n, and wherein n is 1, 3, or 7.
[0038] In some aspects, the instant disclosure provides a composition comprising: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; and (ii) a guide nucleotide sequence targeting the fusion protein of (i) to a polynucleotide encoding a C-C chemokine receptor type five (CCR5) protein. In some embodiments, the fusion protein of (i) comprises a Gam protein.
[0039] In some aspects, the instant disclosure provides a composition comprising: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; and (ii) a guide nucleotide sequence targeting the fusion protein of (i) to a polynucleotide encoding a C-C chemokine receptor type two (CCR2) protein. In some embodiments, the fusion protein of (i) comprises a Gam protein.
[0040] In some aspects, the instant disclosure provides a composition comprising: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; (ii) a guide nucleotide sequence targeting the fusion protein of (i) to a polynucleotide encoding a C-C chemokine receptor
type five (CCR5) protein; and (iii) a guide nucleotide sequence targeting the fusion protein of (i) to a polynucleotide encoding a C-C chemokine receptor type 2 (CCR2) protein. In some embodiments, the fusion protein of (i) comprises a Gam protein.
[0041] In some embodiments, the guide nucleotide sequence of (ii) is selected from
SEQ ID NOs: 381-657.
[0042] In certain embodiments, the composition further comprises a pharmaceutically acceptable carrier.
[0043] In some embodiments, the instant disclosure provides a method of reducing the binding of gpl20 and CCR5 in a subject, the method comprising administering to a subject in need thereof a therapeutically effective amount of a composition of the instant disclosure.
[0044] In some embodiments, the instant disclosure provides a method of reducing virus binding to CCR5 in a subject, the method comprising administering to a subject in need thereof a therapeutically effective amount of the composition of the instant disclosure.
[0045] In some embodiments, the instant disclosure provides a method of reducing viral infection in a subject, the method comprising administering to a subject in need thereof a therapeutically effective amount of a composition of the instant disclosure.
[0046] In some embodiments, the instant disclosure provides a method of reducing functional CCR5 receptors on a cell in a subject, the method comprising administering to a subject in need thereof a therapeutically effective amount of the composition of the instant disclosure.
[0047] In some embodiments, the cell is selected from the group consisting of:
macrophage, dendritic cell, memory T cell, endothelial cell, epithelial cell, vascular smooth muscle cell, fibroblast, microglia, neuron, and astrocyte.
[0048] In some embodiments, the instant disclosure provides a treating a condition, the method comprising administering to a subject in need thereof a therapeutically effective amount of a composition provided by the instant disclosure, wherein the condition is human immunodeficiency virus (HIV) infection, acquired immune deficiency syndrome (AIDS), an immunologic disease, or a combination thereof.
[0049] In one embodiment, the condition is human immunodeficiency virus (HIV) infection.
[0050] In some embodiments, the instant disclosure provides a method of preventing a condition, the method comprising administering to a subject in need thereof a
therapeutically effective amount of a composition provided in the instant disclosure, wherein
the condition is human immunodeficiency virus (HIV) infection, acquired immune deficiency syndrome (AIDS), an immunologic disease, or a combination thereof.
[0051] In certain embodiments, the condition is human immunodeficiency virus
(HIV) infection.
[0052] In some embodiments, the instant disclosure provides a kit comprising a composition provided in the instant disclosure.
[0053] The summary above is meant to illustrate, in a non-limiting manner, some of the embodiments, advantages, features, and uses of the technology disclosed herein. Other embodiments, advantages, features, and uses of the technology disclosed herein will be apparent from the Detailed Description, the Drawings, the Examples, and the Claims. The details of certain embodiments of the disclosure are set forth in the Detailed Description of Certain Embodiments, as described below. Other features, objects, and advantages of the presented compositions and methods will be apparent from the Definitions, Examples, Figures, and Claims.
BRIEF DESCRIPTION OF THE DRAWINGS
[0054] The accompanying drawings, which constitute a part of this specification, illustrate several embodiments of the invention and together with the description, serve to explain the principles of the invention.
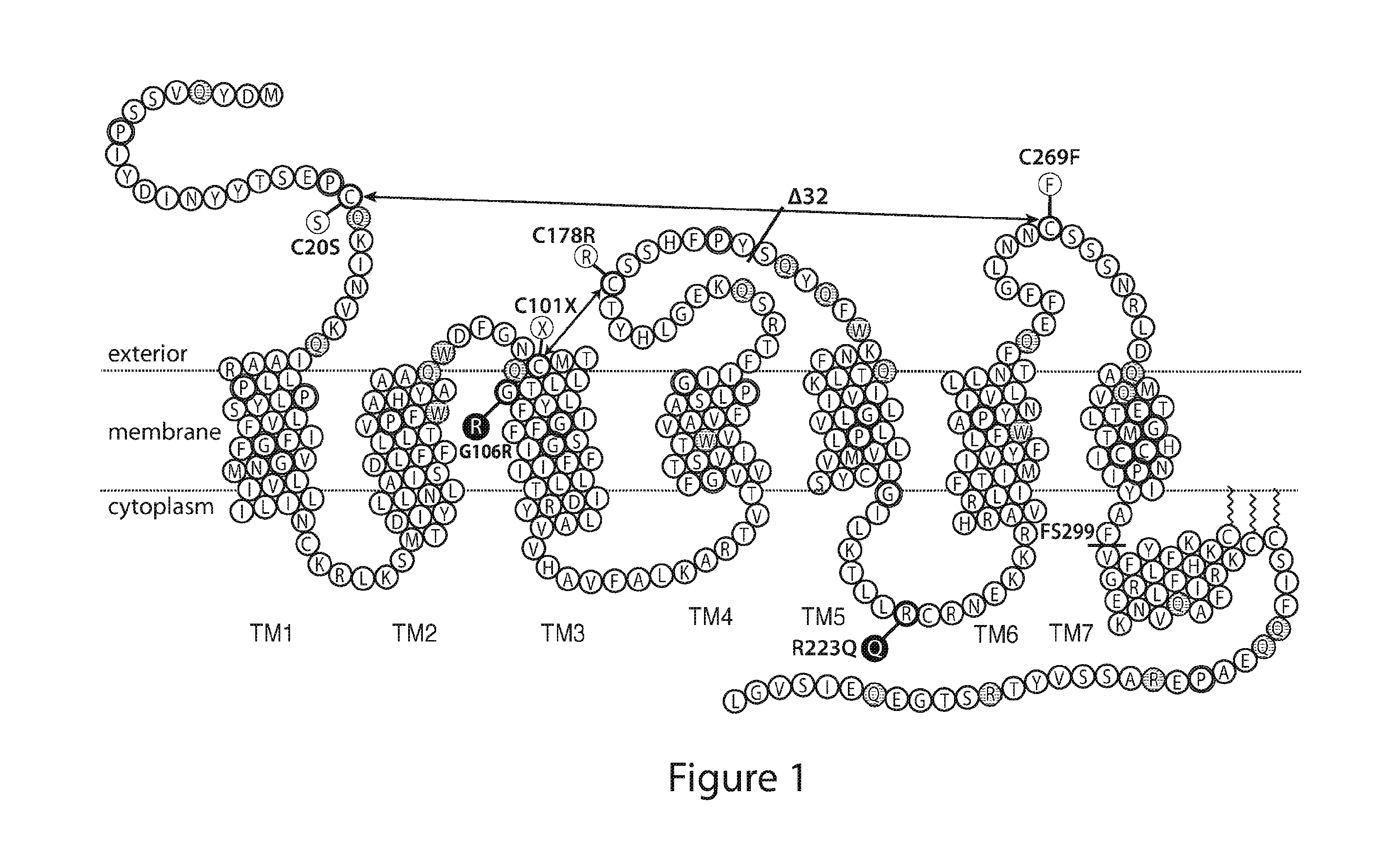
[0055] Figure 1 depicts a CCR5 protein structure which shows HIV-protective variants (C20S, C101X, G106R, C178R, Δ32, R223Q, C269F, and FS299) that can be replicated or imitated using genome/base-editing with APOBECl-Cas9 tools (Tables 1-10). Arrows indicate disulfide bridges that can be disrupted by mutation of cysteine residues using base-editing reactions (TGT -> TAT or TGC TAC, Table 3). Grey shading with a double ring around the residue indicates small/hydrophobic residues in a transmembrane domain (TM) that can be targeted for base-editing reactions to engineer CCR5 variants with a destabilizing polar residue that prevents membrane integration of folding (similar to the mutation G106R, Tables 1 and 4) using the guide-RNAs described in Tables 3 and 4. Other structurally important proline and cysteine residues are also shown in grey shading with a double ring around the residue (Table 4). Residues demarcated with grey shading and a single ring not specifically labeled with a mutation (i.e., not G106R or R223Q) are glutamine, tryptophan, and arginine residues, which can be changed into stop codons to prevent the translation of full-length functional protein (Table 5), mimicking the effect of the CCR5-A32 and FS299 alleles. The sequence corresponds to SEQ ID NO: 310.
[0056] Figures 2 A to 2 C are graphic representations of sequence alignments and structure. Figure 2A shows a strategy for preventing CCR5 protein production by altering splicing sites: donor site, branch-point, or acceptor sites (Table 2). Figure 2B shows consensus sequences of the human Lariat-structure branch-point and acceptor sites, suggesting that the guanosine of the acceptor site is an excellent target for Cas9-mediated base-editing of C-^T on the complementary strand (Table 2). Figure 2C shows the genomic sequence of the CCR5 gene showing the junction of intron 2 (lowercase) and exon 2
(capitalized), the cognate start-codon (boldface), potential branch-points (italics), and the cognate donor site (underlined). The sequence corresponds to SEQ ID NO: 311.
[0057] Figure 3 is a graphic representation of protein and open-reading frame sequences of the CCR5 receptor. HIV-protective variants (C20S, C101X, G106R, C178R, Δ32, R223Q, C269F, and FS299) that can be replicated or imitated using genome/base- editing with APOBECl-Cas9 tools (Tables 1-10) are underlined. Grey shading indicates small/hydrophobic residues in a transmembrane domain (TM) that can be targeted for base- editing reactions to engineer CCR5 variants with a destabilizing polar residue that prevents membrane integration of folding (similar to the mutation G106R, Tables 1 and 4) using the guide-RNAs described in Tables 3 and 4. Other structurally important proline and cysteine residues are also shown in grey shading with a double ring around the residue (Table 4). Residues demarcated with grey shading and a single ring not specificallylabeled with a mutation (i.e., not G106R or R223Q) are glutamine, tryptophan, and arginine residues, which can be changed into stop codons to prevent the translation of full-length functional protein (Table 5), mimicking the effect of the CCR5-A32 and FS299 alleles. The nucleotide sequence corresponds to SEQ ID NO: 312 and the amino acid sequence corresponds to SEQ ID NO: 313.
[0058] Figure 4 is a graphic representation of a numbering scheme used herein. The numbering scheme is based on the predicted location of the target C within the single stranded stretch of DNA (R-loop) displaced by a programmable guide RNA sequence occurring when a DNA-binding domain (e.g. Cas9, nCas9, dCas9) binds a genomic site. The sequence corresponds to SEQ ID NO: 314.
[0059] Figure 5 is a graphic representation of C to T editing of CCR5 target DNA
(SEQ ID NO: 738) in HEK293 cells using KKH-SaBE3 and guide-RNA Q186X-e. The editing was calculated from total reads (MiSeq). Panel A demonstrates that significant editing was observed at position C7 and C13 of SEQ ID NO: 739 (complementary nucleotide sequence is SEQ ID NO: 741), both of which generate premature stop codons in tandem
(Q186X and Q188X, see inset graphic of panel A and amino acid sequence of SEQ ID NO: 740). The PAM sequence (SEQ ID NO: 736) is shown as underlined and the last nucleotide of the protospacer (SEQ ID NO: 735) is separated with a line. Raw data used for base-calling and calculating base-editing for KKH-BE3 and Q186X-e treated HEK293 cells is shown in panel B. The indel percentage was 1.97%. Panel C shows raw data collected for untreated control cells.
DEFINITIONS
[0060] As used herein and in the claims, the singular forms "a," "an," and "the" include the singular and the plural reference unless the context clearly indicates otherwise. Thus, for example, a reference to "an agent" includes a single agent and a plurality of such agents.
[0061] As used herein, the term "C-C Chemokine Receptor 2" (also referred to as "C-
C Chemokine Receptor type 2," "CCR2," "CCR-2," "cluster of differentiation 192," and "CD 192") is a chemokine receptor encoded by the CCR2 gene. The CCR2 gene encodes two isoforms of the CCR2 protein, which is expressed on peripheral blood monocytes, activated T cells, B cells, and immature dendritic cells. Known ligands for CCR2 include the monocyte chemotactic proteins (MCPs) MCP-1, -2 and -3, which belong to the family of C-C chemokines.
[0062] As used herein, "C-C Chemokine Receptor 5" (also referred to as "C-C
Chemokine Receptor type 5," "CCR5," "CCR-5," "cluster of differentiation- 195," and "CD195," is a member of the beta chemokine receptor family. This protein is expressed by macrophages, dendritic cells, and memory T cells of the immune system; endothelila cells, epithelial cells, vascular smooth muscle cells, and fibroblasts; and microglia, neurons, and astrocytes in the central nervous system. See, e.g., Barmania and Pepper, Applied &
Translational Genomics 2 (2013) 3-16, which is incorporated herein by reference.
[0063] The term "effective amount," as used herein, refers to an amount of a biologically active agent that is sufficient to elicit a desired biological response. For example, in some embodiments, an effective amount of a nuclease may refer to the amount of the nuclease that is sufficient to induce cleavage of a target site specifically bound and cleaved by the nuclease. In some embodiments, an effective amount of a fusion protein provided herein, e.g., of a fusion protein comprising a nuclease-inactive Cas9 domain and a nucleic acid-editing domain (e.g., a deaminase domain) may refer to the amount of the fusion protein that is sufficient to induce editing of a target site specifically bound and edited by the
fusion protein. As will be appreciated by the skilled artisan, the effective amount of an agent, e.g., a fusion protein, a deaminase, a hybrid protein, a protein dimer, a complex of a protein (or protein dimer) and a polynucleotide, or a polynucleotide, may vary depending on various factors, such as, for example, on the desired biological response, e.g., on the specific allele, genome, or target site to be edited, on the cell or tissue being targeted, and/or on the agent being used.
[0064] The term "Gam protein," as used herein, refers generally to proteins capable of binding to one or more ends of a double strand break of a double stranded nucleic acid (e.g., double stranded DNA). In some embodiments, the Gam protein prevents or inhibits degradation of one or more strands of a nucleic acid at the site of the double strand break. In some embodiments, a Gam protein is a naturally-occurring Gam protein from bacteriophage Mu, or a non-naturally occurring variant thereof.
[0065] The term "loss-of-function mutation" or "inactivating mutation" refers to a mutation that results in the gene product having less or no function (being partially or wholly inactivated). When the allele has a complete loss of function (null allele), it is often called an amorphic mutation in the Muller's morphs schema. Phenotypes associated with such mutations are most often recessive. Exceptions are when the organism is haploid, or when the reduced dosage of a normal gene product is not enough for a normal phenotype (this is called haploinsufficiency) .
[0066] The term "gain-of-function mutation" or "activating mutation" refers to a mutation that changes the gene product such that its effect gets stronger (enhanced activation) or even is superseded by a different and abnormal function. A gain of function mutation may also be referred to as a neomorphic mutation. When the new allele is created, a heterozygote containing the newly created allele as well as the original will express the new allele, genetically defining the mutations as dominant phenotypes.
[0067] The terms "treatment," "treat," and "treating" refer to a clinical intervention aimed to reverse, alleviate, delay the onset of, or inhibit the progress of a disease or disorder, or one or more symptoms thereof, as described herein. In some embodiments, treatment may be administered after one or more symptoms have developed and/or after a disease has been diagnosed. Treatment may also be continued after symptoms have resolved, for example, to prevent or delay their recurrence. In one embodiment, the methods and compositions disclosed herein may be used to delay the onset of AIDS in an individual infected with HIV. The terms "prevention," "prevent," and "preventing" refer to a clinical intervention aimed to inhibit the onset of a disease or disorder, or one or more symptoms thereof, as described
herein. In one embodiment, treatment may be administered in the absence of symptoms, e.g., to prevent or delay onset of a symptom or inhibit onset or progression of a disease. In one embodiment, the methods and compositions disclosed herein may be used to prevent infection of a subject with HIV. In one example, treatment may be administered to a susceptible individual prior to the onset of symptoms (e.g., in light of a history of symptoms and/or in light of genetic or other susceptibility factors) in order to prevent the onset of the disease or symptoms of the disease.
[0068] The term "genome" refers to the genetic material of a cell or organism. It typically includes DNA (or RNA in the case of RNA viruses). The genome includes both the genes, the coding regions, the noncoding DNA, and the genomes of the mitochondria and chloroplasts. A genome does not typically include genetic material that is artificially introduced into a cell or organism, e.g., a plasmid that is transformed into a bacteria is not a part of the bacterial genome.
[0069] A "programmable DNA-binding protein" refers to DNA binding proteins that can be programmed to target any desired nucleotide sequence within a genome. To program the DNA-binding protein to bind a desired nucleotide sequence, the DNA binding protein may be modified to change its binding specificity, e.g., zinc finger nuclease (ZFN) or transcription activator-like effector proteins (TALE). ZFNs are artificial restriction enzymes generated by fusing a zinc finger DNA-binding domain to a DNA-cleavage domain. Zinc finger domains can be engineered to target specific desired DNA sequences and this enables zinc-fingers to bind unique sequences within complex genomes. Transcription activator-like effector nucleases (TALEN) are engineered restriction enzymes that can be engineered to cut specific sequences of DNA. They are made by fusing a TAL effector DNA-binding domain to a nuclease domain (e.g., Fokl). Transcription activator-like effectors (TALEs) can be engineered to bind practically any desired DNA sequence. Methods for programming ZFNs and TALEs are familiar to one skilled in the art. For example, such methods are described in Maeder, et al, Mol. Cell 31 (2): 294-301, 2008; Carroll et al, Genetics Society of America, 188 (4): 773-782, 2011; Miller et al, Nature Biotechnology 25 (7): 778-785, 2007; Christian et al, Genetics 186 (2): 757-61, 2008; Li et al, Nucleic Acids Res 39 (1): 359-372, 2010; and Moscou et al, Science 326 (5959): 1501, 2009, the entire contents of each of which are incorporated herein by reference.
[0070] A "guide nucleotide sequence-programmable DNA-binding protein" refers to a protein, a polypeptide, or a domain that is able to bind DNA, and the binding to its target DNA sequence is mediated by a guide nucleotide sequence. Thus, it is appreciated that the
guide nucleotide sequence-programmable DNA-binding protein binds to a guide nucleotide sequence. The "guide nucleotide" may be an RNA or DNA molecule (e.g., a single-stranded DNA or ssDNA molecule) that is complementary to the target sequence and can guide the DNA binding protein to the target sequence. As such, a guide nucleotide sequence- programmable DNA-binding protein may be a RNA-programmable DNA-binding protein (e.g., a Cas9 protein), or an ssDNA-programmable DNA-binding protein (e.g., an Argonaute protein). "Programmable" means the DNA-binding protein may be programmed to bind any DNA sequence that the guide nucleotide targets. Exemplary guide nucleotide sequence- programmable DNA-binding proteins include, but are not limited to, Cas9 (e.g., dCas9 and nCas9), saCas9 (e.g., saCasd, saCasn, and saKKH Cas9), CasX, CasY, Cpfl, C2cl, C2c2, C2c3, Argonaute, and any other suitable protein described herein. In some embodiments, the fusion protein described herein comprises a Gam protein, a guide nucleotide sequence- programmable DNA binding protein, and a cytidine deaminase domain.
[0071] In some embodiments, the guide nucleotide sequence exists as a single nucleotide molecule and comprises comprise two domains: (1) a domain that shares homology to a target nucleic acid (e.g., and directs binding of a guide nucleotide sequence- programmable DNA-binding protein to the target); and (2) a domain that binds a guide nucleotide sequence-programmable DNA-binding protein. In some embodiments, domain (2) corresponds to a sequence known as a tracrRNA, and comprises a stem-loop structure. For example, in some embodiments, domain (2) is identical or homologous to a tracrRNA as provided in Jinek et al., Science 337:816-821(2012), which is incorporated herein by reference. Other examples of gRNAs (e.g., those including domain (2)) can be found in U.S. Patent Application Publication US20160208288 and U.S. Patent Application Publication US20160200779, each of which is herein incorporated by reference.
[0072] Because the guide nucleotide sequence hybridizes to a target DNA sequence, the guide nucleotide sequence-programmable DNA-binding proteins are able to specifically bind, in principle, to any sequence complementary to the guide nucleotide sequence.
Methods of using guide nucleotide sequence-programmable DNA-binding protein, such as Cas9, for site-specific cleavage (e.g., to modify a genome) are known in the art (see e.g., Cong, L. et al. Multiplex genome engineering using CRISPR/Cas systems. Science 339, 819- 823 (2013); Mali, P. et al. RNA-guided human genome engineering via Cas9. Science 339, 823-826 (2013); Hwang, W.Y. et al. Efficient genome editing in zebrafish using a CRISPR- Cas system. Nature biotechnology 31, 227-229 (2013); Jinek, M. et al. RNA-programmed genome editing in human cells. eLife 2, e00471 (2013); Dicarlo, J.E. et al. Genome
engineering in Saccharomyces cerevisiae using CRISPR-Cas systems. Nucleic acids research (2013); Jiang, W. et al. RNA-guided editing of bacterial genomes using CRISPR-Cas systems. Nature biotechnology 31, 233-239 (2013); the entire contents of each of which are incorporated herein by reference).
[0073] As used herein, the term "Cas9" or "Cas9 nuclease" refers to an RNA-guided nuclease comprising a Cas9 protein, fragment, or variant thereof. A Cas9 nuclease is also referred to sometimes as a casnl nuclease or a CRISPR (clustered regularly interspaced short palindromic repeat)-associated nuclease. CRISPR is an adaptive immune system that provides protection against mobile genetic elements (viruses, transposable elements, and conjugative plasmids). CRISPR clusters contain spacers, sequences complementary to antecedent mobile elements, and target invading nucleic acids. CRISPR clusters are transcribed and processed into CRISPR RNA (crRNA). In type II CRISPR systems correct processing of pre-crRNA requires a trans-encoded small RNA (tracrRNA), endogenous ribonuclease 3 (rnc) and a Cas9 protein. The tracrRNA serves as a guide for ribonuclease 3- aided processing of pre-crRNA. Subsequently, Cas9/crRNA/tracrRNA endonucleolytically cleaves linear or circular dsDNA target complementary to the spacer. The target strand not complementary to crRNA is first cut endonucleolytically, then trimmed 3 '-5'
exonucleolytically. In nature, DNA-binding and cleavage typically requires protein and both RNAs. However, single guide RNAs ("sgRNA", or simply "gNRA") can be engineered so as to incorporate aspects of both the crRNA and tracrRNA into a single RNA species. See, e.g., Jinek et ah, Science 337:816-821(2012), which is incorporated herein by reference.
[0074] Cas9 nuclease sequences and structures are known to those of skill in the art
(see, e.g., Ferretti et al, Proc. Natl. Acad. Sci. 98:4658-4663(2001); Deltcheva E. et al, Nature 471:602-607(2011); and Jinek et al, Science 337:816-821(2012), the entire contents of each of which are incorporated herein by reference). Cas9 orthologs have been described in various species, including, but not limited to, S. pyogenes and S. thermophilus . Additional suitable Cas9 nucleases and sequences will be apparent to those of skill in the art based on this disclosure, and such Cas9 nucleases and sequences include Cas9 sequences from the organisms and loci disclosed in Chylinski et al., (2013) RNA Biology 10:5, 726-737; which is incorporated herein by reference. In some embodiments, wild type Cas9 corresponds to Cas9 from Streptococcus pyogenes (NCBI Reference Sequence: NC_002737.2, SEQ ID NO: 4 (nucleotide); and Uniprot Reference Sequence: Q99ZW2, SEQ ID NO: 1 (amino acid).
Streptococcus pyogenes Cas9 (wild type) nucleotide sequence
ATGGATAAGAAATACTCAATAGGCTTAGATATCGGCACAAATAGCGTCGGATGGGCGGTGATCAC
TGATGAATATAAGGTTCCGTCTAAAAAGTTCAAGGTTCTGGGAAATACAGACCGCCACAGTATCA
AAAAAAATCTTATAGGGGCTCTTTTATTTGACAGTGGAGAGACAGCGGAAGCGACTCGTCTCAAA
CGGACAGCTCGTAGAAGGTATACACGTCGGAAGAATCGTATTTGTTATCTACAGGAGATTTTTTCA
AATGAGATGGCGAAAGTAGATGATAGTTTCTTTCATCGACTTGAAGAGTCTTTTTTGGTGGAAGAA
GACAAGAAGCATGAACGTCATCCTATTTTTGGAAATATAGTAGATGAAGTTGCTTATCATGAGAAA
TATCCAACTATCTATCATCTGCGAAAAAAATTGGTAGATTCTACTGATAAAGCGGATTTGCGCTTA
ATCTATTTGGCCTTAGCGCATATGATTAAGTTTCGTGGTCATTTTTTGATTGAGGGAGATTTAAATC
CTGATAATAGTGATGTGGACAAACTATTTATCCAGTTGGTACAAACCTACAATCAATTATTTGAAG
AAAACCCTATTAACGCAAGTGGAGTAGATGCTAAAGCGATTCTTTCTGCACGATTGAGTAAATCAA
GACGATTAGAAAATCTCATTGCTCAGCTCCCCGGTGAGAAGAAAAATGGCTTATTTGGGAATCTCA
TTGCTTTGTCATTGGGTTTGACCCCTAATTTTAAATCAAATTTTGATTTGGCAGAAGATGCTAAATT
ACAGCTTTCAAAAGATACTTACGATGATGATTTAGATAATTTATTGGCGCAAATTGGAGATCAATA
TGCTGATTTGTTTTTGGCAGCTAAGAATTTATCAGATGCTATTTTACTTTCAGATATCCTAAGAGTA
AATACTGAAATAACTAAGGCTCCCCTATCAGCTTCAATGATTAAACGCTACGATGAACATCATCAA
GACTTGACTCTTTTAAAAGCTTTAGTTCGACAACAACTTCCAGAAAAGTATAAAGAAATCTTTTTT
GATCAATCAAAAAACGGATATGCAGGTTATATTGATGGGGGAGCTAGCCAAGAAGAATTTTATAA
ATTTATCAAACCAATTTTAGAAAAAATGGATGGTACTGAGGAATTATTGGTGAAACTAAATCGTGA
AGATTTGCTGCGCAAGCAACGGACCTTTGACAACGGCTCTATTCCCCATCAAATTCACTTGGGTGA
GCTGCATGCTATTTTGAGAAGACAAGAAGACTTTTATCCATTTTTAAAAGACAATCGTGAGAAGAT
TGAAAAAATCTTGACTTTTCGAATTCCTTATTATGTTGGTCCATTGGCGCGTGGCAATAGTCGTTTT
GCATGGATGACTCGGAAGTCTGAAGAAACAATTACCCCATGGAATTTTGAAGAAGTTGTCGATAA
AGGTGCTTCAGCTCAATCATTTATTGAACGCATGACAAACTTTGATAAAAATCTTCCAAATGAAAA
AGTACTACCAAAACATAGTTTGCTTTATGAGTATTTTACGGTTTATAACGAATTGACAAAGGTCAA
ATATGTTACTGAAGGAATGCGAAAACCAGCATTTCTTTCAGGTGAACAGAAGAAAGCCATTGTTG
ATTTACTCTTCAAAACAAATCGAAAAGTAACCGTTAAGCAATTAAAAGAAGATTATTTCAAAAAA
ATAGAATGTTTTGATAGTGTTGAAATTTCAGGAGTTGAAGATAGATTTAATGCTTCATTAGGTACC
TACCATGATTTGCTAAAAATTATTAAAGATAAAGATTTTTTGGATAATGAAGAAAATGAAGATATC
TTAGAGGATATTGTTTTAACATTGACCTTATTTGAAGATAGGGAGATGATTGAGGAAAGACTTAAA
ACATATGCTCACCTCTTTGATGATAAGGTGATGAAACAGCTTAAACGTCGCCGTTATACTGGTTGG
GGACGTTTGTCTCGAAAATTGATTAATGGTATTAGGGATAAGCAATCTGGCAAAACAATATTAGAT
TTTTTGAAATCAGATGGTTTTGCCAATCGCAATTTTATGCAGCTGATCCATGATGATAGTTTGACAT
TTAAAGAAGACATTCAAAAAGCACAAGTGTCTGGACAAGGCGATAGTTTACATGAACATATTGCA
AATTTAGCTGGTAGCCCTGCTATTAAAAAAGGTATTTTACAGACTGTAAAAGTTGTTGATGAATTG
GTCAAAGTAATGGGGCGGCATAAGCCAGAAAATATCGTTATTGAAATGGCACGTGAAAATCAGAC
AACTCAAAAGGGCCAGAAAAATTCGCGAGAGCGTATGAAACGAATCGAAGAAGGTATCAAAGAA
TTAGGAAGTCAGATTCTTAAAGAGCATCCTGTTGAAAATACTCAATTGCAAAATGAAAAGCTCTAT
CTCTATTATCTCCAAAATGGAAGAGACATGTATGTGGACCAAGAATTAGATATTAATCGTTTAAGT
GATTATGATGTCGATCACATTGTTCCACAAAGTTTCCTTAAAGACGATTCAATAGACAATAAGGTC
TTAACGCGTTCTGATAAAAATCGTGGTAAATCGGATAACGTTCCAAGTGAAGAAGTAGTCAAAAA
GATGAAAAACTATTGGAGACAACTTCTAAACGCCAAGTTAATCACTCAACGTAAGTTTGATAATTT
AACGAAAGCTGAACGTGGAGGTTTGAGTGAACTTGATAAAGCTGGTTTTATCAAACGCCAATTGG
TTGAAACTCGCCAAATCACTAAGCATGTGGCACAAATTTTGGATAGTCGCATGAATACTAAATACG
ATGAAAATGATAAACTTATTCGAGAGGTTAAAGTGATTACCTTAAAATCTAAATTAGTTTCTGACT
TCCGAAAAGATTTCCAATTCTATAAAGTACGTGAGATTAACAATTACCATCATGCCCATGATGCGT
ATCTAAATGCCGTCGTTGGAACTGCTTTGATTAAGAAATATCCAAAACTTGAATCGGAGTTTGTCT
ATGGTGATTATAAAGTTTATGATGTTCGTAAAATGATTGCTAAGTCTGAGCAAGAAATAGGCAAA
GCAACCGCAAAATATTTCTTTTACTCTAATATCATGAACTTCTTCAAAACAGAAATTACACTTGCA
AATGGAGAGATTCGCAAACGCCCTCTAATCGAAACTAATGGGGAAACTGGAGAAATTGTCTGGGA
TAAAGGGCGAGATTTTGCCACAGTGCGCAAAGTATTGTCCATGCCCCAAGTCAATATTGTCAAGAA
AACAGAAGTACAGACAGGCGGATTCTCCAAGGAGTCAATTTTACCAAAAAGAAATTCGGACAAGC
TTATTGCTCGTAAAAAAGACTGGGATCCAAAAAAATATGGTGGTTTTGATAGTCCAACGGTAGCTT
ATTCAGTCCTAGTGGTTGCTAAGGTGGAAAAAGGGAAATCGAAGAAGTTAAAATCCGTTAAAGAG
TTACTAGGGATCACAATTATGGAAAGAAGTTCCTTTGAAAAAAATCCGATTGACTTTTTAGAAGCT
AAAGGATATAAGGAAGTTAAAAAAGACTTAATCATTAAACTACCTAAATATAGTCTTTTTGAGTTA
GAAAACGGTCGTAAACGGATGCTGGCTAGTGCCGGAGAATTACAAAAAGGAAATGAGCTGGCTCT
GCCAAGCAAATATGTGAATTTTTTATATTTAGCTAGTCATTATGAAAAGTTGAAGGGTAGTCCAGA
AGATAACGAACAAAAACAATTGTTTGTGGAGCAGCATAAGCATTATTTAGATGAGATTATTGAGC
AAATCAGTGAATTTTCTAAGCGTGTTATTTTAGCAGATGCCAATTTAGATAAAGTTCTTAGTGCAT
ATAACAAACATAGAGACAAACCAATACGTGAACAAGCAGAAAATATTATTCATTTATTTACGTTG
ACGAATCTTGGAGCTCCCGCTGCTTTTAAATATTTTGATACAACAATTGATCGTAAACGATATACG
TCTACAAAAGAAGTTTTAGATGCCACTCTTATCCATCAATCCATCACTGGTCTTTATGAAACACGC
ATTGATTTGAGTCAGCTAGGAGGTGACTGA (SEQ ID NO: 4)
Streptococcus pyogenes Cas9 (wild type) protein sequence
MDKKYSIGLDIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTAR
RRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLR
KKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDA
KAILS ARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDN
LLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEK
YKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHL
GELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGA
SAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFK
TNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILOTVKVVDELVKVMGRHKPENIVI
EMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLONGRDMYVDQEL
DINRLSDYDVDHIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQRK
FDNLTKAERGGLSELDKAGFIKROLVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSD
FRKDFOFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGKA
TAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVO 1GGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIME RSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLA SHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENI IHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO: 1) (single underline: HNH domain; double underline: RuvC domain)
[0075] In some embodiments, wild type Cas9 corresponds to Cas9 from
Staphylococcus aureus (NCBI Reference Sequence: WP_001573634.1, SEQ ID NO: 5 (amino acid).
Staphylococcus aureus Cas9 (wild type) protein sequence
MKRNYILGLDIGITSVGYGIIDYETRDVIDAGVRLFKEANVENNEGRRSKRGARRLKRRRRHRIQRVKK
LLFDYNLLTDHSELSGINPYEARVKGLSQKLSEEEFSAALLHLAKRRGVHNVNEVEEDTGNELSTKEQI
SRNSKALEEKYVAELQLERLKKDGEVRGSINRFKTSDYVKEAKQLLKVQKAYHQLDQSFIDTYIDLLE
TRRTYYEGPGEGSPFGWKDIKEWYEMLMGHCTYFPEELRSVKYAYNADLYNALNDLNNLVITRDENE
KLEYYEKFQIIENVFKQKKKPTLKQIAKEILVNEEDIKGYRVTSTGKPEFTNLKVYHDIKDITARKEIIEN
AELLDQIAKILTIYQSSEDIQEELTNLNSELTQEEIEQISNLKGYTGTHNLSLKAINLILDELWHTNDNQIA
IFNRLKLVPKKVDLSQQKEIPTTLVDDFILSPVVKRSFIQSIKVINAIIKKYGLPNDIIIELAREKNSKDAQK
MINEMQKRNRQTNERIEEIIRTTGKENAKYLIEKIKLHDMQEGKCLYSLEAIPLEDLLNNPFNYEVDHIIP
RSVSFDNSFNNKVLVKQEENSKKGNRTPFQYLSSSDSKISYETFKKHILNLAKGKGRISKTKKEYLLEER
DINRFSVQKDFINRNLVDTRYATRGLMNLLRSYFRVNNLDVKVKSINGGFTSFLRRKWKFKKERNKGY
KHHAEDALIIANADFIFKEWKKLDKAKKVMENQMFEEKQAESMPEIETEQEYKEIFITPHQIKHIKDFK
DYKYSHRVDKKPNRELINDTLYSTRKDDKGNTLIVNNLNGLYDKDNDKLKKLINKSPEKLLMYHHDP
QTYQKLKLIMEQYGDEKNPLYKYYEETGNYLTKYSKKDNGPVIKKIKYYGNKLNAHLDITDDYPNSR
NKVVKLSLKPYRFDVYLDNGVYKFVTVKNLDVIKKENYYEVNSKCYEEAKKLKKISNQAEFIASFYNN
DLIKINGELYRVIGVNNDLLNRIEVNMIDITYREYLENMNDKRPPRIIKTIASKTQSIKKYSTDILGNLYE
VKSKKHPQIIKKG (SEQ ID NO: 5)
[0076] In some embodiments, wild type Cas9 corresponds to Cas9 from
Streptococcus pyogenes (NCBI Reference Sequence: NC_017053.1, SEQ ID NO: 679 (nucleotide); SEQ ID NO: 680 (amino acid)).
ATGGATAAGAAATACTCAATAGGCTTAGATATCGGCACAAATAGCGTCGGATGG
GCGGTGATCACTGATGATTATAAGGTTCCGTCTAAAAAGTTCAAGGTTCTGGGAA
ATACAGACCGCCACAGTATCAAAAAAAATCTTATAGGGGCTCTTTTATTTGGCAG
TGG AG AG AC AGC GG A AGC G ACTCGTCTC A A AC GG AC AGCTC GT AG A AGGT AT AC
ACGTCGGAAGAATCGTATTTGTTATCTACAGGAGATTTTTTCAAATGAGATGGCG
AAAGTAGATGATAGTTTCTTTCATCGACTTGAAGAGTCTTTTTTGGTGGAAGAAG
ACAAGAAGCATGAACGTCATCCTATTTTTGGAAATATAGTAGATGAAGTTGCTTA
TCATGAGAAATATCCAACTATCTATCATCTGCGAAAAAAATTGGCAGATTCTACT
GATAAAGCGGATTTGCGCTTAATCTATTTGGCCTTAGCGCATATGATTAAGTTTC
GTGGTCATTTTTTGATTGAGGGAGATTTAAATCCTGATAATAGTGATGTGGACAA
ACTATTTATCCAGTTGGTACAAATCTACAATCAATTATTTGAAGAAAACCCTATT
AACGCAAGTAGAGTAGATGCTAAAGCGATTCTTTCTGCACGATTGAGTAAATCA
AGACGATTAGAAAATCTCATTGCTCAGCTCCCCGGTGAGAAGAGAAATGGCTTG
TTTGGGAATCTCATTGCTTTGTCATTGGGATTGACCCCTAATTTTAAATCAAATTT
TGATTTGGCAGAAGATGCTAAATTACAGCTTTCAAAAGATACTTACGATGATGAT
TTAGATAATTTATTGGCGCAAATTGGAGATCAATATGCTGATTTGTTTTTGGCAG
CTAAGAATTTATCAGATGCTATTTTACTTTCAGATATCCTAAGAGTAAATAGTGA
AATAACTAAGGCTCCCCTATCAGCTTCAATGATTAAGCGCTACGATGAACATCAT
CAAGACTTGACTCTTTTAAAAGCTTTAGTTCGACAACAACTTCCAGAAAAGTATA
AAGAAATCTTTTTTGATCAATCAAAAAACGGATATGCAGGTTATATTGATGGGGG
AGCTAGCCAAGAAGAATTTTATAAATTTATCAAACCAATTTTAGAAAAAATGGAT
GGTACTGAGGAATTATTGGTGAAACTAAATCGTGAAGATTTGCTGCGCAAGCAA
CGGACCTTTGACAACGGCTCTATTCCCCATCAAATTCACTTGGGTGAGCTGCATG
CTATTTTGAGAAGACAAGAAGACTTTTATCCATTTTTAAAAGACAATCGTGAGAA
GATTGAAAAAATCTTGACTTTTCGAATTCCTTATTATGTTGGTCCATTGGCGCGTG
GCAATAGTCGTTTTGCATGGATGACTCGGAAGTCTGAAGAAACAATTACCCCATG
GAATTTTGAAGAAGTTGTCGATAAAGGTGCTTCAGCTCAATCATTTATTGAACGC
ATGACAAACTTTGATAAAAATCTTCCAAATGAAAAAGTACTACCAAAACATAGT
TTGCTTTATGAGTATTTTACGGTTTATAACGAATTGACAAAGGTCAAATATGTTA
CTGAGGGAATGCGAAAACCAGCATTTCTTTCAGGTGAACAGAAGAAAGCCATTG
TTGATTTACTCTTCAAAACAAATCGAAAAGTAACCGTTAAGCAATTAAAAGAAG
ATTATTTCAAAAAAATAGAATGTTTTGATAGTGTTGAAATTTCAGGAGTTGAAGA
TAGATTTAATGCTTCATTAGGCGCCTACCATGATTTGCTAAAAATTATTAAAGAT
AAAGATTTTTTGGATAATGAAGAAAATGAAGATATCTTAGAGGATATTGTTTTAA
CATTGACCTTATTTGAAGATAGGGGGATGATTGAGGAAAGACTTAAAACATATG
CTCACCTCTTTGATGATAAGGTGATGAAACAGCTTAAACGTCGCCGTTATACTGG
TTGGGGACGTTTGTCTCGAAAATTGATTAATGGTATTAGGGATAAGCAATCTGGC
AAAACAATATTAGATTTTTTGAAATCAGATGGTTTTGCCAATCGCAATTTTATGC
AGCTGATCCATGATGATAGTTTGACATTTAAAGAAGATATTCAAAAAGCACAGG
TGTCTGGACAAGGCCATAGTTTACATGAACAGATTGCTAACTTAGCTGGCAGTCC
TGCTATTAAAAAAGGTATTTTACAGACTGTAAAAATTGTTGATGAACTGGTCAAA
GTAATGGGGCATAAGCCAGAAAATATCGTTATTGAAATGGCACGTGAAAATCAG
ACAACTCAAAAGGGCCAGAAAAATTCGCGAGAGCGTATGAAACGAATCGAAGA
AGGTATCAAAGAATTAGGAAGTCAGATTCTTAAAGAGCATCCTGTTGAAAATAC
TCAATTGCAAAATGAAAAGCTCTATCTCTATTATCTACAAAATGGAAGAGACATG
TATGTGGACCAAGAATTAGATATTAATCGTTTAAGTGATTATGATGTCGATCACA
TTGTTCCACAAAGTTTCATTAAAGACGATTCAATAGACAATAAGGTACTAACGCG
TTCTGATAAAAATCGTGGTAAATCGGATAACGTTCCAAGTGAAGAAGTAGTCAA
AAAGATGAAAAACTATTGGAGACAACTTCTAAACGCCAAGTTAATCACTCAACG
TAAGTTTGATAATTTAACGAAAGCTGAACGTGGAGGTTTGAGTGAACTTGATAAA
GCTGGTTTTATCAAACGCCAATTGGTTGAAACTCGCCAAATCACTAAGCATGTGG
CACAAATTTTGGATAGTCGCATGAATACTAAATACGATGAAAATGATAAACTTAT
TCGAGAGGTTAAAGTGATTACCTTAAAATCTAAATTAGTTTCTGACTTCCGAAAA
GATTTCCAATTCTATAAAGTACGTGAGATTAACAATTACCATCATGCCCATGATG
CGTATCTAAATGCCGTCGTTGGAACTGCTTTGATTAAGAAATATCCAAAACTTGA
ATCGGAGTTTGTCTATGGTGATTATAAAGTTTATGATGTTCGTAAAATGATTGCT
AAGTCTGAGCAAGAAATAGGCAAAGCAACCGCAAAATATTTCTTTTACTCTAATA
TCATGAACTTCTTCAAAACAGAAATTACACTTGCAAATGGAGAGATTCGCAAAC
GCCCTCTAATCGAAACTAATGGGGAAACTGGAGAAATTGTCTGGGATAAAGGGC
GAGATTTTGCCACAGTGCGCAAAGTATTGTCCATGCCCCAAGTCAATATTGTCAA
GAAAACAGAAGTACAGACAGGCGGATTCTCCAAGGAGTCAATTTTACCAAAAAG
AAATTCGGACAAGCTTATTGCTCGTAAAAAAGACTGGGATCCAAAAAAATATGG
TGGTTTTGATAGTCCAACGGTAGCTTATTCAGTCCTAGTGGTTGCTAAGGTGGAA
AAAGGGAAATCGAAGAAGTTAAAATCCGTTAAAGAGTTACTAGGGATCACAATT
ATGGAAAGAAGTTCCTTTGAAAAAAATCCGATTGACTTTTTAGAAGCTAAAGGAT
ATAAGGAAGTTAAAAAAGACTTAATCATTAAACTACCTAAATATAGTCTTTTTGA
GTTAGAAAACGGTCGTAAACGGATGCTGGCTAGTGCCGGAGAATTACAAAAAGG
AAATGAGCTGGCTCTGCCAAGCAAATATGTGAATTTTTTATATTTAGCTAGTCAT
TATGAAAAGTTGAAGGGTAGTCCAGAAGATAACGAACAAAAACAATTGTTTGTG
GAGCAGCATAAGCATTATTTAGATGAGATTATTGAGCAAATCAGTGAATTTTCTA
AGCGTGTTATTTTAGCAGATGCCAATTTAGATAAAGTTCTTAGTGCATATAACAA
ACATAGAGACAAACCAATACGTGAACAAGCAGAAAATATTATTCATTTATTTAC
GTTGACGAATCTTGGAGCTCCCGCTGCTTTTAAATATTTTGATACAACAATTGATC
GTAAACGATATACGTCTACAAAAGAAGTTTTAGATGCCACTCTTATCCATCAATC
CATCACTGGTCTTTATGAAACACGCATTGATTTGAGTCAGCTAGGAGGTGACTGA
(SEQ ID NO: 679)
MDKKYS IGLDIGTNS VGW A VITDD YKVPS KKFKVLGNTDRHS IKKNLIG ALLFGS GE
1AEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHE
RHPIFGNIVDEVAYHEKYPTIYHLRKKLADSTDKADLRLIYLALAHMIKFRGHFLIEG
DLNPDNSDVDKLFIQLVQIYNQLFEENPINASRVDAKAILSARLSKSRRLENLIAQLPG
EKRNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYAD
LFLA AKNLS D AILLS DILRVNS EITKAPLS AS MIKR YDEHHQDLTLLKALVRQQLPEK
YKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRT
FDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKffiKILTFRIPYYVGPLARGNSRFA
WMTRKS EETITPWNFEE V VDKG AS AQS FIERMTNFDKNLPNEK VLPKHS LLYE YFT V
YNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFD
SVEISGVEDRFNASLGAYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDRGMIEER
LKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANR
NFMOLIHDDSLTFKEDIOKAOVSGOGHSLHEOIANLAGSPAIKKGILOTVKIVDELVK
VMGHKPENIVIEMARENOTTOKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQ
NEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFIKDDSIDNKVLTRSDKNR
GKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQ
LVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFOFYKVREI
NNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKAT
AKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPO
VNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAK
VEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFELE
NGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHK
HYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPA
AFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO: 680)
(single underline: HNH domain; double underline: RuvC domain)
[0077] In some embodiments, wild type Cas9 corresponds to, or comprises,
Streptococcus pyogenes Cas9 (SEQ ID NO: 681 (nucleotide) and/or SEQ ID NO: 682 (amino acid)):
ATGGATAAAAAGTATTCTATTGGTTTAGACATCGGCACTAATTCCGTTGGATGGG
CTGTCATAACCGATGAATACAAAGTACCTTCAAAGAAATTTAAGGTGTTGGGGA
ACACAGACCGTCATTCGATTAAAAAGAATCTTATCGGTGCCCTCCTATTCGATAG
TGGCGAAACGGCAGAGGCGACTCGCCTGAAACGAACCGCTCGGAGAAGGTATAC
ACGTCGCAAGAACCGAATATGTTACTTACAAGAAATTTTTAGCAATGAGATGGCC
AAAGTTGACGATTCTTTCTTTCACCGTTTGGAAGAGTCCTTCCTTGTCGAAGAGG
ACAAGAAACATGAACGGCACCCCATCTTTGGAAACATAGTAGATGAGGTGGCAT
ATCATGAAAAGTACCCAACGATTTATCACCTCAGAAAAAAGCTAGTTGACTCAA
CTGATAAAGCGGACCTGAGGTTAATCTACTTGGCTCTTGCCCATATGATAAAGTT
CCGTGGGCACTTTCTCATTGAGGGTGATCTAAATCCGGACAACTCGGATGTCGAC
AAACTGTTCATCCAGTTAGTACAAACCTATAATCAGTTGTTTGAAGAGAACCCTA
TAAATGCAAGTGGCGTGGATGCGAAGGCTATTCTTAGCGCCCGCCTCTCTAAATC
CCGACGGCTAGAAAACCTGATCGCACAATTACCCGGAGAGAAGAAAAATGGGTT
GTTCGGTAACCTTATAGCGCTCTCACTAGGCCTGACACCAAATTTTAAGTCGAAC
TTCGACTTAGCTGAAGATGCCAAATTGCAGCTTAGTAAGGACACGTACGATGAC
GATCTCGACAATCTACTGGCACAAATTGGAGATCAGTATGCGGACTTATTTTTGG
CTGCCAAAAACCTTAGCGATGCAATCCTCCTATCTGACATACTGAGAGTTAATAC
TGAGATTACCAAGGCGCCGTTATCCGCTTCAATGATCAAAAGGTACGATGAACAT
CACCAAGACTTGACACTTCTCAAGGCCCTAGTCCGTCAGCAACTGCCTGAGAAAT
ATAAGGAAATATTCTTTGATCAGTCGAAAAACGGGTACGCAGGTTATATTGACG
GCGGAGCGAGTCAAGAGGAATTCTACAAGTTTATCAAACCCATATTAGAGAAGA
TGGATGGGACGGAAGAGTTGCTTGTAAAACTCAATCGCGAAGATCTACTGCGAA
AGCAGCGGACTTTCGACAACGGTAGCATTCCACATCAAATCCACTTAGGCGAATT
GCATGCTATACTTAGAAGGCAGGAGGATTTTTATCCGTTCCTCAAAGACAATCGT
GAAAAGATTGAGAAAATCCTAACCTTTCGCATACCTTACTATGTGGGACCCCTGG
CCCGAGGGAACTCTCGGTTCGCATGGATGACAAGAAAGTCCGAAGAAACGATTA
CTCCATGGAATTTTGAGGAAGTTGTCGATAAAGGTGCGTCAGCTCAATCGTTCAT
CGAGAGGATGACCAACTTTGACAAGAATTTACCGAACGAAAAAGTATTGCCTAA
GCACAGTTTACTTTACGAGTATTTCACAGTGTACAATGAACTCACGAAAGTTAAG
TATGTCACTGAGGGCATGCGTAAACCCGCCTTTCTAAGCGGAGAACAGAAGAAA
GCAATAGTAGATCTGTTATTCAAGACCAACCGCAAAGTGACAGTTAAGCAATTG
AAAGAGGACTACTTTAAGAAAATTGAATGCTTCGATTCTGTCGAGATCTCCGGGG
TAGAAGATCGATTTAATGCGTCACTTGGTACGTATCATGACCTCCTAAAGATAAT
TAAAGATAAGGACTTCCTGGATAACGAAGAGAATGAAGATATCTTAGAAGATAT
AGTGTTGACTCTTACCCTCTTTGAAGATCGGGAAATGATTGAGGAAAGACTAAAA
ACATACGCTCACCTGTTCGACGATAAGGTTATGAAACAGTTAAAGAGGCGTCGCT
ATACGGGCTGGGGACGATTGTCGCGGAAACTTATCAACGGGATAAGAGACAAGC
AAAGTGGTAAAACTATTCTCGATTTTCTAAAGAGCGACGGCTTCGCCAATAGGAA
CTTTATGCAGCTGATCCATGATGACTCTTTAACCTTCAAAGAGGATATACAAAAG
GCACAGGTTTCCGGACAAGGGGACTCATTGCACGAACATATTGCGAATCTTGCTG
GTTCGCCAGCCATCAAAAAGGGCATACTCCAGACAGTCAAAGTAGTGGATGAGC
TAGTTAAGGTCATGGGACGTCACAAACCGGAAAACATTGTAATCGAGATGGCAC
GCGAAAATCAAACGACTCAGAAGGGGCAAAAAAACAGTCGAGAGCGGATGAAG
AGAATAGAAGAGGGTATTAAAGAACTGGGCAGCCAGATCTTAAAGGAGCATCCT
GTGGAAAATACCCAATTGCAGAACGAGAAACTTTACCTCTATTACCTACAAAATG
GAAGGGACATGTATGTTGATCAGGAACTGGACATAAACCGTTTATCTGATTACGA
CGTCGATCACATTGTACCCCAATCCTTTTTGAAGGACGATTCAATCGACAATAAA
GTGCTTACACGCTCGGATAAGAACCGAGGGAAAAGTGACAATGTTCCAAGCGAG
GAAGTCGTAAAGAAAATGAAGAACTATTGGCGGCAGCTCCTAAATGCGAAACTG
ATAACGCAAAGAAAGTTCGATAACTTAACTAAAGCTGAGAGGGGTGGCTTGTCT
GAACTTGACAAGGCCGGATTTATTAAACGTCAGCTCGTGGAAACCCGCCAAATC
ACAAAGCATGTTGCACAGATACTAGATTCCCGAATGAATACGAAATACGACGAG
AACGATAAGCTGATTCGGGAAGTCAAAGTAATCACTTTAAAGTCAAAATTGGTG
TCGGACTTCAGAAAGGATTTTCAATTCTATAAAGTTAGGGAGATAAATAACTACC
ACCATGCGCACGACGCTTATCTTAATGCCGTCGTAGGGACCGCACTCATTAAGAA
ATACCCGAAGCTAGAAAGTGAGTTTGTGTATGGTGATTACAAAGTTTATGACGTC
CGTAAGATGATCGCGAAAAGCGAACAGGAGATAGGCAAGGCTACAGCCAAATA
CTTCTTTTATTCTAACATTATGAATTTCTTTAAGACGGAAATCACTCTGGCAAACG
GAGAGATACGCAAACGACCTTTAATTGAAACCAATGGGGAGACAGGTGAAATCG
TATGGGATAAGGGCCGGGACTTCGCGACGGTGAGAAAAGTTTTGTCCATGCCCC
AAGTCAACATAGTAAAGAAAACTGAGGTGCAGACCGGAGGGTTTTCAAAGGAAT
CGATTCTTCCAAAAAGGAATAGTGATAAGCTCATCGCTCGTAAAAAGGACTGGG
ACCCGAAAAAGTACGGTGGCTTCGATAGCCCTACAGTTGCCTATTCTGTCCTAGT
AGTGGCAAAAGTTGAGAAGGGAAAATCCAAGAAACTGAAGTCAGTCAAAGAAT
TATTGGGGATAACGATTATGGAGCGCTCGTCTTTTGAAAAGAACCCCATCGACTT
CCTTGAGGCGAAAGGTTACAAGGAAGTAAAAAAGGATCTCATAATTAAACTACC
AAAGTATAGTCTGTTTGAGTTAGAAAATGGCCGAAAACGGATGTTGGCTAGCGC
CGGAGAGCTTCAAAAGGGGAACGAACTCGCACTACCGTCTAAATACGTGAATTT
CCTGTATTTAGCGTCCCATTACGAGAAGTTGAAAGGTTCACCTGAAGATAACGAA
CAGAAGCAACTTTTTGTTGAGCAGCACAAACATTATCTCGACGAAATCATAGAGC
AAATTTCGGAATTCAGTAAGAGAGTCATCCTAGCTGATGCCAATCTGGACAAAGT
ATTAAGCGCATACAACAAGCACAGGGATAAACCCATACGTGAGCAGGCGGAAA
ATATTATCCATTTGTTTACTCTTACCAACCTCGGCGCTCCAGCCGCATTCAAGTAT
TTTGACACAACGATAGATCGCAAACGATACACTTCTACCAAGGAGGTGCTAGAC
GCGACACTGATTCACCAATCCATCACGGGATTATATGAAACTCGGATAGATTTGT
CACAGCTTGGGGGTGACGGATCCCCCAAGAAGAAGAGGAAAGTCTCGAGCGACT
ACAAAGACCATGACGGTGATTATAAAGATCATGACATCGATTACAAGGATGACG
ATGACAAGGCTGCAGGA (SEQ ID NO: 681)
MDKKYS IGLAIGTNS VGW A VITDE YK VPS KKFKVLGNTDRHS IKKNLIG ALLFDS GE
1AEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHE
RHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEG
DLNPDNS D VDKLFIQLVQT YNQLFEENPIN AS G VD AKAILS ARLS KS RRLENLIAQLP
GEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYA
DLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPE
KYKEIFFDQS KNGYAGYIDGGAS QEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQR
TFDNGS IPHQIHLGELH AILRRQEDF YPFLKDNREKIEKILTFRIP Y Y VGPLARGNS RF A
WMTRKS EETITPWNFEE V VDKG AS AQS FIERMTNFDKNLPNEK VLPKHS LLYE YFT V
YNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFD
SVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERL
KTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMQLIHDDS LTFKEDIQKAQ VS GQGDS LHEHIANLAGSPAIKKGILQT VKVVDELVK
VMGRHKPENIVIEMARENOTTOKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQL
QNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDK
NRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIK
RQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKV
REINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGK
ATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSM
POVNIVKKTEVOTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVV
AKVEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFE
LENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQ HKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGA PAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO: 682) (single underline: HNH domain; double underline: RuvC domain)
[0078] In some embodiments, Cas9 refers to Cas9 from: Corynebacterium ulcerans
(NCBI Refs: NC_015683.1, NC_017317.1); Corynebacterium diphtheria (NCBI Refs:
NC 016782.1, NC_016786.1); Spiroplasma syrphidicola (NCBI Ref: NC_021284.1);
Prevotella intermedia (NCBI Ref: NC_017861.1); Spiroplasma taiwanense (NCBI Ref: NC_021846.1); Streptococcus iniae (NCBI Ref: NC_021314.1); Belliella baltica (NCBI Ref: NC_018010.1); Psychroflexus torquisl (NCBI Ref: NC_018721.1); Streptococcus thermophilus (NCBI Ref: YP_820832.1), Listeria innocua (NCBI Ref: NP_472073.1), Campylobacter jejuni (NCBI Ref: YP_002344900.1) ox Neisseria, meningitidis (NCBI Ref: YP_002342100.1) or to a Cas9 from any of the organisms listed in Example 1 (SEQ ID NOs: 1-260, 270-292 or 315-323).
[0079] In some embodiments, proteins comprising fragments of Cas9 are provided.
For example, in some embodiments, a protein comprises one of two Cas9 domains: (1) the gRNA binding domain of Cas9; or (2) the DNA cleavage domain of Cas9. In some embodiments, proteins comprising Cas9 or fragments thereof are referred to as "Cas9 variants." A Cas9 variant shares homology to Cas9, or a fragment thereof. For example, a Cas9 variant is at least about 70% identical, at least about 80% identical, at least about 90% identical, at least about 95% identical, at least about 96% identical, at least about 97% identical, at least about 98% identical, at least about 99% identical, at least about 99.5% identical, or at least about 99.9% identical to wild type Cas9. In some embodiments, the Cas9 variant may have 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 21, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50 or more amino acid changes compared to wild type Cas9. In some
embodiments, the Cas9 variant comprises a fragment of Cas9 {e.g., a gRNA binding domain or a DNA-cleavage domain), such that the fragment is at least about 70% identical, at least about 80% identical, at least about 90% identical, at least about 95% identical, at least about 96% identical, at least about 97% identical, at least about 98% identical, at least about 99% identical, at least about 99.5% identical, or at least about 99.9% identical to the corresponding fragment of wild type Cas9. In some embodiments, the fragment is is at least 30%, at least 35%, at least 40%, at least 45%, at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95% identical, at least
96%, at least 97%, at least 98%, at least 99%, or at least 99.5% of the amino acid length of a corresponding wild type Cas9.
[0080] In some embodiments, the fragment is at least 100 amino acids in length. In some embodiments, the fragment is at least 100, at least 150, at least 200, at least 250, at least 300, at least 350, at least 400, at least 450, at least 500, at least 550, at least 600, at least 650, at least 700, at least 750, at least 800, at least 850, at least 900, at least 950, at least 1000, at least 1050, at least 1100, at least 1150, at least 1200, at least 1250, or at least 1300 amino acids in length.
[0081] To be used as in the fusion protein of the present disclosure as the guide nucleotide sequence-programmable DNA binding protein domain, a Cas9 protein typically needs to be nuclease inactive. A nuclease-inactive Cas9 protein may interchangeably be referred to as a "dCas9" protein (for nuclease-"dead" Cas9). Methods for generating a Cas9 protein (or a fragment thereof) having an inactive DNA cleavage domain are known (See, e.g., Tmek et al, Science. 337:816-821(2012); Qi et al, (2013) Cell. 28; 152(5): 1173- 83, which is incorporated herein by reference). For example, the DNA cleavage domain of Cas9 is known to include two subdomains, the HNH nuclease subdomain and the RuvCl subdomain. The HNH subdomain cleaves the strand complementary to the gRNA, whereas the RuvCl subdomain cleaves the non-complementary strand. Mutations within these subdomains can silence the nuclease activity of Cas9. For example, the mutations D10A and H840A completely inactivate the nuclease activity of S. pyogenes Cas9 (Jinek et ah, Science. 337:816-821(2012); Qi et al, Cell. 28;152(5): 1173-83 (2013)).
S. pyogenes dCas9 (D10A and H840A)
MDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTAR
RRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLR
KKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDA
KAILS ARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDN
LLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEK
YKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHL
GELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGA
SAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFK
TNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILOTVKVVDELVKVMGRHKPENIVI
EMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLONGRDMYVDQEL
DINRLSDYDVDAIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQRK
FDNLTKAERGGLSELDKAGFIKROLVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSD FRKDFOFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGKA TAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVO
1GGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIME RSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLA SHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENI IHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRI (SEQ ID NO: 2) (single underline: HNH domain; double underline: RuvC domain).
[0082] The dCas9 of the present disclosure encompasses completely inactive Cas9 or partially inactive Cas9. For example, the dCas9 may have one of the two nuclease domain inactivated, while the other nuclease domain remains active. Such a partially active Cas9 may also be referred to as a Cas9 nickase, due to its ability to cleave one strand of the targeted DNA sequence. The Cas9 nickase suitable for use in accordance with the present disclosure has an active HNH domain and an inactive RuvC domain and is able to cleave only the strand of the target DNA that is bound by the sgRNA (which is the opposite strand of the strand that is being edited via deamination). The Cas9 nickase of the present disclosure may comprise mutations that inactivate the RuvC domain, e.g., a D10A mutation. It is to be understood that any mutation that inactivates the RuvC domain may be included in a Cas9 nickase, e.g., insertion, deletion, or single or multiple amino acid substitution in the RuvC domain. In a Cas9 nickase described herein, while the RuvC domain is inactivated, the HNH domain remains active. Thus, while the Cas9 nickase may comprise mutations other than those that inactivate the RuvC domain (e.g., D10A), those mutations do not affect the activity of the HNH domain. In a non-limiting Cas9 nickase example, the histidine at position 840 remains unchanged. The sequence of exemplary Cas9 nickases suitable for the present disclosure is provided below.
S. pyogenes Cas9 Nickase (D10A)
MDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTAR
RRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLR
KKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDA
KAILS ARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDN
LLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEK
YKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHL
GELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGA
SAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFK
TNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILOTVKVVDELVKVMGRHKPENIVI
EMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLONGRDMYVDQEL
DINRLSDYDVDHIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQRK
FDNLTKAERGGLSELDKAGFIKROLVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSD
FRKDFOFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGKA
TAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVO
1GGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIME
RSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLA
SHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENI
IHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
3) (single underline: HNH domain; double underline: RuvC domain)
S. aureus Cas9 Nickase (D10A)
MKRNYILGLDIGITSVGYGIIDYETRDVIDAGVRLFKEANVENNEGRRSKRGARRLKRRRRHRIQRVKK
LLFDYNLLTDHSELSGINPYEARVKGLSQKLSEEEFSAALLHLAKRRGVHNVNEVEEDTGNELSTKEQI
SRNSKALEEKYVAELQLERLKKDGEVRGSINRFKTSDYVKEAKQLLKVQKAYHQLDQSFIDTYIDLLE
TRRTYYEGPGEGSPFGWKDIKEWYEMLMGHCTYFPEELRSVKYAYNADLYNALNDLNNLVITRDENE
KLEYYEKFQIIENVFKQKKKPTLKQIAKEILVNEEDIKGYRVTSTGKPEFTNLKVYHDIKDITARKEIIEN
AELLDQIAKILTIYQSSEDIQEELTNLNSELTQEEIEQISNLKGYTGTHNLSLKAINLILDELWHTNDNQIA
IFNRLKLVPKKVDLSQQKEIPTTLVDDFILSPVVKRSFIQSIKVINAIIKKYGLPNDIIIELAREKNSKDAQK
MINEMQKRNRQTNERIEEIIRTTGKENAKYLIEKIKLHDMQEGKCLYSLEAIPLEDLLNNPFNYEVDHIIP
RSVSFDNSFNNKVLVKQEENSKKGNRTPFQYLSSSDSKISYETFKKHILNLAKGKGRISKTKKEYLLEER
DINRFSVQKDFINRNLVDTRYATRGLMNLLRSYFRVNNLDVKVKSINGGFTSFLRRKWKFKKERNKGY
KHHAEDALIIANADFIFKEWKKLDKAKKVMENQMFEEKQAESMPEIETEQEYKEIFITPHQIKHIKDFK
DYKYSHRVDKKPNRELINDTLYSTRKDDKGNTLIVNNLNGLYDKDNDKLKKLINKSPEKLLMYHHDP
QTYQKLKLIMEQYGDEKNPLYKYYEETGNYLTKYSKKDNGPVIKKIKYYGNKLNAHLDITDDYPNSR
NKVVKLSLKPYRFDVYLDNGVYKFVTVKNLDVIKKENYYEVNSKCYEEAKKLKKISNQAEFIASFYNN
DLIKINGELYRVIGVNNDLLNRIEVNMIDITYREYLENMNDKRPPRIIKTIASKTQSIKKYSTDILGNLYE
VKSKKHPQiiKKG (SEQ ID NO: 6)
[0083] The targeting range of base editors was further expanded by applying recently engineered Cas9 variants that expand or alter PAM specificities. Joung and coworkers recently reported three SpCas9 mutants that accept NGA (VQR-Cas9), NGAG (EQR-Cas9), or NGCG(VRER-Cas9) PAM sequences (see: Kleinstiver, B. P. et al. Engineered CRISPR- Cas9 nucleases with altered PAM specificities. Nature 523, 481-485; 2015, which is herein incorporated by reference in its entirety). In addition, Joung and coworkers engineered a
SaCas9 variant containing three mutations (SaKKH-Cas9) that relax its PAM requirement to NNNRRT (see: Kleinstiver, B. P. et al. Broadening the targeting range of Staphylococcus aureus CRISPR-Cas9 by modifying PAM recognition. Nat. Biotechnol. 33, 1293-1298; 2015, which is herein incorporated by reference in its entirety).
 LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILOTVKVVDELVKVMGRHKPENIVI
EMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLONGRDMYVDQEL
DINRLSDYDVDHIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQRK
FDNLTKAERGGLSELDKAGFIKROLVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSD
FRKDFOFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGKA
TAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVO
1GGFSKESILPKRNSDKLIARKKDWDPKKYGGFVSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIME
RSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASARELQKGNELALPSKYVNFLYLA
SHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENI
IHLFTLTNLGAPAAFKYFDTTIDRKEYRSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
8) (single underline: HNH domain; double underline: RuvC domain)
VQR-Cas9 (D1135V/R1335Q/T1337R) S. pyogenes Cas9
MDKKYSIGLDIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTAR
RRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLR
KKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDA
KAILS ARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDN
LLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEK
YKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHL
GELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGA
SAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFK
TNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILOTVKVVDELVKVMGRHKPENIVI
EMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLONGRDMYVDQEL
DINRLSDYDVDHIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQRK
FDNLTKAERGGLSELDKAGFIKROLVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSD
FRKDFOFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGKA
TAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVO
1GGFSKESILPKRNSDKLIARKKDWDPKKYGGFVSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIME
RSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLA
SHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENI
IHLFTLTNLGAPAAFKYFDTTIDRKQYRSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
9) (single underline: HNH domain; double underline: RuvC domain)
VQR-nCas9 (D10A/D1135V/R1335Q/T1337R) S. pyogenes Cas9 Nickase
MDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTAR
RRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLR
KKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDA
KAILS ARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDN
LLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEK
YKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHL
GELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGA
SAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFK
TNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILOTVKVVDELVKVMGRHKPENIVI
EMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLONGRDMYVDQEL
DINRLSDYDVDHIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQRK
FDNLTKAERGGLSELDKAGFIKROLVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSD
FRKDFOFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGKA
TAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVO
1GGFSKESILPKRNSDKLIARKKDWDPKKYGGFVSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIME
RSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLA
SHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENI
IHLFTLTNLGAPAAFKYFDTTIDRKQYRSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
315) (single underline: HNH domain; double underline: RuvC domain)
EQR-Cas9 (D1135E/R1335Q/T1337R) S. pyogenes Cas9
MDKKYSIGLDIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTAR
RRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLR
KKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDA
KAILS ARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDN
LLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEK
YKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHL
GELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGA
SAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFK
TNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILOTVKVVDELVKVMGRHKPENIVI
EMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLONGRDMYVDQEL
DINRLSDYDVDHIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQRK
FDNLTKAERGGLSELDKAGFIKROLVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSD
FRKDFOFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGKA
TAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVO
1GGFSKESILPKRNSDKLIARKKDWDPKKYGGFESPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIME
RSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLA
SHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENI IHLFTLTNLGAPAAFKYFDTTIDRKQYRSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
316) (single underline: HNH domain; double underline: RuvC domain)
EQR-nCas9 (D10A/D1135E/R1335Q/T1337R) S. pyogenes Cas9 Nickase
MDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTAR
RRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLR
KKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDA
KAILS ARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDN
LLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEK
YKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHL
GELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGA
SAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFK
TNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILOTVKVVDELVKVMGRHKPENIVI
EMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLONGRDMYVDQEL
DINRLSDYDVDHIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQRK
FDNLTKAERGGLSELDKAGFIKROLVETROITKHVAOILDSRMNTKYDENDKLIREVKVITLKSKLVSD
FRKDFOFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEOEIGKA
TAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVO
1GGFSKESILPKRNSDKLIARKKDWDPKKYGGFESPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIME
RSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLA
SHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENI
IHLFTLTNLGAPAAFKYFDTTIDRKQYRSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
317) (single underline: HNH domain; double underline: RuvC domain)
[0084] Further variants of Cas9 from S. aureus and S. thermophilius may also be used in the contemplated methods and compositions described herein.
KKH variant (E782K/N968K/R1015H) S. aureus Cas9
MKRNYILGLDIGITSVGYGIIDYETRDVIDAGVRLFKEANVENNEGRRSKRGARRLKR
RRRHRIQRVKKLLFDYNLLTDHSELSGINPYEARVKGLSQKLSEEEFSAALLHLAKRR
GVHNVNEVEEDTGNELSTKEQISRNSKALEEKYVAELQLERLKKDGEVRGSINRFKT
SDYVKEAKQLLKVQKAYHQLDQSFIDTYIDLLETRRTYYEGPGEGSPFGWKDIKEW
YEMLMGHCTYFPEELRSVKYAYNADLYNALNDLNNLVITRDENEKLEYYEKFQIIEN
VFKQKKKPTLKQIAKEILVNEEDIKGYRVTSTGKPEFTNLKVYHDIKDITARKEIIENA
ELLDQIAKILTIYQSSEDIQEELTNLNSELTQEEIEQISNLKGYTGTHNLSLKAINLILDE
LWHTNDNQIAIFNRLKLVPKKVDLS QQKEIPTTLVDDFILS P V VKRS FIQS IKVIN AIIK
KYGLPNDIIIELAREKNSKDAQKMINEMQKRNRQTNERIEEIIRTTGKENAKYLIEKIK
LHDMQEGKCLYSLEAIPLEDLLNNPFNYEVDHIIPRSVSFDNSFNNKVLVKQEENSKK
GNRTPFQYLSSSDSKISYETFKKHILNLAKGKGRISKTKKEYLLEERDINRFSVQKDFI
NRNLVDTRYATRGLMNLLRSYFRVNNLDVKVKSINGGFTSFLRRKWKFKKERNKG
YKHHAEDALIIANADFIFKEWKKLDKAKKVMENQMFEEKQAESMPEIETEQEYKEIF
ITPHQIKHIKDFKDYKYSHRVDKKPNRKLINDTLYSTRKDDKGNTLIVNNLNGLYDK
DNDKLKKLINKSPEKLLMYHHDPQTYQKLKLIMEQYGDEKNPLYKYYEETGNYLTK
YSKKDNGPVIKKIKYYGNKLNAHLDITDDYPNSRNKVVKLSLKPYRFDVYLDNGVY
KFVTVKNLDVIKKENYYEVNSKCYEEAKKLKKISNQAEFIASFYKNDLIKINGELYRV
IGVNNDLLNRIEVNMIDITYREYLENMNDKRPPHIIKTIASKTQSIKKYSTDILGNLYE
VKS KKHPQIIKKG (SEQ ID NO: 318)
KKH variant (D10A/E782K/N968K/R1015H) S. aureus Cas9 Nickase
MKRNYILGLAIGITSVGYGIIDYETRDVIDAGVRLFKEANVENNEGRRSKRGARRLKR
RRRHRIQRVKKLLFDYNLLTDHSELSGINPYEARVKGLSQKLSEEEFSAALLHLAKRR
GVHNVNEVEEDTGNELSTKEQISRNSKALEEKYVAELQLERLKKDGEVRGSINRFKT
SDYVKEAKQLLKVQKAYHQLDQSFIDTYIDLLETRRTYYEGPGEGSPFGWKDIKEW
YEMLMGHCTYFPEELRSVKYAYNADLYNALNDLNNLVITRDENEKLEYYEKFQIIEN
VFKQKKKPTLKQIAKEILVNEEDIKGYRVTSTGKPEFTNLKVYHDIKDITARKEIIENA
ELLDQIAKILTIYQSSEDIQEELTNLNSELTQEEIEQISNLKGYTGTHNLSLKAINLILDE
LWHTNDNQIAIFNRLKLVPKKVDLS QQKEIPTTLVDDFILS P V VKRS FIQS IKVIN AIIK
KYGLPNDIIIELAREKNSKDAQKMINEMQKRNRQTNERIEEIIRTTGKENAKYLIEKIK
LHDMQEGKCLYSLEAIPLEDLLNNPFNYEVDHIIPRSVSFDNSFNNKVLVKQEENSKK
GNRTPFQYLSSSDSKISYETFKKHILNLAKGKGRISKTKKEYLLEERDINRFSVQKDFI
NRNLVDTRYATRGLMNLLRSYFRVNNLDVKVKSINGGFTSFLRRKWKFKKERNKG
YKHHAEDALIIANADFIFKEWKKLDKAKKVMENQMFEEKQAESMPEIETEQEYKEIF
ITPHQIKHIKDFKDYKYSHRVDKKPNRKLINDTLYSTRKDDKGNTLIVNNLNGLYDK
DNDKLKKLINKSPEKLLMYHHDPQTYQKLKLIMEQYGDEKNPLYKYYEETGNYLTK
YSKKDNGPVIKKIKYYGNKLNAHLDITDDYPNSRNKVVKLSLKPYRFDVYLDNGVY
KFVTVKNLDVIKKENYYEVNSKCYEEAKKLKKISNQAEFIASFYKNDLIKINGELYRV
IGVNNDLLNRIEVNMIDITYREYLENMNDKRPPHIIKTIASKTQSIKKYSTDILGNLYE
VKS KKHPQIIKKG (SEQ ID NO: 319)
Streptococcus thermophilus CRISPR1 Cas9 (StlCas9)
MSDLVLGLDIGIGSVGVGILNKVTGEIIHKNSRIFPAAQAENNLVRRTNRQGRRLTRR
KKHRRVRLNRLFEESGLITDFTKISINLNPYQLRVKGLTDELSNEELFIALKNMVKHR
GISYLDDASDDGNSSIGDYAQIVKENSKQLETKTPGQIQLERYQTYGQLRGDFTVEK
DGKKHRLINVFPTSAYRSEALRILQTQQEFNPQITDEFINRYLEILTGKRKYYHGPGNE
KSRTDYGRYRTSGETLDNIFGILIGKCTFYPDEFRAAKASYTAQEFNLLNDLNNLTVP
TETKKLSKEQKNQIINYVKNEKAMGPAKLFKYIAKLLSCDVADIKGYRIDKSGKAEI
HTFEAYRKMKTLETLDIEQMDRETLDKLAYVLTLNTEREGIQEALEHEFADGSFSQK
Q VDELVQFRKANS S IFGKGWHNFS VKLMMELIPELYETS EEQMTILTRLGKQKTTS S S
NKTKYIDEKLLTEEIYNPVVAKSVRQAIKIVNAAIKEYGDFDNIVIEMARETNEDDEK
KAIQKIQKANKDEKDAAMLKAANQYNGKAELPHSVFHGHKQLATKIRLWHQQGER
CLYTGKTISIHDLINNSNQFEVDHILPLSITFDDSLANKVLVYATANQEKGQRTPYQA
LDSMDDAWSFRELKAFVRESKTLSNKKKEYLLTEEDISKFDVRKKFIERNLVDTRYA
SRVVLNALQEHFRAHKIDTKVSVVRGQFTSQLRRHWGIEKTRDTYHHHAVDALIIAA
SSQLNLWKKQKNTLVSYSEDQLLDIETGELISDDEYKESVFKAPYQHFVDTLKSKEFE
DSILFSYQVDSKFNRKISDATIYATRQAKVGKDKADETYVLGKIKDIYTQDGYDAFM
KIYKKDKSKFLMYRHDPQTFEKVIEPILENYPNKQINEKGKEVPCNPFLKYKEEHGYI
RKYS KKGNGPEIKS LKY YDS KLGNHIDITPKDS NNKV VLQS VS PWRAD V YFNKTTG
KYEILGLKYADLQFEKGTGTYKISQEKYNDIKKKEGVDSDSEFKFTLYKNDLLLVKD
TETKEQQLFRFLSRTMPKQKHYVELKPYDKQKFEGGEALIKVLGNVANSGQCKKGL
GKSNISIYKVRTDVLGNQHIIKNEGDKPKLDF (SEQ ID NO: 320)
Streptococcus thermophilus CRISPR1 Cas9 (StlCas9) Nickase (D9A)
MSDLVLGLAIGIGSVGVGILNKVTGEIIHKNSRIFPAAQAENNLVRRTNRQGRRLTRR
KKHRRVRLNRLFEESGLITDFTKISINLNPYQLRVKGLTDELSNEELFIALKNMVKHR
GISYLDDASDDGNSSIGDYAQIVKENSKQLETKTPGQIQLERYQTYGQLRGDFTVEK
DGKKHRLINVFPTSAYRSEALRILQTQQEFNPQITDEFINRYLEILTGKRKYYHGPGNE
KSRTDYGRYRTSGETLDNIFGILIGKCTFYPDEFRAAKASYTAQEFNLLNDLNNLTVP
TETKKLSKEQKNQIINYVKNEKAMGPAKLFKYIAKLLSCDVADIKGYRIDKSGKAEI
HTFEAYRKMKTLETLDIEQMDRETLDKLAYVLTLNTEREGIQEALEHEFADGSFSQK
Q VDELVQFRKANS S IFGKGWHNFS VKLMMELIPELYETS EEQMTILTRLGKQKTTS S S
NKTKYIDEKLLTEEIYNPVVAKSVRQAIKIVNAAIKEYGDFDNIVIEMARETNEDDEK
KAIQKIQKANKDEKDAAMLKAANQYNGKAELPHSVFHGHKQLATKIRLWHQQGER
CLYTGKTISIHDLINNSNQFEVDHILPLSITFDDSLANKVLVYATANQEKGQRTPYQA
LDSMDDAWSFRELKAFVRESKTLSNKKKEYLLTEEDISKFDVRKKFIERNLVDTRYA
SRVVLNALQEHFRAHKIDTKVSVVRGQFTSQLRRHWGIEKTRDTYHHHAVDALIIAA
SSQLNLWKKQKNTLVSYSEDQLLDIETGELISDDEYKESVFKAPYQHFVDTLKSKEFE
DSILFSYQVDSKFNRKISDATIYATRQAKVGKDKADETYVLGKIKDIYTQDGYDAFM
KIYKKDKSKFLMYRHDPQTFEKVIEPILENYPNKQINEKGKEVPCNPFLKYKEEHGYI
RKYS KKGNGPEIKS LKY YDS KLGNHIDITPKDS NNKV VLQS VS PWRAD V YFNKTTG
KYEILGLKYADLQFEKGTGTYKISQEKYNDIKKKEGVDSDSEFKFTLYKNDLLLVKD
TETKEQQLFRFLSRTMPKQKHYVELKPYDKQKFEGGEALIKVLGNVANSGQCKKGL
GKSNISIYKVRTDVLGNQHIIKNEGDKPKLDF(SEQ ID NO: 321)
Streptococcus thermophilus CRISPR3Cas9 (St3Cas9)
MTKPYSIGLDIGTNSVGWAVITDNYKVPSKKMKVLGNTSKKYIKKNLLGVLLFDSGI
TAEGRRLKRTARRRYTRRRNRILYLQEIFSTEMATLDDAFFQRLDDSFLVPDDKRDS
KYPIFGNLVEEKVYHDEFPTIYHLRKYLADSTKKADLRLVYLALAHMIKYRGHFLIE
GEFNS KNNDIQKNFQDFLDT YNAIFESDLS LENS KQLEEIVKDKIS KLEKKDRILKLFP
GEKNSGIFSEFLKLIVGNQADFRKCFNLDEKASLHFSKESYDEDLETLLGYIGDDYSD
VFLKAKKLYD AILLS GFLT VTDNETE APLS S AMIKRYNEHKEDLALLKE YIRNIS LKT
YNEVFKDDTKNGYAGYIDGKTNQEDFYVYLKNLLAEFEGADYFLEKIDREDFLRKQ
RTFDNGSIPYQIHLQEMRAILDKQAKFYPFLAKNKERIEKILTFRIPYYVGPLARGNSD
FAWSIRKRNEKITPWNFEDVIDKESSAEAFINRMTSFDLYLPEEKVLPKHSLLYETFN
VYNELTKVRFIAESMRDYQFLDSKQKKDIVRLYFKDKRKVTDKDIIEYLHAIYGYDG
IELKGIEKQFNSSLSTYHDLLNIINDKEFLDDSSNEAIIEEIIHTLTIFEDREMIKQRLSKF
ENIFDKSVLKKLSRRHYTGWGKLSAKLINGIRDEKSGNTILDYLIDDGISNRNFMQLI
HDD ALS FKKKIQKAQIIGDED KGNIKE V VKS LPGS P AIKKGILQS IKIVDELVKVMGG
RKPES IV VEM ARENQ YTNQGKS NS QQRLKRLEKS LKELGS KILKENIP AKLS KIDNN A
LQNDRLYLYYLQNGKDMYTGDDLDIDRLSNYDIDHIIPQAFLKDNSIDNKVLVSSAS
NRGKSDDFPSLEVVKKRKTFWYQLLKSKLISQRKFDNLTKAERGGLLPEDKAGFIQR
QLVETRQITKHVARLLDEKFNNKKDENNRAVRTVKIITLKSTLVSQFRKDFELYKVR
EINDFHH AHD A YLN A VIAS ALLKKYPKLEPEF V YGD YPKYNS FRERKS ATEKV YF YS
NIMNIFKKSISLADGRVIERPLIEVNEETGESVWNKESDLATVRRVLSYPQVNVVKKV
EEQNHGLDRGKPKGLFN ANLS S KPKPNS NENLVG AKE YLDPKKYGG Y AGIS NS F A V
LVKGTIEKGAKKKITNVLEFQGISILDRINYRKDKLNFLLEKGYKDIELIIELPKYSLFE
LS DGS RRMLAS ILS TNNKRGEIHKGNQIFLS QKFVKLLYH AKRIS NTINENHRKY VEN
HKKEFEELFYYILEFNENYVGAKKNGKLLNSAFQSWQNHSIDELCSSFIGPTGSERKG LFELTSRGSAADFEFLGVKIPRYRDYTPSSLLKDATLIHQSVTGLYETRIDLAKLGEG
(SEQ ID NO: 322)
Streptococcus thermophilus CRISPR3Cas9 (St3Cas9) Nickase (D10A)
MTKPYSIGLAIGTNSVGWAVITDNYKVPSKKMKVLGNTSKKYIKKNLLGVLLFDSGI
TAEGRRLKRTARRRYTRRRNRILYLQEIFSTEMATLDDAFFQRLDDSFLVPDDKRDS
KYPIFGNLVEEKVYHDEFPTIYHLRKYLADSTKKADLRLVYLALAHMIKYRGHFLIE
GEFNS KNNDIQKNFQDFLDT YNAIFESDLS LENS KQLEEIVKDKIS KLEKKDRILKLFP
GEKNSGIFSEFLKLIVGNQADFRKCFNLDEKASLHFSKESYDEDLETLLGYIGDDYSD
VFLKAKKLYD AILLS GFLT VTDNETE APLS S AMIKRYNEHKEDLALLKE YIRNIS LKT
YNEVFKDDTKNGYAGYIDGKTNQEDFYVYLKNLLAEFEGADYFLEKIDREDFLRKQ
RTFDNGSIPYQIHLQEMRAILDKQAKFYPFLAKNKERIEKILTFRIPYYVGPLARGNSD
FAWSIRKRNEKITPWNFEDVIDKESSAEAFINRMTSFDLYLPEEKVLPKHSLLYETFN
VYNELTKVRFIAESMRDYQFLDSKQKKDIVRLYFKDKRKVTDKDIIEYLHAIYGYDG
IELKGIEKQFNSSLSTYHDLLNIINDKEFLDDSSNEAIIEEIIHTLTIFEDREMIKQRLSKF
ENIFDKSVLKKLSRRHYTGWGKLSAKLINGIRDEKSGNTILDYLIDDGISNRNFMQLI
HDD ALS FKKKIQKAQIIGDED KGNIKE V VKS LPGS P AIKKGILQS IKIVDELVKVMGG
RKPES IV VEM ARENQ YTNQGKS NS QQRLKRLEKS LKELGS KILKENIP AKLS KIDNN A
LQNDRLYLYYLQNGKDMYTGDDLDIDRLSNYDIDHIIPQAFLKDNSIDNKVLVSSAS
NRGKSDDFPSLEVVKKRKTFWYQLLKSKLISQRKFDNLTKAERGGLLPEDKAGFIQR
QLVETRQITKHVARLLDEKFNNKKDENNRAVRTVKIITLKSTLVSQFRKDFELYKVR
EINDFHH AHD A YLN A VIAS ALLKKYPKLEPEF V YGD YPKYNS FRERKS ATEKV YF YS
NIMNIFKKSISLADGRVIERPLIEVNEETGESVWNKESDLATVRRVLSYPQVNVVKKV
EEQNHGLDRGKPKGLFN ANLS S KPKPNS NENLVG AKE YLDPKKYGG Y AGIS NS F A V
LVKGTIEKGAKKKITNVLEFQGISILDRINYRKDKLNFLLEKGYKDIELIIELPKYSLFE
LS DGS RRMLAS ILS TNNKRGEIHKGNQIFLS QKFVKLLYH AKRIS NTINENHRKY VEN
HKKEFEELFYYILEFNENYVGAKKNGKLLNSAFQSWQNHSIDELCSSFIGPTGSERKG
LFELTSRGSAADFEFLGVKIPRYRDYTPSSLLKDATLIHQSVTGLYETRIDLAKLGEG
(SEQ ID NO: 323)
[0085] It is appreciated that when the term "dCas9" or "nuclease-inactive Cas9" is used herein, it refers to Cas9 variants that are inactive in both HNH and RuvC domains as well as Cas9 nickases. For example, the dCas9 used in the present disclosure may include the
amino acid sequence set forth in SEQ ID NO: 2 or SEQ ID NO: 3. In some embodiments, the dCas9 may comprise other mutations that inactivate RuvC or HNH domain. Additional suitable mutations that inactivate Cas9 will be apparent to those of skill in the art based on this disclosure and knowledge in the field, and are within the scope of this disclosure. Such additional exemplary suitable nuclease-inactive Cas9 domains include, but are not limited to, D839A and/or N863A (See, e.g., Prashant et al, Nature Biotechnology. 2013; 31(9): 833- 838, the entire contents of which are incorporated herein by reference), or K603R {See, e.g., Chavez et ah, Nature Methods 12, 326-328, 2015, the entire contents of which is
incorporated herein by reference). The term Cas9, dCas9, or Cas9 variant also encompasses Cas9, dCas9, or Cas9 variants from any organism. Also appreciated is that dCas9, Cas9 nickase, or other appropriate Cas9 variants from any organisms may be used in accordance with the present disclosure. In one example, the Cas9 variants used herein are the D10A variants of Cas9 from S. pyogenes or S. aureus.
[0086] A "deaminase" refers to an enzyme that catalyzes the removal of an amine group from a molecule, or deamination. In some embodiments, the deaminase is a cytidine deaminase, catalyzing the deamination of cytidine or deoxycytidine to uridine or
deoxyuridine, respectively. In some embodiments, the deaminase is a cytosine deaminase, catalyzing the hydrolytic deamination of cytosine to uracil {e.g., in RNA) or thymine {e.g., in DNA). In some embodiments, the deaminase is a naturally-occurring deaminase from an organism, such as a human, chimpanzee, gorilla, monkey, cow, dog, rat, or mouse. In some embodiments, the deaminase is a variant of a naturally-occurring deaminase from an organism, and the variant does not occur in nature. For example, in some embodiments, the deaminase or deaminase domain is at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75% at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to a naturally-occurring deaminase from an organism.
[0087] A "cytosine deaminase" refers to an enzyme that catalyzes the chemical reaction "cytosine + H20 f*uracil + NH3." As it may be apparent from the reaction formula, such chemical reactions result in a C to U/T nucleobase change. In the context of a gene, such nucleotide change, or mutation, may in turn lead to an amino acid change in the protein, which may affect the protein's function, e.g., loss-of-function or gain-of-function.
[0088] One exemplary suitable class of cytosine deaminases is the apolipoprotein B mRNA-editing complex (APOBEC) family of cytosine deaminases encompassing eleven proteins that serve to initiate mutagenesis in a controlled and beneficial manner. The
apolipoprotein B editing complex 3 (APOBEC3) enzyme provides protection to human cells against a certain HIV-1 strain via the deamination of cytosines in reverse-transcribed viral ssDNA. These cytosine deaminases all require a Zn2+-coordinating motif (H1S-X-GIU-X23-26- Pro-Cys-X2-4-Cys; SEQ ID NO: 324) and bound water molecule for catalytic activity. The glutamic acid residue acts to activate the water molecule to a zinc hydroxide for nucleophilic attack in the deamination reaction. Each family member preferentially deaminates at its own particular "hotspot," for example,WRC (W is A or T, R is A or G) for hAID, TTC for hAPOBEC3F. A recent crystal structure of the catalytic domain of APOBEC3G revealed a secondary structure comprising a five-stranded β-sheet core flanked by six a-helices, which is believed to be conserved across the entire family. The active center loops have been shown to be responsible for both ssDNA binding and in determining "hotspot" identity.
Overexpression of these enzymes has been linked to genomic instability and cancer, thus highlighting the importance of sequence-specific targeting. Another suitable cytosine deaminase is the activation-induced cytidine deaminase (AID), which is responsible for the maturation of antibodies by converting cytosines in ssDNA to uracils in a transcription- dependent, strand-biased fashion.
[0089] The term "base editors" or "nucleobase editors," as used herein, broadly refer to any of the fusion proteins described herein. In some embodiments, the nucleobase editors are capable of precisely deaminating a target base to convert it to a different base, e.g., the base editor may target C bases in a nucleic acid sequence and convert the C to a T. In some embodiments, the base editor comprises a Cas9 (e.g., dCas9 and nCas9), CasX, CasY, Cpfl, C2cl, C2c2, C2c3, or Argonaute protein fused to a cytidine deaminase. For example, in certain embodiments, the base editor may be a cytosine deaminase-dCas9 fusion protein. In some embodiments, the base editor may be a deaminase-dCas9-UGI fusion protein. In some embodiments, the base editor may be a APOBECl-dCas9-UGI fusion protein. In some embodiments, the base editor may be APOBECl-Cas9 nickase-UGI fusion protein. In some embodiments, the base editor may be APOBECl-dCpfl-UGI fusion protein. In some embodiments, the base editor may be APOBECl-dNgAgo-UGI fusion protein. In some embodiments, the base editor may be APOBECl-SpCas9 nickase-UGI fusion protein. In some embodiments, the base editor may be APOBEC1- SaCas9 nickase -UGI fusion protein. In some embodiments, the base editor comprises a CasX protein fused to a cytidine deaminase. In some embodiments, the base editor comprises a CasY protein fused to a cytidine deaminase. In some embodiments, the base editor comprises a Cpfl protein fused to a cytidine deaminase. In some embodiments, the base editor comprises a C2cl protein fused
to a cytidine deaminase. In some embodiments, the base editor comprises a C2c2 protein fused to a cytidine deaminase. In some embodiments, the base editor comprises a C2c3 protein fused to a cytidine deaminase. In some embodiments, the base editor comprises an Argonaute protein fused to a cytidine deaminase. In some embodiments, the fusion protein described herein comprises a Gam protein, a guide nucleotide sequence-programmable DNA binding protein, and a cytidine deaminase domain. In some embodiments, the base editor comprises a Gam protein, fused to a CasX protein, which is fused to a cytidine deaminase. In some embodiments, the base editor comprises a Gam protein, fused to a CasY protein, which is fused to a cytidine deaminase. In some embodiments, the base editor comprises a Gam protein, fused to a Cpf 1 protein, which is fused to a cytidine deaminase. In some
embodiments, the base editor comprises a Gam protein, fused to a C2cl protein, which is fused to a cytidine deaminase. In some embodiments, the base editor comprises a Gam protein, fused to a C2c2 protein, which is fused to a cytidine deaminase. In some
embodiments, the base editor comprises a Gam protein, fused to a C2c3 protein, which is fused to a cytidine deaminase. In some embodiments, the base editor comprises a Gam protein, fused to an Argonaute protein, which is fused to a cytidine deaminase. Non-limiting exemplary sequences of the nucleobase editors useful in the present disclosure are provided in Example 1, SEQ ID NOs: 1-260, 270-292, or 315-323. Such nucleobase editors and methods of using them for genome editing have been described in the art, e.g., in US Patent 9,068,179, US Patent Application Publications US20150166980, US20150166981,
US20150166982, US20150166984, and US20150165054, and US Provisional Applications, 62/245,828, 62/279,346, 62/311,763, 62/322,178, 62/357,352, 62/370700, and 62/398490 and in Komor et ah, Nature, "Programmable editing of a target base in genomic DNA without double-stranded DNA cleavage," 533, 420-424 (2016), each of which is incorporated herein by reference.
[0090] The term "uracil glycosylase inhibitor" or "UGI," as used herein, refers to a protein that is capable of inhibiting a uracil-DNA glycosylase base-excision repair enzyme.
[0091] The term "Cas9 nickase," as used herein, refers to a Cas9 protein that is capable of cleaving only one strand of a duplexed nucleic acid molecule (e.g., a duplexed DNA molecule). In some embodiments, a Cas9 nickase comprises a D10A mutation and has a histidine at position H840 of a wild type sequence, or a corresponding mutation in any of the Cas9 proteins provided herein. For example, a Cas9 nickase may comprise the amino acid sequence as set forth in SEQ ID NO: 683. Such a Cas9 nickase has an active HNH nuclease domain and is able to cleave the non-targeted strand of DNA, i.e., the strand bound
by the gRNA. Further, such a Cas9 nickase has an inactive RuvC nuclease domain and is not able to cleave the targeted strand of the DNA, i.e., the strand where base editing is desired.
Exemplary Cas9 nickase (Cloning vector pPlatTET-gRNA2; Accession No. BAV54124).
MDKKYS IGLAIGTNS VGW A VITDE YK VPS KKFKVLGNTDRHS IKKNLIG ALLFDS GE
TAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHE
RHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEG
DLNPDNS D VDKLFIQLVQT YNQLFEENPIN AS G VD AKAILS ARLS KS RRLENLIAQLP
GEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYA
DLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPE
KYKEIFFDQS KNGYAGYIDGGAS QEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQR
TFDNGS IPHQIHLGELH AILRRQEDF YPFLKDNREKIEKILTFRIP Y Y VGPLARGNS RF A
WMTRKS EETITPWNFEE V VDKG AS AQS FIERMTNFDKNLPNEK VLPKHS LLYE YFT V
YNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFD
SVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERL
KTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMQLIHDDS LTFKEDIQKAQVS GQGDS LHEHIANLAGSPAIKKGILQT VKVVDELVK
VMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQL
QNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDK
NRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIK
RQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKV
REINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGK
ATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSM
PQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVV
AKVEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFE
LENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQ
HKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGA
PAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
683)
[0092] The term "target site" or "target sequence" refers to a sequence within a nucleic acid molecule (e.g., a DNA molecule) that is deaminated by the fusion protein (e.g., a dCas9-deaminase fusion protein or a Gam-nCas9-deaminase fusion protein) provided herein. In some embodiments, the target sequence is a polynucleotide (e.g., a DNA), wherein the polynucleotide comprises a coding strand and a complementary strand. The meaning of a "coding strand" and "complementary strand," as used herein, is the same as the common meaning of the terms in the art. In some embodiments, the target sequence is a sequence in the genome of a mammal. In some embodiments, the target sequence is a sequence in the genome of a human. In some embodiments, the target sequence is a sequence in the genome of a non-human animal. The term "target codon" refers to the amino acid codon that is edited by the base editor and converted to a different codon via deamination. The term "target base" refers to the nucleotide base that is edited by the base editor and converted to a different base
via deamination. In some embodiments, the target codon in the coding strand is edited (e.g., deaminated). In some embodiments, the target codon in the complementary strand is edited (e.g., deaminated).
[0093] The term "linker," as used herein, refers to a chemical group or a molecule linking two molecules or moieties, e.g., two domains of a fusion protein, such as, for example, a nuclease-inactive Cas9 domain and a nucleic acid editing domain (e.g., a deaminase domain). In some embodiments, a linker joins a gRNA binding domain of an RNA-programmable nuclease, including a Cas9 nuclease domain, and a catalytic domain of a nucleic-acid editing domain (e.g., a deaminase domain). In some embodiments, a linker joins a Cas9 domain (e.g., a Cas9 nickase) and a Gam protein. In some embodiments, a linker joins a gRNA binding domain of an RNA-programmable nuclease (e.g., dCas9) and a UGI domain. In some embodimens, a linker joins a a catalytic domain of a nucleic-acid editing domain (e.g., a deaminase domain) and a UGI domain. In some embodiments, a linker joins a catalytic domain of a nucleic-acid editing domain (e.g., a deaminase domain) and a Gam protein. In some embodiments, a linker joins a UGI domain and a Gam protein. Typically, the linker is positioned between, or flanked by, two groups, molecules, domains, or other moieties and connected to each one via a covalent bond, thus connecting the two. In some embodiments, the linker is an amino acid or a plurality of amino acids (e.g., a peptide or protein). In some embodiments, the linker is an organic molecule, group, polymer (e.g. a non-natural polymer, non-peptidic polymer), or chemical moiety. In some embodiments, the linker is 5-100 amino acids in length, for example, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 30-35, 35-40, 40-45, 45-50, 50-60, 60-70, 70-80, 80-90, 90-100, 100-150, or 150-200 amino acids in length. Longer or shorter linkers are also contemplated. Linkers may be of any form known in the art. For example, the linker may be a linker from a website such as www[dot]ibi[dot]vu[dot]nl/programs/linkerdbwww/ or from www[dot] ibi[dot]vu[dot]nl/programs/linkerdbwww/src/database.txt. The linkers may also be unstructured, structured, helical, or extended.
[0094] The term "mutation," as used herein, refers to a substitution of a residue within a sequence, e.g., a nucleic acid or amino acid sequence, with another residue, or a deletion or insertion of one or more residues within a sequence. Mutations are typically described herein by identifying the original residue followed by the position of the residue within the sequence and by the identity of the newly substituted residue. Various methods for making the amino acid substitutions (mutations) provided herein are well known in the art, and are provided by, for example, Green and Sambrook, Molecular Cloning: A Laboratory
Manual (4 ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. (2012)).
[0095] The terms "nucleic acid," "polynucleotide," and "nucleic acid molecule," as used herein, refer to a compound comprising a nucleobase and an acidic moiety, e.g., a nucleoside, a nucleotide, or a polymer of nucleotides. Typically, polymeric nucleic acids, e.g., nucleic acid molecules comprising three or more nucleotides are linear molecules, in which adjacent nucleotides are linked to each other via a phosphodiester linkage. In some embodiments, "nucleic acid" refers to individual nucleic acid residues (e.g. nucleotides and/or nucleosides). In some embodiments, "nucleic acid" refers to an oligonucleotide chain comprising three or more individual nucleotide residues. As used herein, the terms
"oligonucleotide" and "polynucleotide" can be used interchangeably to refer to a polymer of nucleotides (e.g., a string of at least three nucleotides). In some embodiments, "nucleic acid" encompasses RNA as well as single and/or double- stranded DNA. Nucleic acids may be naturally occurring, for example, in the context of a genome, a transcript, an mRNA, tRNA, rRNA, siRNA, snRNA, a plasmid, cosmid, chromosome, chromatid, or other naturally occurring nucleic acid molecule. On the other hand, a nucleic acid molecule may be a non- naturally occurring molecule, e.g., a recombinant DNA or RNA, an artificial chromosome, an engineered genome, or fragment thereof, or a synthetic DNA, RNA, DNA/RNA hybrid, or including non-naturally occurring nucleotides or nucleosides. Furthermore, the terms "nucleic acid," "DNA," "RNA," and/or similar terms include nucleic acid analogs, e.g., analogs having other than a phosphodiester backbone. Nucleic acids can be purified from natural sources, produced using recombinant expression systems and optionally purified, chemically synthesized, etc. Where appropriate, e.g., in the case of chemically synthesized molecules, nucleic acids can comprise nucleoside analogs such as analogs having chemically modified bases or sugars, and backbone modifications. A nucleic acid sequence is presented in the 5' to 3' direction unless otherwise indicated. In some embodiments, a nucleic acid is or comprises natural nucleosides (e.g. adenosine, thymidine, guanosine, cytidine, uridine, deoxyadenosine, deoxythymidine, deoxyguanosine, and deoxycytidine); nucleoside analogs (e.g., 2-aminoadenosine, 2-thiothymidine, inosine, pyrrolo-pyrimidine, 3-methyl adenosine, 5-methylcytidine, 2-aminoadenosine, C5-bromouridine, C5-fluorouridine, C5-iodouridine, C5-propynyl-uridine, C5-propynyl-cytidine, C5-methylcytidine, 2-aminoadenosine, 7- deazaadenosine, 7-deazaguanosine, 8-oxoadenosine, 8-oxoguanosine, 0(6)-methylguanine, and 2-thiocytidine); chemically modified bases; biologically modified bases (e.g., methylated bases); intercalated bases; modified sugars (e.g., 2'-fluororibose, ribose, 2'-deoxyribose, arabinose, and hexose); and/or modified phosphate groups (e.g., phosphorothioates and 5'-N-
phosphor amidite linkages).
[0096] The terms "protein," "peptide," and "polypeptide" are used interchangeably herein, and refer to a polymer of amino acid residues linked together by peptide (amide) bonds. The terms refer to a protein, peptide, or polypeptide of any size, structure, or function. Typically, a protein, peptide, or polypeptide will be at least three amino acids long. A protein, peptide, or polypeptide may refer to an individual protein or a collection of proteins. One or more of the amino acids in a protein, peptide, or polypeptide may be modified, for example, by the addition of a chemical entity such as a carbohydrate group, a hydroxyl group, a phosphate group, a farnesyl group, an isofarnesyl group, a fatty acid group, a linker for conjugation, functionalization, or other modification, etc. A protein, peptide, or polypeptide may also be a single molecule or may be a multi-molecular complex. A protein, peptide, or polypeptide may be just a fragment of a naturally occurring protein or peptide. A protein, peptide, or polypeptide may be naturally occurring, recombinant, or synthetic, or any combination thereof. The term "fusion protein" as used herein refers to a hybrid polypeptide which comprises protein domains from at least two different proteins. One protein may be located at the amino-terminal (N-terminal) portion of the fusion protein or at the carboxy- terminal (C-terminal) protein thus forming an "amino-terminal fusion protein" or a "carboxy- terminal fusion protein," respectively. A protein may comprise different domains, for example, a nucleic acid binding domain (e.g., the gRNA binding domain of Cas9 that directs the binding of the protein to a target site) and a nucleic acid cleavage domain or a catalytic domain of a nucleic-acid editing protein. In some embodiments, a protein is in a complex with, or is in association with, a nucleic acid, e.g., RNA. Any of the proteins provided herein may be produced by any method known in the art. For example, the proteins provided herein may be produced via recombinant protein expression and purification, which is especially well suited for fusion proteins comprising a peptide linker. Methods for recombinant protein expression and purification are well known, and include those described by Green and Sambrook, Molecular Cloning: A Laboratory Manual (4th ed., Cold Spring Harbor
Laboratory Press, Cold Spring Harbor, N.Y. (2012)), which is incorporated herein by reference.
[0097] The term "subject," as used herein, refers to an individual organism, for example, an individual mammal. In certain embodiments of the aspects described herein, the subject is a mammal, e.g., a primate, e.g., a human. In some embodiments, the subject is a non-human mammal. In some embodiments, the subject is a non-human primate. Non- human primates include, but are not limited to, chimpanzees, cynomologous monkeys, spider
monkeys, and macaques, e.g., Rhesus. In some embodiments, the subject is any rodent, e.g., mice, rats, woodchucks, ferrets, rabbits and hamsters. In other embodiments, the subject is a domestic or game animal which includes, but is not limited to: cows, horses, pigs, deer, bison, buffalo, feline species, e.g., domestic cat, canine species, e.g., dog, fox, wolf, avian species, e.g., chicken, emu, ostrich, and fish, e.g., trout, catfish and salmon. In some embodiments, the subject is a sheep, a goat, a cattle, a cat, or a dog. In some embodiments, the subject is a research animal. In some embodiments, the subject is genetically engineered, e.g., a genetically engineered non-human subject. The subject may be of either sex and at any stage of development. For example, asubject may be male or female, and can be a fully developed subject (e.g., an adult) or a subject undergoing the developmental process (e.g., a child, infant or fetus). The term "patient" or "subject" includes any subset of the foregoing, e.g., all of the above, but excluding one or more groups or species such as humans, primates or rodents. The terms, "patient" and "subject" are used interchangeably herein.
[0098] The term "recombinant" as used herein in the context of proteins or nucleic acids refers to proteins or nucleic acids that do not occur in nature, but are the product of human engineering. For example, in some embodiments, a recombinant protein or nucleic acid molecule comprises an amino acid or nucleotide sequence that comprises at least one, at least two, at least three, at least four, at least five, at least six, or at least seven mutations as compared to any naturally occurring sequence. The fusion proteins (e.g., base editors) described herein are made recombinantly. Recombinant technology is familiar to those skilled in the art.
[0099] An "intron" refers to any nucleotide sequence within a gene that is removed by RNA splicing during maturation of the final RNA product. The term intron refers to both the DNA sequence within a gene and the corresponding sequence in RNA transcripts.
Sequences that are joined together in the final mature RNA after RNA splicing are exons. Introns are found in the genes of most organisms and many viruses, and can be located in a wide range of genes, including those that generate proteins, ribosomal RNA (rRNA), and transfer RNA (tRNA). When proteins are generated from intron-containing genes, RNA splicing takes place as part of the RNA processing pathway that follows transcription and precedes translation.
[00100] An "exon" refers to any part of a gene that will become a part of the final mature RNA produced by that gene after introns have been removed by RNA splicing. The term exon refers to both the DNA sequence within a gene and to the corresponding sequence
in RNA transcripts. In RNA splicing, introns are removed and exons are covalently joined to one another as part of generating the mature messenger RNA.
[00101] "Splicing" refers to the processing of a newly synthesized messenger RNA transcript (also referred to as a primary mRNA transcript). After splicing, introns are removed and exons are joined together (ligated) for form mature mRNA molecule containing a complete open reading frame that is decoded and translated into a protein. For nuclear- encoded genes, splicing takes place within the nucleus either co-transcriptionally or immediately after transcription. The molecular mechanism of RNA splicing has been extensively described, e.g., in Pagani et al, Nature Reviews Genetics 5, 389-396, 2004;
Clancy et al, Nature Education 1 ( 1 ) : 31, 2011 ; Cheng et al., Molecular Genetics and Genomics 286 (5-6): 395-410, 2014; Taggart et al., Nature Structural & Molecular Biology 19 (7): 719-2, 2012, the contents of each of which are incorporated herein by reference. One skilled in the art is familiar with the mechanism of RNA splicing.
[00102] "Alternative splicing" refers to a regulated process during gene expression that results in a single gene coding for multiple proteins. In this process, particular exons of a gene may be included within or excluded from the final, processed messenger RNA (mRNA) produced from that gene. Consequently, the proteins translated from alternatively spliced mRNAs will contain differences in their amino acid sequence and, often, in their biological functions . Notably, alternative splicing allows the human genome to direct the synthesis of many more proteins than would be expected from its 20,000 protein-coding genes.
Alternative splicing is sometimes also termed differential splicing. Alternative splicing occurs as a normal phenomenon in eukaryotes, where it greatly increases the biodiversity of proteins that can be encoded by the genome; in humans, -95% of multi-exonic genes are alternatively spliced. There are numerous modes of alternative splicing observed, of which the most common is exon skipping. In this mode, a particular exon may be included in mRNAs under some conditions or in particular tissues, and omitted from the mRNA in others. Abnormal variations in splicing are also implicated in disease; a large proportion of human genetic disorders result from splicing variants. Abnormal splicing variants are also thought to contribute to the development of cancer, and splicing factor genes are frequently mutated in different types of cancer. The regulation of alternative splicing is also described in the art, e.g., in Douglas et al., Annual Review of Biochemistry 72 (1): 291-336, 2003; Pan et al, Nature Genetics 40 (12): 1413-1415, 2008; Martin et al, Nature Reviews 6 (5): 386-398, 2005; Skotheim et al, The International Journal of Biochemistry & Cell Biology 39 (7-8): 1432-49, 2007, each of which is incorporated herein by reference.
[00103] A "coding frame" or "open reading frame" refers to a stretch of codons that encodes a polypeptide. Since DNA is interpreted in groups of three nucleotides (codons), a DNA strand has three distinct reading frames. The double helix of a DNA molecule has two anti-parallel strands so, with the two strands having three reading frames each, there are six possible frame translations. A functional protein may be produced when translation proceeds in the correct coding frame. An insertion or a deletion of one or two bases in the open reading frame causes a shift in the coding frame that is also referred to as a "frameshift mutation." A frameshift mutation typical results in premature translation termination and/or truncated or non-functional protein.
[00104] These and other exemplary substituents are described in more detail in the
Detailed Description, Examples, and Claims. The methods and compositions disclosed herein are not intended to be limited in any manner by the above exemplary listing of substituents.
DETAILED DESCRIPTION OF CERTAIN EMBODIMENTS
[00105] Disclosed herein are novel genome/base-editing systems, methods, and compositions for generating engineered and naturally-occurring protective variants of the C- C Chemokine Receptor 5 (CCR5) protein to protect against human immunodeficiency virus (HIV) infection and acquired immune deficiency syndrome (AIDS). C-C Chemokine Receptor 5 (CCR5), also known as cluster of differentiation- 195 (CD195), is a member of the beta chemokine receptor family. This protein is expressed by macrophages, dendritic cells, and memory T cells in the immune system; endothelial cells, epithelial cells, vascular smooth muscle cells, and fibroblasts; and microglia, neurons, and astrocytes in the central nervous system. See, e.g., Barmania and Pepper, Applied & Translational Genomics 2 (2013) 3-16, each of which is incorporated herein by reference. Macrophage-tropic (M-tropic) strains of HIV {e.g., M-tropic strains of HIV-1) can bind CCR5 in order to enter host cells.
[00106] Certain alleles of CCR5 have been associated with resistance to HIV infection.
As one example, CCR5-A32 (also known as CCR5-D32, CCR5A32, or CCR5 delta 32) is a 32-base-pair deletion that introduces a premature stop codon into the CCR5 receptor locus, resulting in a non-functional receptor. CCR5-A32 has a heterozygote allele frequency of 10% and a homozygote frequency of 1% in Europe. Individuals who are homozygous for CCR5-A32 do not express functional CCR5 receptors on their cell surfaces and are resistant to HIV-1 infection (see, for example, Liu et ah, (Aug 1996). "Homozygous defect in HIV-1 coreceptor accounts for resistance of some multiply-exposed individuals to HIV-1
infection". Cell. 86 (3): 367-77). Individuals heterozygous for CCR5-A32 have a greater
than 50% reduction in functional CCR5 receptors on their cell surfaces which interferes with transport of CCR5 to the cell surface. This level of reduction is due to the dimerization of mutant and wild-type receptors (see, for example, Benkirane et ah, (Dec 1997). "Mechanism of transdominant inhibition of CCR5-mediated HIV-1 infection by ccr5delta32".7 ze Journal of Biological Chemistry. 272 (49): 30603-6). These heterozygous individuals are resistant to HIV- 1 infection and, if infected, exhibit reduced viral loads and a two to three year delay in the development of AIDS (relative to individuals with two wild type CCR5 genes; see, for example, Dean M et ah, (Sep 1996). "Genetic restriction of HIV-1 infection and progression to AIDS by a deletion allele of the CKR5 structural gene. Hemophilia Growth and
Development Study, Multicenter AIDS Cohort Study, Multicenter Hemophilia Cohort Study, San Francisco City Cohort, ALIVE Study". Science. 273 (5283): 1856-62; Liu et al., (Aug 1996). "Homozygous defect in HIV-1 coreceptor accounts for resistance of some multiply- exposed individuals to HIV-1 infection". Cell. 86 (3): 367-77; Michael NL et al, (Oct 1997). "The role of CCR5 and CCR2 polymorphisms in HIV-1 transmission and disease
progression". Nature Medicine. 3 (10): 1160-2). Further, individuals who are homozygous for CCR5-A32 also display an improved response to anti-retroviral treatment (see, for example, Laurichesse et ah, (May 2007). "Improved virological response to highly active antiretroviral therapy in HIV-1 -infected patients carrying the CCR5 Delta32 deletion." HIV Medicine. 8 (4): 213-9).
[00107] The mRNA sequence for human CCR5, which encodes a 352 amino acid protein, can be foundunder GenBank Accession No. NM_000579.3 (transcript variant A) or GenBank Accession No. NM_001100168.1 (transcript variant B). Mouse and rat CCR5 mRNA sequences have been deposited and can be found under GenBank Accession Nos.: NM_009917.5 and NMJ353960.3, respectively. The wild-type CCR5 human, mouse, and rat protein sequences can be found under GenBank Accession Nos.: NP_001093638.1,
NP_034047.2, and NP_446412.2, respectively.
Wild type CCR5 Gene (>gill54091329lreflNM_000579.3l Homo sapiens C-C motif chemokine receptor 5 (gene/pseudogene) (CCR5), transcript variant A, mRNA, SEQ ID NO: 325)
CTTCAGATAGATTATATCTGGAGTGAAGAATCCTGCCACCTATGTATCTGGCATA GTATTCTGTGTAGTGGGATGAGCAGAGAACAAAAACAAAATAATCCAGTGAGAA AAGCCCGTAAATAAACCTTCAGACCAGAGATCTATTCTCTAGCTTATTTTAAGCT CAACTTAAAAAGAAGAACTGTTCTCTGATTCTTTTCGCCTTCAATACACTTAATG
ATTTAACTCCACCCTCCTTCAAAAGAAACAGCATTTCCTACTTTTATACTGTCTAT
ATGATTGATTTGCACAGCTCATCTGGCCAGAAGAGCTGAGACATCCGTTCCCCTA
CAAGAAACTCTCCCCGGGTGGAACAAGATGGATTATCAAGTGTCAAGTCCAATC
TATGACATCAATTATTATACATCGGAGCCCTGCCAAAAAATCAATGTGAAGCAA
ATCGCAGCCCGCCTCCTGCCTCCGCTCTACTCACTGGTGTTCATCTTTGGTTTTGT
GGGCAACATGCTGGTCATCCTCATCCTGATAAACTGCAAAAGGCTGAAGAGCAT
GACTGACATCTACCTGCTCAACCTGGCCATCTCTGACCTGTTTTTCCTTCTTACTG
TCCCCTTCTGGGCTCACTATGCTGCCGCCCAGTGGGACTTTGGAAATACAATGTG
TCAACTCTTGACAGGGCTCTATTTTATAGGCTTCTTCTCTGGAATCTTCTTCATCA
TCCTCCTGACAATCGATAGGTACCTGGCTGTCGTCCATGCTGTGTTTGCTTTAAAA
GCCAGGACGGTCACCTTTGGGGTGGTGACAAGTGTGATCACTTGGGTGGTGGCTG
TGTTTGCGTCTCTCCCAGGAATCATCTTTACCAGATCTCAAAAAGAAGGTCTTCA
TTACACCTGCAGCTCTCATTTTCCATACAGTCAGTATCAATTCTGGAAGAATTTCC
AGACATTAAAGATAGTCATCTTGGGGCTGGTCCTGCCGCTGCTTGTCATGGTCAT
CTGCTACTCGGGAATCCTAAAAACTCTGCTTCGGTGTCGAAATGAGAAGAAGAG
GCACAGGGCTGTGAGGCTTATCTTCACCATCATGATTGTTTATTTTCTCTTCTGGG
CTCCCTACAACATTGTCCTTCTCCTGAACACCTTCCAGGAATTCTTTGGCCTGAAT
AATTGCAGTAGCTCTAACAGGTTGGACCAAGCTATGCAGGTGACAGAGACTCTT
GGGATGACGCACTGCTGCATCAACCCCATCATCTATGCCTTTGTCGGGGAGAAGT
TCAGAAACTACCTCTTAGTCTTCTTCCAAAAGCACATTGCCAAACGCTTCTGCAA
ATGCTGTTCTATTTTCCAGCAAGAGGCTCCCGAGCGAGCAAGCTCAGTTTACACC
CGATCCACTGGGGAGCAGGAAATATCTGTGGGCTTGTGACACGGACTCAAGTGG
GCTGGTGACCCAGTCAGAGTTGTGCACATGGCTTAGTTTTCATACACAGCCTGGG
CTGGGGGTGGGGTGGGAGAGGTCTTTTTTAAAAGGAAGTTACTGTTATAGAGGG
TCTAAGATTCATCCATTTATTTGGCATCTGTTTAAAGTAGATTAGATCTTTTAAGC
CCATCAATTATAGAAAGCCAAATCAAAATATGTTGATGAAAAATAGCAACCTTTT
TATCTCCCCTTCACATGCATCAAGTTATTGACAAACTCTCCCTTCACTCCGAAAGT
TCCTTATGTATATTTAAAAGAAAGCCTCAGAGAATTGCTGATTCTTGAGTTTAGT
GATCTGAACAGAAATACCAAAATTATTTCAGAAATGTACAACTTTTTACCTAGTA
CAAGGCAACATATAGGTTGTAAATGTGTTTAAAACAGGTCTTTGTCTTGCTATGG
GGAGAAAAGACATGAATATGATTAGTAAAGAAATGACACTTTTCATGTGTGATTT
CCCCTCCAAGGTATGGTTAATAAGTTTCACTGACTTAGAACCAGGCGAGAGACTT
GTGGCCTGGGAGAGCTGGGGAAGCTTCTTAAATGAGAAGGAATTTGAGTTGGAT
CATCTATTGCTGGCAAAGACAGAAGCCTCACTGCAAGCACTGCATGGGCAAGCT
TGGCTGTAGAAGGAGACAGAGCTGGTTGGGAAGACATGGGGAGGAAGGACAAG
GCTAGATCATGAAGAACCTTGACGGCATTGCTCCGTCTAAGTCATGAGCTGAGCA
GGGAGATCCTGGTTGGTGTTGCAGAAGGTTTACTCTGTGGCCAAAGGAGGGTCA
GGAAGGATGAGCATTTAGGGCAAGGAGACCACCAACAGCCCTCAGGTCAGGGTG
AGGATGGCCTCTGCTAAGCTCAAGGCGTGAGGATGGGAAGGAGGGAGGTATTCG
TAAGGATGGGAAGGAGGGAGGTATTCGTGCAGCATATGAGGATGCAGAGTCAGC
AGAACTGGGGTGGATTTGGGTTGGAAGTGAGGGTCAGAGAGGAGTCAGAGAGA
ATCCCTAGTCTTCAAGCAGATTGGAGAAACCCTTGAAAAGACATCAAGCACAGA
AGGAGGAGGAGGAGGTTTAGGTCAAGAAGAAGATGGATTGGTGTAAAAGGATG
GGTCTGGTTTGCAGAGCTTGAACACAGTCTCACCCAGACTCCAGGCTGTCTTTCA
CTGAATGCTTCTGACTTCATAGATTTCCTTCCCATCCCAGCTGAAATACTGAGGG
GTCTCCAGGAGGAGACTAGATTTATGAATACACGAGGTATGAGGTCTAGGAACA
TACTTCAGCTCACACATGAGATCTAGGTGAGGATTGATTACCTAGTAGTCATTTC
ATGGGTTGTTGGGAGGATTCTATGAGGCAACCACAGGCAGCATTTAGCACATACT
ACACATTCAATAAGCATCAAACTCTTAGTTACTCATTCAGGGATAGCACTGAGCA
AAGCATTGAGCAAAGGGGTCCCATAGAGGTGAGGGAAGCCTGAAAAACTAAGA
TGCTGCCTGCCCAGTGCACACAAGTGTAGGTATCATTTTCTGCATTTAACCGTCA
ATAGGCAAAGGGGGGAAGGGACATATTCATTTGGAAATAAGCTGCCTTGAGCCT
TAAAACCCACAAAAGTACAATTTACCAGCCTCCGTATTTCAGACTGAATGGGGGT
GGGGGGGGCGCCTTAGGTACTTATTCCAGATGCCTTCTCCAGACAAACCAGAAG
CAACAGAAAAAATCGTCTCTCCCTCCCTTTGAAATGAATATACCCCTTAGTGTTT
GGGTATATTCATTTCAAAGGGAGAGAGAGAGGTTTTTTTCTGTTCTGTCTCATAT
GATTGTGCACATACTTGAGACTGTTTTGAATTTGGGGGATGGCTAAAACCATCAT
AGTACAGGTAAGGTGAGGGAATAGTAAGTGGTGAGAACTACTCAGGGAATGAA
GGTGTCAGAATAATAAGAGGTGCTACTGACTTTCTCAGCCTCTGAATATGAACGG
TGAGCATTGTGGCTGTCAGCAGGAAGCAACGAAGGGAAATGTCTTTCCTTTTGCT
CTTAAGTTGTGGAGAGTGCAACAGTAGCATAGGACCCTACCCTCTGGGCCAAGTC
AAAGACATTCTGACATCTTAGTATTTGCATATTCTTATGTATGTGAAAGTTACAA
ATTGCTTGAAAGAAAATATGCATCTAATAAAAAACACCTTCTAAAATAAAAAAA
AAAAAAAAAAAAAAAAAAAA
Wild type CCR5 Gene, transcript variant B (>gill54091327lreflNM_001100168.11 Homo sapiens C-C motif chemokine receptor 5 (gene/pseudogene) (CCR5), transcript variant B, mRNA, SEQ ID NO: 326)
CTTCAGATAGATTATATCTGGAGTGAAGAATCCTGCCACCTATGTATCTGGCATA
GTCTCATCTGGCCAGAAGAGCTGAGACATCCGTTCCCCTACAAGAAACTCTCCCC
GGGTGGAACAAGATGGATTATCAAGTGTCAAGTCCAATCTATGACATCAATTATT
ATACATCGGAGCCCTGCCAAAAAATCAATGTGAAGCAAATCGCAGCCCGCCTCC
TGCCTCCGCTCTACTCACTGGTGTTCATCTTTGGTTTTGTGGGCAACATGCTGGTC
ATCCTCATCCTGATAAACTGCAAAAGGCTGAAGAGCATGACTGACATCTACCTGC
TCAACCTGGCCATCTCTGACCTGTTTTTCCTTCTTACTGTCCCCTTCTGGGCTCACT
ATGCTGCCGCCCAGTGGGACTTTGGAAATACAATGTGTCAACTCTTGACAGGGCT
CTATTTTATAGGCTTCTTCTCTGGAATCTTCTTCATCATCCTCCTGACAATCGATA
GGTACCTGGCTGTCGTCCATGCTGTGTTTGCTTTAAAAGCCAGGACGGTCACCTT
TGGGGTGGTGACAAGTGTGATCACTTGGGTGGTGGCTGTGTTTGCGTCTCTCCCA
GGAATCATCTTTACCAGATCTCAAAAAGAAGGTCTTCATTACACCTGCAGCTCTC
ATTTTCCATACAGTCAGTATCAATTCTGGAAGAATTTCCAGACATTAAAGATAGT
CATCTTGGGGCTGGTCCTGCCGCTGCTTGTCATGGTCATCTGCTACTCGGGAATCC
TAAAAACTCTGCTTCGGTGTCGAAATGAGAAGAAGAGGCACAGGGCTGTGAGGC
TTATCTTCACCATCATGATTGTTTATTTTCTCTTCTGGGCTCCCTACAACATTGTCC
TTCTCCTGAACACCTTCCAGGAATTCTTTGGCCTGAATAATTGCAGTAGCTCTAAC
AGGTTGGACCAAGCTATGCAGGTGACAGAGACTCTTGGGATGACGCACTGCTGC
ATCAACCCCATCATCTATGCCTTTGTCGGGGAGAAGTTCAGAAACTACCTCTTAG
TCTTCTTCCAAAAGCACATTGCCAAACGCTTCTGCAAATGCTGTTCTATTTTCCAG
CAAGAGGCTCCCGAGCGAGCAAGCTCAGTTTACACCCGATCCACTGGGGAGCAG
GAAATATCTGTGGGCTTGTGACACGGACTCAAGTGGGCTGGTGACCCAGTCAGA
GTTGTGCACATGGCTTAGTTTTCATACACAGCCTGGGCTGGGGGTGGGGTGGGAG
AGGTCTTTTTTAAAAGGAAGTTACTGTTATAGAGGGTCTAAGATTCATCCATTTA
TTTGGCATCTGTTTAAAGTAGATTAGATCTTTTAAGCCCATCAATTATAGAAAGC
CAAATCAAAATATGTTGATGAAAAATAGCAACCTTTTTATCTCCCCTTCACATGC
ATCAAGTTATTGACAAACTCTCCCTTCACTCCGAAAGTTCCTTATGTATATTTAAA
AGAAAGCCTCAGAGAATTGCTGATTCTTGAGTTTAGTGATCTGAACAGAAATACC
AAAATTATTTCAGAAATGTACAACTTTTTACCTAGTACAAGGCAACATATAGGTT
GTAAATGTGTTTAAAACAGGTCTTTGTCTTGCTATGGGGAGAAAAGACATGAATA
TGATTAGTAAAGAAATGACACTTTTCATGTGTGATTTCCCCTCCAAGGTATGGTT
AATAAGTTTCACTGACTTAGAACCAGGCGAGAGACTTGTGGCCTGGGAGAGCTG
GGGAAGCTTCTTAAATGAGAAGGAATTTGAGTTGGATCATCTATTGCTGGCAAAG
ACAGAAGCCTCACTGCAAGCACTGCATGGGCAAGCTTGGCTGTAGAAGGAGACA
GAGCTGGTTGGGAAGACATGGGGAGGAAGGACAAGGCTAGATCATGAAGAACC
TTGACGGCATTGCTCCGTCTAAGTCATGAGCTGAGCAGGGAGATCCTGGTTGGTG
TTGCAGAAGGTTTACTCTGTGGCCAAAGGAGGGTCAGGAAGGATGAGCATTTAG
GGCAAGGAGACCACCAACAGCCCTCAGGTCAGGGTGAGGATGGCCTCTGCTAAG
CTCAAGGCGTGAGGATGGGAAGGAGGGAGGTATTCGTAAGGATGGGAAGGAGG
GAGGTATTCGTGCAGCATATGAGGATGCAGAGTCAGCAGAACTGGGGTGGATTT
GGGTTGGAAGTGAGGGTCAGAGAGGAGTCAGAGAGAATCCCTAGTCTTCAAGCA
GATTGGAGAAACCCTTGAAAAGACATCAAGCACAGAAGGAGGAGGAGGAGGTT
TAGGTCAAGAAGAAGATGGATTGGTGTAAAAGGATGGGTCTGGTTTGCAGAGCT
TGAACACAGTCTCACCCAGACTCCAGGCTGTCTTTCACTGAATGCTTCTGACTTC
ATAGATTTCCTTCCCATCCCAGCTGAAATACTGAGGGGTCTCCAGGAGGAGACTA
GATTTATGAATACACGAGGTATGAGGTCTAGGAACATACTTCAGCTCACACATGA
GATCTAGGTGAGGATTGATTACCTAGTAGTCATTTCATGGGTTGTTGGGAGGATT
CTATGAGGCAACCACAGGCAGCATTTAGCACATACTACACATTCAATAAGCATC
AAACTCTTAGTTACTCATTCAGGGATAGCACTGAGCAAAGCATTGAGCAAAGGG
GTCCCATAGAGGTGAGGGAAGCCTGAAAAACTAAGATGCTGCCTGCCCAGTGCA
CACAAGTGTAGGTATCATTTTCTGCATTTAACCGTCAATAGGCAAAGGGGGGAA
GGGACATATTCATTTGGAAATAAGCTGCCTTGAGCCTTAAAACCCACAAAAGTAC
AATTTACCAGCCTCCGTATTTCAGACTGAATGGGGGTGGGGGGGGCGCCTTAGGT
ACTTATTCCAGATGCCTTCTCCAGACAAACCAGAAGCAACAGAAAAAATCGTCTC
TCCCTCCCTTTGAAATGAATATACCCCTTAGTGTTTGGGTATATTCATTTCAAAGG
GAGAGAGAGAGGTTTTTTTCTGTTCTGTCTCATATGATTGTGCACATACTTGAGA
CTGTTTTGAATTTGGGGGATGGCTAAAACCATCATAGTACAGGTAAGGTGAGGG
AATAGTAAGTGGTGAGAACTACTCAGGGAATGAAGGTGTCAGAATAATAAGAGG
TGCTACTGACTTTCTCAGCCTCTGAATATGAACGGTGAGCATTGTGGCTGTCAGC
AGGAAGCAACGAAGGGAAATGTCTTTCCTTTTGCTCTTAAGTTGTGGAGAGTGCA
ACAGTAGCATAGGACCCTACCCTCTGGGCCAAGTCAAAGACATTCTGACATCTTA
GTATTTGCATATTCTTATGTATGTGAAAGTTACAAATTGCTTGAAAGAAAATATG
CATCTAATAAAAAACACCTTCTAAAATAAAAAAAAAAAAAAAAAAAAAAAAAA
A
Human CCR5 Amino Acid Sequence (>gil 154091328 lreflNP_001093638.11 C-C chemokine receptor type 5 [Homo sapiens], SEQ ID NO: 327)
MDYQVSSPIYDINYYTSEPCQKINVKQIAARLLPPLYSLVFIFGFVGNMLVILILINCKR
LKSMTDIYLLNLAISDLFFLLTVPFWAHYAAAQWDFGNTMCQLLTGLYFIGFFSGIFF
IILLTIDRYLAVVHAVFALKARTVTFGVVTSVITWVVAVFASLPGIIFTRSQKEGLHYT
CS SHFPYS QYQFWKNFQTLKIVILGLVLPLLVM VIC YS GILKTLLRCRNEKKRHRA VR
LIFTIMIVYFLFWAPYNIVLLLNTFQEFFGLNNCSSSNRLDQAMQVTETLGMTHCCIN
PIIYAFVGEKFRNYLLVFFQKHIAKRFCKCCSIFQQEAPERASSVYTRSTGEQEISVGL
Mouse CCR5 Amino Acid Sequence (>gil31542356lreflNP_034047.2l C-C chemokine receptor type 5 [Mus musculus], SEQ ID NO: 328)
MDFQGS VPT YS YDID YGMS APC QKIN VKQIA AQLLPPLYS LVFIFGFVGNMM VFLILI
SCKKLKSVTDIYLLNLAISDLLFLLTLPFWAHYAANEWVFGNIMCKVFTGLYHIGYF
GGIFFIILLTIDRYLAIVHAVFALKVRTVNFGVITSVVTWAVAVFASLPEIIFTRSQKEG
FHYTCSPHFPHTQYHFWKSFQTLKMVILSLILPLLVMVICYSGILHTLFRCRNEKKRH
RAVRLIFAIMIVYFLFWTPYNIVLLLTTFQEFFGLNNCSSSNRLDQAMQATETLGMTH
CCLNPVIYAFVGEKFRSYLSVFFRKHMVKRFCKRCSIFQQDNPDRASSVYTRSTGEH
EVSTGL
Rat CCR5 Amino Acid Sequence (>gil51592090lreflNP_446412.2l C-C chemokine receptor type 5 [Rattus norvegicus], SEQ ID NO: 329)
MDFQGSIPTYIYDIDYSMSAPCQKFNVKQIAAQLLPPLYSLVFIFGFVGNMMVFLILIS
CKKLKSMTDIYLFNLAISDLLFLLTLPFWAHYAANEWVFGNIMCKLFTGIYHIGYFG
GIFFIILLTIDRYLAIVHAVFAIKARTVNFGVITSVVTWVVAVFVSLPEIIFMRSQKEGS
HYTCSPHFPRIQYRFWKHFQTLKMVILSLILPLLVMVICYSGILNTLFRCRNEKKRHR
AVRLIFAIMIVYFLFWTPYNIVLLLTTFQEYFGLNNCSSSNRLDQAMQVTETLGMTHC
CLNPVIYAFVGEKFRNYLSVFFRKHIVKRFCKHCSIFQQVNPDRVSSVYTRSTGEQEV
STGL
Strategies for Generating CCR5 Mutants
[00108] Some aspects of the present disclosure provide systems, compositions, and methods of editing polynucleotides encoding the CCR5 protein to introduce mutations into the CCR5 gene. The gene editing methods described herein, rely on nucleobase editors as described in US Patent 9,068,179, US Patent Application Publications US20150166980, US20150166981, US20150166982, US20150166984, and US20150165054, and US
Provisional Applications 62/245828, 62/279346, 62/311,763, 62/322178, 62/357352,
62/370700, and 62/398490, and in Komor et ah, Nature, Programmable editing of a target base in genomic DNA without double-stranded DNA cleavage, 533, 420-424 (2016), each of which are incorporated herein by reference.
[00109] The nucleobase editors are highly efficient at precisely editing a target base in the CCR5 gene, and a DNA double stand break is not necessary for the gene editing, thus reducing genome instability and preventing possible oncogenic modifications that may be caused by other genome editing methods. The nucleobase editors described herein may be programmed to target and modify a single base. In some embodiments, the target base is a cytosine (C) base and may be converted to a thymine (T) base via deamination by the nucleobase editor.
[00110] To edit the polynucleotide encoding the CCR5 protein, the polynucleotide is contacted with a nucleobase editors described herein. In some embodiments, the CCR5- encoding polynucleotide is contacted with a nucleobase editor and a guide nucleotide sequence, wherein the guide nucleotide sequence targets the nucleobase editor to the target base {e.g., a C base) in the CCR5-encoding polynucleotide.
[00111] In some embodiments, the CCR5-encoding polynucleotide is the CCR5 gene locus in the genomic DNA of a cell. In some embodiments, the cell is a cultured cell. In some embodiments, the cell is in vivo. In some embodiments, the cell is in vitro. In some embodiments, the cell is ex vivo. In some embodiments, the cell is from a mammal. In some embodiments, the mammal is a human. In some embodiments, the mammal is a rodent. In some embodiments, the rodent is a mouse. In some embodiments, the rodent is a rat.
[00112] As would be understood be those skilled in the art, the CCR5-encoding polynucleotide may be a DNA molecule comprising a coding strand and a complementary strand, e.g., the CCR5 gene locus in a genome. As such, the CCR5-encoding polynucleotide may also include coding regions {e.g., exons) and non-coding regions {e.g., introns or splicing sites). In some embodiments, the target base {e.g., a C base) is located in a coding region {e.g., an exon) of the CCR5-encoding polynucleotide {e.g., the CCR5 gene locus). As such, the conversion of a base in the coding region may result in an amino acid change in the CCR5 protein sequence, i.e., a mutation. In some embodiments, the mutation is a loss of function mutation. In some embodiments, the CCR5 loss-of-function mutation is identical (or similar) to a naturally occurring CCR5 loss-of-function mutation, e.g., D2V (D2N), C20S (C20Y), C101X (C101Y), G106R, C178R (C178Y), R223Q, C269F (C269Y). In some embodiments, the loss-of-function mutation is engineered {i.e., not naturally occurring), e.g., Q4X, P19S, P19L, Q21X, P34S, P34L, P35S, P35L, G44R, G44D, G44S, G47R, G47D,
G47S, W86X, Q93X, W94X, Q102X, G111R, Gi l ID, G115R, G115D, G115E, G145R, G145E, S 149N, G163R, G163E, S 149N, P162S, P162L, G163R, G163D, G163E, P183S, P183L, Q186X, Q188X, W190X, G202R, G202E, P206S, P206L, G216S, G216D, W248X, Q261X, Q277X, Q280X, E283R, E283K, C290T, C290Y, C291Y, C291T, P293S, P293L, Q328X, Q329X, P332S, P332L, R334X, A335V, R341X. This engineered mutation may be an engineered truncation.
[00113] In some embodiments, the target base is located in a non-coding region of the
CCR5 gene, e.g., in an intron or a splicing site. In some embodiments, a target base is located in a splicing site and the editing of such target base causes alternative splicing of the CCR5 mRNA. In some embodiments, the alternative splicing leads to loss-of-function CCR5 mutants. In some embodiments, the alternative splicing leads to the introduction of a premature stop codon in a CCR5 mRNA, resulting in truncated and unstable CCR5 proteins. In some embodiments, CCR5 mutants that are defective in terms of folding are produced.
[00114] CCR5 variants that are particularly useful in creating using the present disclosure are variants that may increase resistance to infection by human immunodeficiency virus (HIV), prevent infection by HIV, delay the onset of AIDS, and/or slow the progression of AIDS. In some embodiments, the CCR5 variants are loss-of-function variants produced using the methods of the present disclosure express efficiently in a cell. As described herein, a loss-of function CCR5 variant may have reduced activity or levels (e.g., the CCR5 variant may not be folded correctly, may not be transported to the membrane, may demonstrate reduced binding to a ligand including RANTES, ΜΙΡ-Ιβ, or MIP-la, may demonstrate reduced transduction of signals through the G-proteins, or may have a reduced interaction with HIV) compared to a wild type CCR5 protein. For example, the activity or levels of a loss-of-function CCR5 variant may be reduced by at least 20%, at least 30%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, at least 99%, or more. In some embodiments, the loss-of-function CCR5 variant has no more than 50%, no more than 40%, no more than 30%, no more than 20%, no more than 10%, no more than 5%, no more than 1%, or less activity (e.g., the CCR5 variant may not be folded correctly, may not be transported to the membrane, may demonstrate reduced binding to a ligand including RANTES, ΜΙΡ-Ιβ, or MIP-la, may demonstrate reduced transduction of signals through the G-proteins, or may have a reduced interaction with HIV) compared to a wild type CCR5 protein. In other embodiments, the loss-of-function CCR5 variant inhibits the spread of HIV infection from cell to cell either in vitro or in vivo by more than 90%, more than 80%, more than 70%, more than 60%, more than 50%, more than 40%, more than 30%, more than 20%,
or more than 10% compared to a wild type CCR5 protein. Non-limiting, exemplary assays for determining CCR5 activity may be demonstrated by any known methodology, such as the assay for chemokine binding as disclosed by Van Riper et ah, J. Exp. Med., Ill , 851-856 (1993), which may be readily adapted for measurement of CCR5 binding, which is incorporated herein by reference. Non-limiting, exemplary assays for determining inhibition of the spread of HIV infection between cells may be demonstrated by methods known in the art, such as the HIV quantitation assay disclosed by Nunberg, et ah, J. Virology, 65 (9), 4887-4892 (1991).
[00115] To change the CCR5 gene, the nucleobase editor interacts with the CCR5 gene
(a polynucleotide molecule), wherein the nucleobase editor binds to its target sequence and edits the desired nucleobase. For example, the nucleobase editor may be expressed in a cell where CCR5 gene editing is desired {e.g., macrophages, dendritic cells, and memory T cells of the immune system; endothelial cells, epithelial cells, vascular smooth muscle cells, and fibroblasts; and microglia, neurons, and astrocytes in the central nervous system), to thereby allowing interaction of the CCR5 gene with the nucleobase editor. In some embodiments, the binding of the nucleobase editor to its target sequence in the CCR5 is mediated by a guide nucleotide sequence, e.g., a polynucleotide comprising a nucleotide sequence that is complementary to one of the strands of the target sequence in the CCR5 gene. Thus, by designing the guide nucleotide sequence, the nucleobase editor may be programmed to edit any specific target base in the CCR5 gene. In some embodiments, the guide nucleotide sequence is co-expressed with the nucleobase editor in a cell where editing is desired.
Codon Change
[00116] Using the nucleobase editors described herein, several amino acid codons may be converted to a different codon via deamination of a target base within the codon. For example, in some embodiments, a cytosine (C) base is converted to a thymine (T) base via deamination by a nucleobase editor comprising a cytosine deaminase domain {e.g.,
APOBEC1 or AID). As it is familiar to one skilled in the art, conversion of a base in an amino acid codon may lead to a change of the encoded amino acid in the protein product. Cytosine deaminases are capable of converting a cytosine (C) base to a deoxyuridine (dU) base via deamination, which is replicated as a thymine (T). Thus, it is envisioned that, for amino acid codons containing a C base, the C base may be converted to T in the CCR5 gene. For example, leucine codon (CTC) may be changed to a TTC (phenylalanine) codon via the deamination of the first C on the coding strand. For amino acid codons that contains a
guanine (G) base, a C base is present on the complementary strand; and the G base may be converted to an adenosine (A) via the deamination of the C on the complementary strand. For example, a ATG (Met/M) codon may be converted to a ATA (Ile/I) codon via the deamination of the third C on the complementary strand. In some embodiments, two C to T changes are required to convert a codon to a different codon. Non-limiting examples of possible mutations that may be made in a CCR5-encoding polynucleotide by the nucleobase editors of the present disclosure in order to produce novel CCR5 variants are summarized in Table 7.
[00117] In some embodiments, to bind to its target sequence and edit the desired base, the nucleobase editor depends on its guide nucleotide sequence (e.g., a guide RNA). In some embodiments, the guide nucleotide sequence is a gRNA sequence. An gRNA typically comprises a tracrRNA framework allowing for Cas9 binding, and a guide sequence, which confers sequence specificity to fusion proteins disclosed herein. In some embodiments, the guide RNA comprises a structure 5 '-[guide sequence] - guuuuagagcuagaaauagcaaguuaaaauaaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuu uuu-3' (SEQ ID NO: 330), wherein the guide sequence comprises a sequence that is complementary to the target sequence. In some embodiments, the guide RNA comprises a structure 5 '-[guide sequence] - guuuuaguacucuggaaacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuu uuu -3' (SEQ ID NO: 331), wherein the guide sequence comprises a sequence that is complementary to the target sequence. The guide sequence is typically 20 nucleotides long. For example, the guide sequence may be 15-25 nucleotides long. In certain embodiments, the guide sequence may be 15-20 or 20-25 nucleotides long. In some embodiments, the guide sequence is 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 nucleotides long. Such suitable guide RNA sequences typically comprise guide sequences that are complementary to a nucleic sequence within 50 nucleotides upstream or downstream of the target nucleotide to be edited. In certain embodiments, the tracerRNA sequence may be
guuuuagagcuagaaauagcaaguuaaaauaaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuu uuu (SEQ ID NO: 330) or
guuuuaguacucuggaaacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuu uuu (SEQ ID NO: 331) or may have greater than or equal to 80% homology (e.g., greater than or equal to 80%, greater than or equal to 81%, greater than or equal to 82%, greater than or equal to 83%, greater than or equal to 84%, greater than or equal to 85%, greater than or equal to 86%, greater than or equal to 87%, greater than or equal to 88%, greater than or
equal to 89%, greater than or equal to 90%, greater than or equal to 91%, greater than or equal to 92%, greater than or equal to 93%, greater than or equal to 94%, greater than or equal to 95%, greater than or equal to 96%, greater than or equal to 97%, greater than or equal to 98%, or greater than or equal to 99% homology) with one of these sequences.
[00118] Guide sequences that may be used to target the nucleobase editor to its target sequence to induce specific mutations are provided in Tables 3-5 and 8-10. The mutations and guide sequences presented herein are for illustration purpose only and are not meant to be limiting.
[00119] In some embodiments, cellular CCR5 activity may be reduced by reducing the level of properly folded, active CCR5 protein displayed on the surface of cells. Introducing destabilizing mutations into the wild type CCR5 protein may cause misfolding or
deactivation of the protein, lack of maturation or glycosylation, or enhanced recycling by the vesicular system. A CCR5 variant comprising one or more destabilizing mutations described herein may have reduced levels or activity compared to the wild type CCR5 protein (e.g., the CCR5 variant may not be folded correctly, may not be transported to the membrane, may demonstrate reduced binding to a ligand including RANTES, ΜΙΡ-Ιβ, or MIP-la, may demonstrate reduced transduction of signals through the G-proteins, or may have a reduced interaction with HIV). For example, the levels or activity of a CCR5 variant comprising one or more destabilizing mutations described herein may be reduced by at least about 20%, at least about 30%, at least about 40%, at least about 50%, at least about 60%, at least about 70%, at least about 80%, at least about 90%, at least about 95%, at least about 99%, or more.
[00120] The present disclosure further provides mutations that cause misfolding of
CCR5 protein or structural destabilization of the CCR5 protein. Non-limiting, exemplary destabilizing CCR5 mutations that may be made using the methods described herein are shown in Table 1.
[00121] In some embodiments, CCR5 variants comprising more than one mutation described herein are contemplated. For example, a CCR5 variant may be produced using the methods described herein that include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, or more mutations selected from Tables 1-10. To make multiple mutations in the CCR5 gene, a plurality of guide nucleotide sequences may be used, each guide nucleotide sequence targeting one specific base. The nucleobase editor is capable of editing the base dictated by the guide nucleotide sequence. For example, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, or more guide nucleotide sequences may be used in a gene editing process. In some embodiments, the guide nucleotide sequences are RNAs (e.g., gRNA). In some embodiments, the guide nucleotide sequences are single
stranded DNA molecules.
Premature Stop Codons
[00122] Some aspects of the present disclosure provide strategies of editing CCR5 gene to reduce the amount of full-length, functional CCR5 protein being produced. In some embodiments, stop codons may be introduced into the coding sequence of CCR5 gene upstream of the normal stop codon (referred to as a "premature stop codon"). Premature stop codons cause premature translation termination, in turn resulting in truncated and nonfunctional proteins and induces rapid degradation of the mRNA via the non- sense mediated mRNA decay pathway. See, e.g., Baker et ah, Current Opinion in Cell Biology 16 (3): 293- 299, 2004; Chang et ah, Annual Review of Biochemistry 76: 51-74, 2007; and Behm- Ansmant et ah, Genes & Development 20 (4): 391-398, 2006, each of which is incorporated herein by reference.
[00123] The nucleobase editors described herein may be used to convert certain amino acid codons to a stop codon {e.g., TAA, TAG, or TGA). For example, nucleobase editors including a cytosine deaminase domain are capable of converting a cytosine (C) base to a thymine (T) base via deamination. Thus, it is envisioned that, for amino acid codons containing a C base, the C base may be converted to T. For example, a CAG (Gln/Q) codon may be changed to a TAG (amber) codon via the deamination of the first C on the coding strand. For sense codons that contain a guanine (G) base, a C base is present on the complementary strand; and the G base may be converted to an adenosine (A) via the deamination of the C on the complementary strand. For example, a TGG (Trp/W) codon may be converted to a TAG (amber) codon via the deamination of the second C on the
complementary strand. In some embodiments, two C to T changes are required to convert a codon to a nonsense codon. For example, a CGG (R) codon is converted to a TAG (amber) codon via the deamination of the first C on the coding strand and the deamination of the second C on the complementary strand. Non-limiting examples of the codon changes contemplated herein are provided in Tables 5, 6, and 10.
[00124] Accordingly, the present disclosure provides non-limiting examples of amino acid codons that may be converted to premature stop codons in the CCR5 gene. In some embodiments, the introduction of stop codons may be efficacious in generating truncations when the target residue is located in a flexible loop. In some embodiments, two codons adjacent to each other may both be converted to stop codons by the action of the cytidine deaminase, resulting in two stop codons adjacent to each other (also referred to as "tandem
stop codons"). "Adjacent" means there are no more than 5 amino acids between the two stop codons. For example, the two stop codons may be immediately adjacent to each other (0 amino acids in between) or have 1, 2, 3, 4, or 5 amino acids in between. The introduction of tandem stop codons may be especially efficacious in generating truncation and nonfunctional CCR5 variants. As a non-limiting example, the tandem stop codons may be: Q186X/Q188X, Q277X/Q288X, Q328X/Q329X, Q329X/R334X, or R341X/Q346X.
Target Base in Non-coding Region of CCR5 gene splicing variants
[00125] Some aspects of the present disclosure provide strategies of reducing cellular
CCR5 activity via preventing CCR5 mRNA maturation and production. In some
embodiments, such strategies involve alterations of splicing sites in the CCR5 gene. Altered splicing site may lead to altered splicing and maturation of the CCR5 mRNA. For example, in some embodiments, an altered splicing site may lead to the skipping of an exon, in turn leading to a truncated protein product or an altered reading frame. In some embodiments, an altered splicing site may lead to translation of an intron sequence and premature translation termination when an inframe stop codon is encountered by the translating ribosome in the intron. In some embodiments, a start codon is edited and protein translation initiates at the next ATG codon, which may not be in the correct coding frame.
[00126] The splicing site typically comprises an intron donor site, a Lariat branch point, and an intron acceptor site. The mechanisms of splicing are familiar to those skilled in the art. As illustrated in Table 2, the intron donor site may have a consensus sequence of GGGTRAGT, and the C bases paired with the G bases in the intron donor site consensus sequence may be targeted by a nucleobase editor described herein, thereby altering the intron donor site. The Lariat branch point also has consensus sequences, e.g., TTGTA. The C base paired with the G base in the Lariat branch point consensus sequence may be targeted by a nucleobase editor described herein, leading to the skipping of the following exon. The intron acceptor site has a consensus sequence of YACAGG, wherein Y is a pyrimidine. The C base of the consensus sequence of the intron acceptor site, and the C base paired with the G bases in the consensus sequence of the intron acceptor site may be targeted by a nucleobase editor described herein, thereby altering the intron acceptor site, in turn leading to the skipping of an exon. General strategies of altering intron-exon junctions and the start site to produce a nonfunctional CCR5 protein, mimicking the HIV protective effect of the CCR5-A32 allele are described in Table 2.
[00127] In some embodiments, a splicing site in the CCR5-coding sequence (e.g., the
CCR5 gene in the genome) is altered by a programmable nuclease. The use of a programmable nuclease (e.g., TALE, ZFN, WT Cas9, or dCas9-FokI fusion protein) in generating indels in a target sequence has been described in the art, e.g., in Maeder, et al., Mol. Cell 31 (2): 294-301, 2008; Carroll et al, Genetics Society of America, 188 (4): 773- 782, 2011; Miller et al, Nature Biotechnology 25 (7): 778-785, 2007; Christian et al, Genetics 186 (2): 757-61, 2008; Li et al, Nucleic Acids Res 39 (1): 359-372, 2010; and Moscou et al., Science 326 (5959): 1501, 2009, Guilinger et al., Nature Biotechnology 2014, 32 (6), 577-82, PCT Application Publication WO 2015/089427, US Patent Application Publication US 2016-0153003, and US 2015-0291965, the each of which is incorporated herein by reference.
[00128] An "indel" refers to bases inserted or deleted in the DNA of an organism, e.g., the genomic DNA of an organism. An indel may be generated via a non-homologous end joining (NHEJ) pathway following a double-strand DNA break, e.g., by cleavage of a nuclease. During NHEJ, break ends are directly ligated without the need for a homologous template, in contrast to homology directed repair, and is thus prone to generating indels. An indel that occurs in the coding sequence of a gene, will lead to frameshift mutations if the indel is an insertion or a deletion of one or two bases. An indel that occurs in the noncoding sequence of a gene, e.g., the splicing site, may cause skipping of exons or translation of intron sequences, in turn leading to frameshifting mutations and/or premature translation termination. Thus, provided in Tables 1 and 8 are non-limiting examples of splicing sites that may be targeted via programmable nucleases, e.g., WT Cas9 or dCas9-FokI fusion protein, and the guide sequences that may be used for each target site.
CCR2 Variants
[00129] Certain mutations in the C-C chemokine receptor type 2 (CCR2) have also been shown to protect against HIV infection. Thus, some aspects of the present disclosure provide the generation of loss-of-function variants of CCR2 (e.g., A335V and V64I) using the nucleobase editors and strategies described herein. Non-limiting examples of such variants and the guide sequence that may be used to make them are provided in Table 1.
Wild type CCR2 Gene (>gill83979979lreflNM_001123041.21 Homo sapiens C-C motif chemokine receptor 2 (CCR2), transcript variant A, mRNA, SEQ ID NO: 332)
TTTATTCTCTGGAACATGAAACATTCTGTTGTGCTCATATCATGCAAATTATCACT AGTAGGAGAGCAGAGAGTGGAAATGTTCCAGGTATAAAGACCCACAAGATAAA
GAAGCTCAGAGTCGTTAGAAACAGGAGCAGATGTACAGGGTTTGCCTGACTCAC
ACTCAAGGTTGCATAAGCAAGATTTCAAAATTAATCCTATTCTGGAGACCTCAAC
CCAATGTACAATGTTCCTGACTGGAAAAGAAGAACTATATTTTTCTGATTTTTTTT
TTCAAATCTTTACCATTAGTTGCCCTGTATCTCCGCCTTCACTTTCTGCAGGAAAC
TTTATTTCCTACTTCTGCATGCCAAGTTTCTACCTCTAGATCTGTTTGGTTCAGTTG
CTGAGAAGCCTGACATACCAGGACTGCCTGAGACAAGCCACAAGCTGAACAGAG
AAAGTGGATTGAACAAGGACGCATTTCCCCAGTACATCCACAACATGCTGTCCAC
ATCTCGTTCTCGGTTTATCAGAAATACCAACGAGAGCGGTGAAGAAGTCACCACC
TTTTTTGATTATGATTACGGTGCTCCCTGTCATAAATTTGACGTGAAGCAAATTGG
GGCCCAACTCCTGCCTCCGCTCTACTCGCTGGTGTTCATCTTTGGTTTTGTGGGCA
ACATGCTGGTCGTCCTCATCTTAATAAACTGCAAAAAGCTGAAGTGCTTGACTGA
CATTTACCTGCTCAACCTGGCCATCTCTGATCTGCTTTTTCTTATTACTCTCCCATT
GTGGGCTCACTCTGCTGCAAATGAGTGGGTCTTTGGGAATGCAATGTGCAAATTA
TTCACAGGGCTGTATCACATCGGTTATTTTGGCGGAATCTTCTTCATCATCCTCCT
GACAATCGATAGATACCTGGCTATTGTCCATGCTGTGTTTGCTTTAAAAGCCAGG
ACGGTCACCTTTGGGGTGGTGACAAGTGTGATCACCTGGTTGGTGGCTGTGTTTG
CTTCTGTCCCAGGAATCATCTTTACTAAATGCCAGAAAGAAGATTCTGTTTATGT
CTGTGGCCCTTATTTTCCACGAGGATGGAATAATTTCCACACAATAATGAGGAAC
ATTTTGGGGCTGGTCCTGCCGCTGCTCATCATGGTCATCTGCTACTCGGGAATCCT
GAAAACCCTGCTTCGGTGTCGAAACGAGAAGAAGAGGCATAGGGCAGTGAGAGT
CATCTTCACCATCATGATTGTTTACTTTCTCTTCTGGACTCCCTATAATATTGTCAT
TCTCCTGAACACCTTCCAGGAATTCTTCGGCCTGAGTAACTGTGAAAGCACCAGT
CAACTGGACCAAGCCACGCAGGTGACAGAGACTCTTGGGATGACTCACTGCTGC
ATCAATCCCATCATCTATGCCTTCGTTGGGGAGAAGTTCAGAAGCCTTTTTCACA
TAGCTCTTGGCTGTAGGATTGCCCCACTCCAAAAACCAGTGTGTGGAGGTCCAGG
AGTGAGACCAGGAAAGAATGTGAAAGTGACTACACAAGGACTCCTCGATGGTCG
TGGAAAAGGAAAGTCAATTGGCAGAGCCCCTGAAGCCAGTCTTCAGGACAAAGA
AGGAGCCTAGAGACAGAAATGACAGATCTCTGCTTTGGAAATCACACGTCTGGC
TTCACAGATGTGTGATTCACAGTGTGAATCTTGGTGTCTACGTTACCAGGCAGGA
AGGCTGAGAGGAGAGAGACTCCAGCTGGGTTGGAAAACAGTATTTTCCAAACTA
CCTTCCAGTTCCTCATTTTTGAATACAGGCATAGAGTTCAGACTTTTTTTAAATAG
TAAAAATAAAATTAAAGCTGAAAACTGCAACTTGTAAATGTGGTAAAGAGTTAG
TTTGAGTTACTATCATGTCAAACGTGAAAATGCTGTATTAGTCACAGAGATAATT
CTAGCTTTGAGCTTAAGAATTTTGAGCAGGTGGTATGTTTGGGAGACTGCTGAGT
CAACCCAATAGTTGTTGATTGGCAGGAGTTGGAAGTGTGTGATCTGTGGGCACAT
TAGCCTATGTGCATGCAGCATCTAAGTAATGATGTCGTTTGAATCACAGTATACG
CTCCATCGCTGTCATCTCAGCTGGATCTCCATTCTCTCAGGCTTGCTGCCAAAAGC
CTTTTGTGTTTTGTTTTGTATCATTATGAAGTCATGCGTTTAATCACATTCGAGTG
TTTCAGTGCTTCGCAGATGTCCTTGATGCTCATATTGTTCCCTATTTTGCCAGTGG
GAACTCCTAAATCAAGTTGGCTTCTAATCAAAGCTTTTAAACCCTATTGGTAAAG
AATGGAAGGTGGAGAAGCTCCCTGAAGTAAGCAAAGACTTTCCTCTTAGTCGAG
CCAAGTTAAGAATGTTCTTATGTTGCCCAGTGTGTTTCTGATCTGATGCAAGCAA
GAAACACTGGGCTTCTAGAACCAGGCAACTTGGGAACTAGACTCCCAAGCTGGA
CTATGGCTCTACTTTCAGGCCACATGGCTAAAGAAGGTTTCAGAAAGAAGTGGG
GACAGAGCAGAACTTTCACCTTCATATATTTGTATGATCCTAATGAATGCATAAA
ATGTTAAGTTGATGGTGATGAAATGTAAATACTGTTTTTAACAACTATGATTTGG
AAAATAAATCAATGCTATAACTATGTTGAAAAAAAAAAAAAAAAAA
Wild type CCR2 Gene, transcript variant B (>gill83979981lreflNM_001123396.11 Homo sapiens C-C motif chemokine receptor 2 (CCR2), transcript variant B, mRNA, SEQ ID NO: 333)
TTTATTCTCTGGAACATGAAACATTCTGTTGTGCTCATATCATGCAAATTATCACT
AGTAGGAGAGCAGAGAGTGGAAATGTTCCAGGTATAAAGACCCACAAGATAAA
GAAGCTCAGAGTCGTTAGAAACAGGAGCAGATGTACAGGGTTTGCCTGACTCAC
ACTCAAGGTTGCATAAGCAAGATTTCAAAATTAATCCTATTCTGGAGACCTCAAC
CCAATGTACAATGTTCCTGACTGGAAAAGAAGAACTATATTTTTCTGATTTTTTTT
TTCAAATCTTTACCATTAGTTGCCCTGTATCTCCGCCTTCACTTTCTGCAGGAAAC
TTTATTTCCTACTTCTGCATGCCAAGTTTCTACCTCTAGATCTGTTTGGTTCAGTTG
CTGAGAAGCCTGACATACCAGGACTGCCTGAGACAAGCCACAAGCTGAACAGAG
AAAGTGGATTGAACAAGGACGCATTTCCCCAGTACATCCACAACATGCTGTCCAC
ATCTCGTTCTCGGTTTATCAGAAATACCAACGAGAGCGGTGAAGAAGTCACCACC
TTTTTTGATTATGATTACGGTGCTCCCTGTCATAAATTTGACGTGAAGCAAATTGG
GGCCCAACTCCTGCCTCCGCTCTACTCGCTGGTGTTCATCTTTGGTTTTGTGGGCA
ACATGCTGGTCGTCCTCATCTTAATAAACTGCAAAAAGCTGAAGTGCTTGACTGA
CATTTACCTGCTCAACCTGGCCATCTCTGATCTGCTTTTTCTTATTACTCTCCCATT
GTGGGCTCACTCTGCTGCAAATGAGTGGGTCTTTGGGAATGCAATGTGCAAATTA
TTCACAGGGCTGTATCACATCGGTTATTTTGGCGGAATCTTCTTCATCATCCTCCT
GACAATCGATAGATACCTGGCTATTGTCCATGCTGTGTTTGCTTTAAAAGCCAGG
ACGGTCACCTTTGGGGTGGTGACAAGTGTGATCACCTGGTTGGTGGCTGTGTTTG
CTTCTGTCCCAGGAATCATCTTTACTAAATGCCAGAAAGAAGATTCTGTTTATGT
CTGTGGCCCTTATTTTCCACGAGGATGGAATAATTTCCACACAATAATGAGGAAC
ATTTTGGGGCTGGTCCTGCCGCTGCTCATCATGGTCATCTGCTACTCGGGAATCCT
GAAAACCCTGCTTCGGTGTCGAAACGAGAAGAAGAGGCATAGGGCAGTGAGAGT
CATCTTCACCATCATGATTGTTTACTTTCTCTTCTGGACTCCCTATAATATTGTCAT
TCTCCTGAACACCTTCCAGGAATTCTTCGGCCTGAGTAACTGTGAAAGCACCAGT
CAACTGGACCAAGCCACGCAGGTGACAGAGACTCTTGGGATGACTCACTGCTGC
ATCAATCCCATCATCTATGCCTTCGTTGGGGAGAAGTTCAGAAGGTATCTCTCGG
TGTTCTTCCGAAAGCACATCACCAAGCGCTTCTGCAAACAATGTCCAGTTTTCTA
CAGGGAGACAGTGGATGGAGTGACTTCAACAAACACGCCTTCCACTGGGGAGCA
GGAAGTCTCGGCTGGTTTATAAAACGAGGAGCAGTTTGATTGTTGTTTATAAAGG
GAGATAACAATCTGTATATAACAACAAACTTCAAGGGTTTGTTGAACAATAGAA
ACCTGTAAAGCAGGTGCCCAGGAACCTCAGGGCTGTGTGTACTAATACAGACTA
TGTCACCCAATGCATATCCAACATGTGCTCAGGGAATAATCCAGAAAAACTGTG
GGTAGAGACTTTGACTCTCCAGAAAGCTCATCTCAGCTCCTGAAAAATGCCTCAT
TACCTTGTGCTAATCCTCTTTTTCTAGTCTTCATAATTTCTTCACTCAATCTCTGAT
TCTGTCAATGTCTTGAAATCAAGGGCCAGCTGGAGGTGAAGAAGAGAATGTGAC
AGGCACAGATGAATGGGAGTGAGGGATAGTGGGGTCAGGGCTGAGAGGAGAAG
GAGGGAGACATGAGCATGGCTGAGCCTGGACAAAGACAAAGGTGAGCAAAGGG
CTCACGCATTCAGCCAGGAGATGATACTGGTCCTTAGCCCCATCTGCCACGTGTA
TTTAACCTTGAAGGGTTCACCAGGTCAGGGAGAGTTTGGGAACTGCAATAACCTG
GGAGTTTTGGTGGAGTCCGATGATTCTCTTTTGCATAAGTGCATGACATATTTTTG
CTTTATTACAGTTTATCTATGGCACCCATGCACCTTACATTTGAAATCTATGAAAT
ATCATGCTCCATTGTTCAGATGCTTCTTAGGCCACATCCCCCTGTCTAAAAATTCA
GAAAATTTTTGTTTATAAAAGA
Human CCR2 isoform A, Amino Acid Sequence (>gill83979980lreflNP_001116513.21 C-C chemokine receptor type 2 isoform A [Homo sapiens], SEQ ID NO: 334)
MLS TS RS RFIRNTNES GEE VTTFFD YD YG APCHKFD VKQIG AQLLPPLYS LVFIFGF VG
NMLVVLILINCKKLKCLTDIYLLNLAISDLLFLITLPLWAHSAANEWVFGNAMCKLFT
GLYHIG YFGGIFFIILLTIDR YLAIVH A VFALKART VTFG V VTS VITWLV A VF AS VPGII
FTKCQKEDSVYVCGPYFPRGWNNFHTIMRNILGLVLPLLIMVICYSGILKTLLRCRNE
KKRHRAVRVIFTIMIVYFLFWTPYNIVILLNTFQEFFGLSNCESTSQLDQATQVTETLG
MTHCCINPIIYAFVGEKFRSLFHIALGCRIAPLQKPVCGGPGVRPGKNVKVTTQGLLD GRGKGKSIGRAPEASLQDKEGA
Human CCR2 isoform B, Amino Acid Sequence (>gill83979982lreflNP_001116868.11 C-C chemokine receptor type 2 isoform B [Homo sapiens], SEQ ID NO: 335)
MLS TS RS RFIRNTNES GEE VTTFFD YD YG APCHKFD VKQIG AQLLPPLYS LVFIFGF VG
NMLVVLILINCKKLKCLTDIYLLNLAISDLLFLITLPLWAHSAANEWVFGNAMCKLFT
GLYHIG YFGGIFFIILLTIDR YLAIVH A VFALKART VTFG V VTS VITWLV A VF AS VPGII
FTKCQKEDSVYVCGPYFPRGWNNFHTIMRNILGLVLPLLIMVICYSGILKTLLRCRNE
KKRHRAVRVIFTIMIVYFLFWTPYNIVILLNTFQEFFGLSNCESTSQLDQATQVTETLG
MTHCCINPIIYAFVGEKFRRYLSVFFRKHITKRFCKQCPVFYRETVDGVTSTNTPSTGE
QEVSAGL
Mouse CCR2 Amino Acid Sequence (>gil6753466lreflNP_034045.1l C-C chemokine receptor type 2 [Mus musculus], SEQ ID NO: 336)
MEDNNMLPQFIHGILS TS HS LFTRS IQELDEG ATTP YD YDD GEPCHKTS VKQIG A WIL
PPLYS LVFIFGFVGNMLVIIILIGCKKLKS MTDIYLLNLAIS DLLFLLTLPFW AH Y A ANE
WVFGNIMCKVFTGLYHIGYFGGIFFIILLTIDRYLAIVHAVFALKARTVTFGVITSVVT
WVVAVFASLPGIIFTKSKQDDHHYTCGPYFTQLWKNFQTIMRNILSLILPLLVMVICY
SGILHTLFRCRNEKKRHRAVRLIFAIMIVYFLFWTPYNIVLFLTTFQESLGMSNCVIDK
HLDQAMQVTETLGMTHCCINPVIYAFVGEKFRRYLSIFFRKHIAKRLCKQCPVFYRE
T ADR VS S TFTPS TGEQE VS VGL
Rat CCR2 Amino Acid Sequence (>gill l l77914 Iref INP_068638.11 C-C chemokine receptor type 2 [Rattus norvegicus], SEQ ID NO: 337)
MEDS NMLPQFIHGILS TS HS LFPRS IQELDEG ATTP YD YDDGEPCHKTS VKQIG A WILP
PLYSLVFIFGFVGNMLVIIILISCKKLKSMTDIYLFNLAISDLLFLLTLPFWAHYAANE
WVFGNIMCKLFTGLYHIGYFGGIFFIILLTIDRYLAIVHAVFALKARTVTFGVITSVVT
WVVAVFASLPGIIFTKSEQEDDQHTCGPYFPTIWKNFQTIMRNILSLILPLLVMVICYS
GILHTLFRCRNEKKRHRAVRLIFAIMIVYFLFWTPYNIVLFLTTFQEFLGMSNCVVDM
HLDQAMQVTETLGMTHCCVNPIIYAFVGEKFRRYLSIFFRKHIAKNLCKQCPVFYRE
T ADR VS S TFTPS TGEQE VS VGL
[00130] In some embodiments, simultaneous introduction of loss-of-function
mutations into more than one protein factor affecting HIV infection are provided. For example, in some embodiments, a loss-of-function mutation may be simultaneously introduced into CCR5 and CCR2. In some embodiments to simultaneously introduce loss-of- function mutations into more than one protein, multiple guide nucleotide sequences are used. In some embodiments a guide nucleotide matching both gene sequences is used to
simultaneously introduce loss-of-function mutations into more than one protein. In some embodiements a guide nucleotide partially matching one or both of the gene sequences is used to simultaneously introduce loss-of-function mutations into more than one protein, wherein one to four mistmatches are allowed between the guide RNA and a target sequence.
[00131] Further provided herein are the generation of novel and uncharacterized mutations in any of the protein factors involved in HIV infection. For example, libraries of guide nucleotide sequences may be designed for all possible PAM sequences in the genomic site of these protein factors, and used to generate mutations in these proteins. The function of the protein variants may be evaluated. If a loss-of-function variant is identified, the specific gRNA used for making the mutation may be identified via sequencing of the edited genomic site, e.g., via DNA deep sequencing.
Nucleobase editors
[00132] The methods of generating loss-of-function CCR5 variants described herein are enabled by the use of the nucleobase editors. As described herein, a nucleobase editor is a fusion protein comprising: (i) a programmable DNA binding protein domain; and (ii) a deaminase domain. It is to be understood that any programmable DNA binding domain may be used in the base editors.
[00133] In some embodiments, the programmable DNA binding protein domain comprises the DNA binding domain of a zinc finger nuclease (ZFN) or a transcription activator- like effector domain (TALE). In some embodiments, the programmable DNA binding protein domain may be programmed by a guide nucleotide sequence and is thus referred as a "guide nucleotide sequence-programmable DNA binding-protein domain." In some embodiments, the guide nucleotide sequence-programmable DNA binding protein is a nuclease inactive Cas9, or dCas9. A dCas9, as used herein, encompasses a Cas9 that is completely inactive in its nuclease activity, or partially inactive in its nuclease activity (e.g., a Cas9 nickase). Thus, in some embodiments, the guide nucleotide sequence-programmable DNA binding protein is a Cas9 nickase. In some embodiments, the guide nucleotide sequence-programmable DNA binding protein is a nuclease inactive Cpf 1. In some
embodiments, the guide nucleotide sequence-programmable DNA binding protein is a nuclease inactive Argonaute.
[00134] In some embodiments, the guide nucleotide sequence-programmable DNA binding protein is a dCas9 domain. In some embodiments, the guide nucleotide sequence- programmable DNA binding protein is a Cas9 nickase. In some embodiments, the dCas9 domain comprises an amino acid sequence of SEQ ID NO: 2 or SEQ ID NO: 3. In some embodiments, the dCas9 domain comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of the Cas9 domains provided herein (e.g., SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682), and comprises mutations
corresponding to D10X (X is any amino acid except for D) and/or H840X (X is any amino acid except for H) in SEQ ID NO: 1. In some embodiments, the dCas9 domain comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of the Cas9 domains provided herein (e.g., SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682), and comprises mutations corresponding to D10A and/or H840A in SEQ ID NO: 1. In some embodiments, the Cas9 nickase comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of the Cas9 domains provided herein (e.g., SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682), and comprises mutations corresponding to D10X (X is any amino acid except for D) in SEQ ID NO: 1 and a histidine at a position correspond to position 840 in SEQ ID NO: 1. In some embodiments, the Cas9 nickase comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of the Cas9 domains provided herein (e.g., SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682), and comprises mutations corresponding to D10A in SEQ ID NO: 1 and a histidine at a position correspond to position 840 in SEQ ID NO: 1. In some embodiments, variants or homologues of dCas9 or Cas9 nickase (e.g., variants of SEQ ID NO: 2 or SEQ ID NO: 3, respectively) are provided which are at least about 70% identical, at least about 80% identical, at least about 90% identical, at least about 95% identical, at least
about 98% identical, at least about 99% identical, at least about 99.5% identical, or at least about 99.9% identical to SEQ ID NO: 2 or SEQ ID NO: 3, respectively, and comprises mutations corresponding to D10A and/or H840A in SEQ ID NO: 1. In some embodiments, variants of Cas9 (e.g., variants of SEQ ID NO: 2) are provided having amino acid sequences which are shorter, or longer than SEQ ID NO: 2, by about 5 amino acids, by about 10 amino acids, by about 15 amino acids, by about 20 amino acids, by about 25 amino acids, by about 30 amino acids, by about 40 amino acids, by about 50 amino acids, by about 75 amino acids, by about 100 amino acids, or more, provided that the dCas9 variants comprise mutations corresponding to D10A and/or H840A in SEQ ID NO: 1. In some embodiments, variants of Cas9 nickase (e.g., variants of SEQ ID NO: 3) are provided having amino acid sequences which are shorter, or longer than SEQ ID NO: 3, by about 5 amino acids, by about 10 amino acids, by about 15 amino acids, by about 20 amino acids, by about 25 amino acids, by about 30 amino acids, by about 40 amino acids, by about 50 amino acids, by about 75 amino acids, by about 100 amino acids, or more, provided that the dCas9 variants comprise mutations corresponding to D10A and comprises a histidine at a position corresponding to position 840 in SEQ ID NO: 1.
[00135] Additional suitable nuclease-inactive dCas9 domains will be apparent to those of skill in the art based on this disclosure and knowledge in the field, and are within the scope of this disclosure. Such additional exemplary suitable nuclease-inactive Cas9 domains include, but are not limited to, D10A/H840A, D10A/D839A/H840A,
D10A/D839A/H840A/N863A mutant domains in SEQ ID NO: 1 (See, e.g., Prashant et al, Nature Biotechnology. 2013; 31(9): 833-838, which is incorporated herein by reference), or K603R (See, e.g., Chavez et ah, Nature Methods 12, 326-328, 2015, which is incorporated herein by reference).
[00136] In some embodiments, the nucleobase editors described herein comprise a
Cas9 domain with decreased electrostatic interactions between the Cas9 domain and a sugar- phosphate backbone of a DNA, as compared to a wild-type Cas9 domain. In some embodiments, a Cas9 domain comprises one or more mutations that decreases the association between the Cas9 domain and a sugar-phosphate backbone of a DNA. In some embodiments, the nucleobase editors described herein comprises a dCas9 (e.g., with D10A and H840A mutations in SEQ ID NO: 1) or a Cas9 nickase (e.g., with D10A mutation in SEQ ID NO: 1), wherein the dCas9 or the Cas9 nickase further comprises one or more of a N497X, a R661X, a Q695X, and/or a Q926X mutation of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the amino acid sequences provided in SEQ ID NOs:
11-260, wherein X is any amino acid. In some embodiments, the nucleobase editors described herein comprises a dCas9 (e.g., with D10A and H840A mutations in SEQ ID NO: 1) or a Cas9 nickase (e.g., with D10A mutation in SEQ ID NO: 1), wherein the dCas9 or the Cas9 nickase further comprises one or more of a N497A, a R661A, a Q695A, and/or a Q926A mutation of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the amino acid sequences provided in SEQ ID NOs: 11-260. In some embodiments, the Cas9 domain (e.g., of any of the nucleobase editors provided herein) comprises the amino acid sequence as set forth in SEQ ID NO: 338. In some embodiments, the nucleobase editor comprises the amino acid sequence as set forth in SEQ ID NO: 339.
Cas9 variant with decreased electrostatic interactions between the Cas9 and DNA backbone
DKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARR
RYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRK
KLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAK
AILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLL
AQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYK
EIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGE
LHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASA
QSFIERMTAFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTN
RKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFE
DREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGALSRKLINGIRDKQSGKTILDFLKSDGFANRNFM
ALIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEM
ARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDIN
RLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFD
NLTKAERGGLSELDKAGFIKRQLVETRAITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFR
KDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATA
KYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTG
GFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERS
SFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASH
YEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIH
LFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO: 338, mutations relative to SEQ ID NO: 1 are bolded and underlined)
High fidelity nucleobase editor (HF-BE3)
MSSETGPVAVDPTLRRRIEPHEFEVFFDPRELRKETCLLYEINWGGRHSIWRHTSQNTNKHVEVNFIEKF TTERYFCPNTRCSITWFLSWSPCGECSRAITEFLSRYPHVTLFIYIARLYHHADPRNRQGLRDLISSGVTI QIMTEQESGYCWRNFVNYSPSNEAHWPRYPHLWVRLYVLELYCIILGLPPCLNILRRKQPQLTFFTIALQ SCHYQRLPPHILWATGLKSGSETPGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLG
NTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFL
VEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLN
PDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALS
LGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITK
APLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKM
DGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGP
LARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTAFDKNLPNEKVLPKHSLLYEYFTVYN
ELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASL
GTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWG
ALSRKLINGIRDKQSGKTILDFLKSDGFANRNFMALIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGS
PAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEH
PVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKS
DNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRAITKHVAQIL
DSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPK
LESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIV
WDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVA
YSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGR
KRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKR
VILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIH
QSITGLYETRIDLSQLGGD (SEQ ID NO: 339)
[00137] The Cas9 protein recognizes a short motif (PAM motif) within the target DNA sequence, which is required for the Cas9-DNA interaction but that is not determined by complementarity to the guide RNA nucleotide sequence. A "PAM motif or "protospacer adjacent motif," as used herein, refers to a DNA sequence adjacent to the 5'- or Ύ- immediately following the DNA sequence that is complementary to the guide RNA oligonucleotide sequence. Cas9 will not successfully bind to, cleave, or nick the target DNA sequence if it is not followed by an appropriate PAM sequence. Without wishing to be bound by any particular theory, specific amino acid residues in the Cas9 enzyme are responsible for interacting with the bases of the PAM and determine the PAM specificity. Therefore, changes in these residues or nearby residues leads to a different or relaxed PAM specificity. Changing or relaxing the PAM specificity may shift the places where Cas9 can bind on the CCR5 gene sequence, and it may modify the target window available to the fused cytidine deaminase, as it will be apparent to those of skill in the art based on the instant disclosure.
[00138] Wild-type Streptococcus pyogenes Cas9 recognizes a canonical PAM sequence (5'-NGG-3')- Other Cas9 nucleases (e.g., Cas9 from Streptococcus thermophiles, Staphylococcus aureus, Neisseria meningitidis, or Treponema denticolao ) and Cas9 variants
thereof have been described in the art to have different, or more relaxed PAM requirements. For example, in Kleinstiver et al, Nature 523, 481-485, 2015; Klenstiver et al., Nature 529, 490-495, 2016; Ran et al, Nature, Apr 9; 520(7546): 186-191, 2015; Kleinstiver et al, Nat Biotechnol, 33(12): 1293-1298, 2015; Hou et al, Proc Natl Acad Sci U S A, 110(39): 15644-9, 2014; Prykhozhij et al, PLoS One, 10(3): eOl 19372, 2015; Zetsche et al, Cell 163, 759-771, 2015; Gao et al, Nature Biotechnology, doi: 10.1038/nbt.3547, 2016; Want et al, Nature 461, 754-761, 2009; Chavez et al, doi: dx.doi dot org/10.1101/058974; Fagerlund et al, Genome Biol. 2015; 16: 25, 2015; Zetsche et al, Cell, 163, 759-771, 2015; and Swarts et al, Nat Struct Mol Biol, 21(9):743-53, 2014, each of which is incorporated herein by reference.
[00139] Thus, the guide nucleotide sequence-programmable DNA-binding protein of the present disclosure may recognize a variety of PAM sequences including, without limitation PAM sequences that are on the 3 ' or the 5' end of the DNA sequence determined by the guide RNA. For example, the sequence may be: NGG, NGAN, NGNG, NGAG, NGCG, NNGRRT, NGRRN, NNNRRT, NNNGATT, NNAGAAW, NAAAC, TTN, TTTN, and YTN, wherein Y is a pyrimidine, R is a purine, and N is any nucleobase.
[00140] One example of an RNA -programmable DNA-binding protein that has different PAM specificity is Clustered Regularly Interspaced Short Palindromic Repeats from Prevotella and Francisella 1 (Cpfl). Similar to Cas9, Cpfl is also a class 2 CRISPR effector. It has been shown that Cpfl mediates robust DNA interference with features distinct from Cas9. Cpfl is a single RNA-guided endonuclease lacking tracrRNA, and it may utilize a T- rich protospacer-adjacent motif {e.g., TTN, TTTN, or YTN), which is on the 5 '-end of the DNA sequence determined by the guide RNA. Moreover, Cpfl cleaves DNA via a staggered DNA double- stranded break. Out of 16 Cpfl-family proteins, two enzymes from
Acidaminococcus and Lachnospiraceae are shown to have efficient genome-editing activity in human cells.
[00141] Also useful in the present compositions and methods are nuclease-inactive
Cpfl (dCpfl) variants that may be used as a guide nucleotide sequence-programmable DNA- binding protein domain. The Cpfl protein has a RuvC-like endonuclease domain that is similar to the RuvC domain of Cas9 but does not have a HNH endonuclease domain, and the N-terminal of Cpfl does not have the alfa-helical recognition lobe of Cas9. It was shown in Zetsche et al, Cell, 163, 759-771, 2015 (which is incorporated herein by reference) that, the RuvC-like domain of Cpfl is responsible for cleaving both DNA strands and inactivation of the RuvC-like domain inactivates Cpfl nuclease activity. For example, mutations
corresponding to D917A, E1006A, or D1255A in Francisella novicida Cpfl (SEQ ID NO:
340) inactivates Cpf 1 nuclease activity. In some embodiments, the dCpfl of the present disclosure may comprise mutations corresponding to D917A, E1006A, D1255A,
D917A/E1006A, D917A/D1255A, E1006A/D1255A, or D917A/ E1006A/D1255A in SEQ ID NO: 340. In other embodiments, the Cpf 1 nickase of the present disclosure may comprise mutations corresponding to D917A, E1006A, D1255A, D917A/E1006A, D917A/D1255A, E1006A/D1255A, or D917A/ E1006A/D1255A in SEQ ID NO: 340. A Cpfl nickase useful for the embodiments of the instant disclosure may comprise other mutations and/or further mutations known in the field. It is to be understood that any mutations, e.g. , substitution mutations, deletions, or insertions that fully or partially inactivates the RuvC domain of Cpfl may be used in accordance with the present disclosure, and that these mutations of Cpfl may result in, for example, a dCpf 1 or Cpfl nickase.
[00142] Thus, in some embodiments, the guide nucleotide sequence-programmable
DNA binding protein is a nuclease inactive Cpfl (dCpfl). In some embodiments, the dCpfl comprises an amino acid sequence of any one SEQ ID NOs: 340-347. In some embodiments, the dCpfl comprises an amino acid sequence that is at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at ease 99.5% identical to any one of SEQ ID NOs: 340-347, and comprises mutations corresponding to D917A, E1006A, D1255A, D917A/E1006A, D917A/D1255A, E1006A/D1255A, or D917A/ E1006A/D1255A in SEQ ID NO: 340. Cpfl from other bacterial species may also be used in accordance with the present disclosure, as a dCpf 1 or Cpfl nickase.
Wild type Francisella novicida Cpfl (SEQ ID NO: 340) (D917, E1006, and D1255 are bolded and underlined)
MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYH
QFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSE
KFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWT
T YFKGFHENRKN V YS S NDIPTS IIYRIVDDNLPKFLENKAKYES LKD KAPE AIN YEQIK
KDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGEN
TKRKGINE YINLYS QQINDKTLKKYKMS VLFKQILS DTES KS F VID KLEDDS D V VTTM
QSFYEQIA AFKTVEEKSIKETLS LLFDDLKAQKLDLS KIYFKNDKS LTDLS QQVFDD Y
SVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDI
DKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIK
DLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYI
TQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFD
DKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKN
GS PQKG YEKFEFNIEDCRKFIDF YKQS IS KHPE WKDFGFRFS DTQR YNS IDEF YRE VE
NQG YKLTFENIS ES YIDS V VNQGKLYLFQIYNKDFS AYS KGRPNLHTLYWKALFDER
NLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKR
FTEDKFFFHCPITINFKS S GANKFNDEINLLLKEKAND VHILS IDRGERHLA YYTLVDG
KGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQV
VHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEF
DKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESV
SKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKN
HNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQM
RNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRI
KNNQEGKKLNLVIKNEEYFEFVQNRNN
Francisella novicida Cpfl D917A (SEQ ID NO: 341) (A917, E1006, and D1255 are bolded and underlined)
MS IYQEFVNKYS LS KTLRFELIPQGKTLENIKARGLILDDEKRAKD YKKAKQIIDKYH
QFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSE
KFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWT
T YFKGFHENRKN V YS S NDIPTS IIYRIVDDNLPKFLENKAKYES LKD KAPE AIN YEQIK
KDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGEN
TKRKGINE YINLYS QQINDKTLKKYKMS VLFKQILS DTES KS F VID KLEDDS D V VTTM
QSFYEQIA AFKTVEEKSIKETLS LLFDDLKAQKLDLS KIYFKNDKS LTDLS QQVFDD Y
SVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDI
DKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIK
DLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYI
TQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFD
DKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKN
GS PQKG YEKFEFNIEDCRKFIDF YKQS IS KHPE WKDFGFRFS DTQR YNS IDEF YRE VE
NQG YKLTFENIS ES YIDS V VNQGKLYLFQIYNKDFS AYS KGRPNLHTLYWKALFDER
NLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKR
FTEDKFFFHCPITINFKS S GANKFNDEINLLLKEKAND VHILS IARGERHLA YYTLVDG
KGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQV
VHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEF
DKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESV
SKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKN
HNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQM
RNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRI
KNNQEGKKLNLVIKNEEYFEFVQNRNN
Francisella novicida Cpfl E1006A (SEQ ID NO: 342) (D917, A1006, and D1255 are bolded and underlined)
MS IYQEFVNKYS LS KTLRFELIPQGKTLENIKARGLILDDEKRAKD YKKAKQIIDKYH
QFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSE
KFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWT
T YFKGFHENRKN V YS S NDIPTS IIYRIVDDNLPKFLENKAKYES LKD KAPE AIN YEQIK
KDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGEN
TKRKGINE YINLYS QQINDKTLKKYKMS VLFKQILS DTES KS F VID KLEDDS D V VTTM
QSFYEQIA AFKTVEEKSIKETLS LLFDDLKAQKLDLS KIYFKNDKS LTDLS QQVFDD Y
SVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDI
DKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIK
DLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYI
TQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFD
DKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKN
GS PQKG YEKFEFNIEDCRKFIDF YKQS IS KHPE WKDFGFRFS DTQR YNS IDEF YRE VE
NQG YKLTFENIS ES YIDS V VNQGKLYLFQIYNKDFS AYS KGRPNLHTLYWKALFDER
NLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKR
FTEDKFFFHCPITINFKS S GANKFNDEINLLLKEKAND VHILS IDRGERHLA YYTLVDG
KGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQV
VHEIAKLVIEYNAIVVFADLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEF
DKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESV
SKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKN
HNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQM
RNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRI
KNNQEGKKLNLVIKNEEYFEFVQNRNN
Francisella novicida Cpfl D1255A (SEQ ID NO: 343) (D917, E1006, and A1255 are bolded and underlined)
MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYH
QFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSE
KFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWT
T YFKGFHENRKN V YS S NDIPTS IIYRIVDDNLPKFLENKAKYES LKD KAPE AIN YEQIK
KDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGEN
TKRKGINE YINLYS QQINDKTLKKYKMS VLFKQILS DTES KS F VID KLEDDS D V VTTM
QSFYEQIA AFKTVEEKSIKETLS LLFDDLKAQKLDLS KIYFKNDKS LTDLS QQVFDD Y
SVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDI
DKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIK
DLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYI
TQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFD
DKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKN
GS PQKG YEKFEFNIEDCRKFIDF YKQS IS KHPE WKDFGFRFS DTQR YNS IDEF YRE VE
NQG YKLTFENIS ES YIDS V VNQGKLYLFQIYNKDFS AYS KGRPNLHTLYWKALFDER
NLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKR
FTEDKFFFHCPITINFKS S GANKFNDEINLLLKEKAND VHILS IDRGERHLA YYTLVDG
KGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQV
VHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEF
DKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESV
SKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKN
HNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQM
RNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDAAANGAYHIGLKGLMLLGRI
KNNQEGKKLNLVIKNEEYFEFVQNRNN
Francisella novicida Cpfl D917A/E1006A (SEQ ID NO: 344) (A917, A1006, and D1255 are bolded and underlined)
MS IYQEFVNKYS LS KTLRFELIPQGKTLENIKARGLILDDEKRAKD YKKAKQIIDKYH QFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSE KFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWT T YFKGFHENRKN VYS S NDIPTS IIYRIVDDNLPKFLENKAKYES LKD KAPE AIN YEQIK KDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGEN TKRKGINE YINLYS QQINDKTLKKYKMS VLFKQILS DTES KS F VID KLEDDS DV VTTM
QSFYEQIA AFKTVEEKSIKETLS LLFDDLKAQKLDLS KIYFKNDKS LTDLS QQVFDD Y
SVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDI
DKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIK
DLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYI
TQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFD
DKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKN
GS PQKG YEKFEFNIEDCRKFIDF YKQS IS KHPE WKDFGFRFS DTQR YNS IDEF YRE VE
NQG YKLTFENIS ES YIDS V VNQGKLYLFQIYNKDFS AYS KGRPNLHTLYWKALFDER
NLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKR
FTEDKFFFHCPITINFKS S GANKFNDEINLLLKEKAND VHILS IARGERHLA YYTLVDG
KGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQV
VHEIAKLVIEYNAIVVFADLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEF
DKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESV
SKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKN
HNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQM
RNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRI
KNNQEGKKLNLVIKNEEYFEFVQNRNN
Francisella novicida Cpfl D917A/D1255A (SEQ ID NO: 345) (A917, E1006, and A1255 are bolded and underlined)
MS IYQEFVNKYS LS KTLRFELIPQGKTLENIKARGLILDDEKRAKD YKKAKQIIDKYH
QFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSE
KFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWT
T YFKGFHENRKN V YS S NDIPTS IIYRIVDDNLPKFLENKAKYES LKD KAPE AIN YEQIK
KDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGEN
TKRKGINE YINLYS QQINDKTLKKYKMS VLFKQILS DTES KS F VID KLEDDS D V VTTM
QSFYEQIA AFKTVEEKSIKETLS LLFDDLKAQKLDLS KIYFKNDKS LTDLS QQVFDD Y
SVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDI
DKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIK
DLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYI
TQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFD
DKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKN
GS PQKG YEKFEFNIEDCRKFIDF YKQS IS KHPE WKDFGFRFS DTQR YNS IDEF YRE VE
NQG YKLTFENIS ES YIDS V VNQGKLYLFQIYNKDFS AYS KGRPNLHTLYWKALFDER
NLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKR
FTEDKFFFHCPITINFKS S GANKFNDEINLLLKEKAND VHILS IARGERHLA YYTLVDG
KGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQV
VHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEF
DKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESV
SKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKN
HNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQM
RNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDAAANGAYHIGLKGLMLLGRI
KNNQEGKKLNLVIKNEEYFEFVQNRNN
Francisella novicida Cpfl E1006A/D1255A (SEQ ID NO: 346) (D917, A1006, and A1255 are bolded and underlined)
MS IYQEFVNKYS LS KTLRFELIPQGKTLENIKARGLILDDEKRAKD YKKAKQIIDKYH
QFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSE
KFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWT
T YFKGFHENRKN V YS S NDIPTS IIYRIVDDNLPKFLENKAKYES LKD KAPE AIN YEQIK
KDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGEN
TKRKGINE YINLYS QQINDKTLKKYKMS VLFKQILS DTES KS F VID KLEDDS D V VTTM
QSFYEQIA AFKTVEEKSIKETLS LLFDDLKAQKLDLS KIYFKNDKS LTDLS QQVFDD Y
SVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDI
DKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIK
DLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYI
TQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFD
DKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKN
GS PQKG YEKFEFNIEDCRKFIDF YKQS IS KHPE WKDFGFRFS DTQR YNS IDEF YRE VE
NQG YKLTFENIS ES YIDS V VNQGKLYLFQIYNKDFS AYS KGRPNLHTLYWKALFDER
NLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKR
FTEDKFFFHCPITINFKS S GANKFNDEINLLLKEKAND VHILS IDRGERHLA YYTLVDG
KGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQV
VHEIAKLVIEYNAIVVFADLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEF
DKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESV
SKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKN
HNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQM
RNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDAAANGAYHIGLKGLMLLGRI KNNQEGKKLNLVIKNEEYFEFVQNRNN
Francisella novicida Cpfl D917A/E1006A/D1255A (SEQ ID NO: 347) (A917, A1006, and A 1255 are bolded and underlined)
MS IYQEFVNKYS LS KTLRFELIPQGKTLENIKARGLILDDEKRAKD YKKAKQIIDKYH
QFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSE
KFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWT
T YFKGFHENRKN V YS S NDIPTS IIYRIVDDNLPKFLENKAKYES LKD KAPE AIN YEQIK
KDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGEN
TKRKGINE YINLYS QQINDKTLKKYKMS VLFKQILS DTES KS F VID KLEDDS D V VTTM
QSFYEQIA AFKTVEEKSIKETLS LLFDDLKAQKLDLS KIYFKNDKS LTDLS QQVFDD Y
SVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDI
DKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIK
DLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYI
TQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFD
DKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKN
GS PQKG YEKFEFNIEDCRKFIDF YKQS IS KHPE WKDFGFRFS DTQR YNS IDEF YRE VE
NQG YKLTFENIS ES YIDS V VNQGKLYLFQIYNKDFS AYS KGRPNLHTLYWKALFDER
NLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKR
FTEDKFFFHCPITINFKS S GANKFNDEINLLLKEKAND VHILS IARGERHLA YYTLVDG
KGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQV
VHEIAKLVIEYNAIVVFADLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEF
DKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESV
SKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKN
HNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQM
RNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDAAANGAYHIGLKGLMLLGRI
KNNQEGKKLNLVIKNEEYFEFVQNRNN
[00143] In some embodiments, the guide nucleotide sequence-programmable DNA binding protein is a Cpfl protein from a Acidaminococcus species (AsCpfl). Cpfl proteins form Acidaminococcus species have been described previously and would be apparent to the skilled artisan. Exemplary Acidaminococcus Cpfl proteins (AsCpfl) include, without limitation, any of the AsCpfl proteins provided herin.
Wild-type AsCpfl- Residue R912 is indicated in bold underlining and residues 661-667 are indicated in italics and underlining.
TQFEGFTNLYQVSKTLRFELIPQGKTLKHIQEQGFIEEDKARNDHYKELKPIIDRIYKT
YADQCLQLVQLDWENLSAAIDSYRKEKTEETRNALIEEQATYRNAIHDYFIGRTDNL
TDAINKRHAEIYKGLFKAELFNGKVLKQLGTVTTTEHENALLRSFDKFTTYFSGFYE
NRKNVFSAEDISTAIPHRrVQDNFPKFKENCHIFTRLITAVPSLREHFENVKKAIGIFVS
TSIEEVFSFPFYNQLLTQTQIDLYNQLLGGISREAGTEKIKGLNEVLNLAIQKNDETAH
HAS LPHRFIPLFKQILS DRNTLS FILEEFKS DEE VIQS FC KYKTLLRNEN VLET AE ALFN
ELNSIDLTHIFISHKKLETISSALCDHWDTLRNALYERRISELTGKITKSAKEKVQRSLK
HEDINLQEIISAAGKELSEAFKQKTSEILSHAHAALDQPLPTTMLKKQEEKEILKSQLD
SLLGLYHLLDWFAVDESNEVDPEFSARLTGIKLEMEPSLSFYNKARNYATKKPYSVE
KFKLNFQMPTLAS GWD VNKEKNNGAILFVKNGLYYLGIMPKQKGRYKALS FEPTEK
TSEGFDKMYYDYFPDAAKMIPKCSTQLKAVTAHFQTHTTPILLSNNFIEPLEITKEIYD
LNNPEKEPKKFQTAYA^rG Q^GYREALCKWIDFTRDFLSKYTKTTSIDLSSLRPSS
QYKDLGEYYAELNPLLYHISFQRIAEKEIMDAVETGKLYLFQIYNKDFAKGHHGKPN
LHTLYWTGLFSPENLAKTSIKLNGQAELFYRPKSRMKRMAHRLGEKMLNKKLKDQ
KTPIPDTLYQELYDYVNHRLSHDLSDEARALLPNVITKEVSHEIIKDRRFTSDKFFFHV
PITLNYQAANSPS KFNQRVNA YLKEHPETPIIGIDRGERNLIYITVIDS TGKILEQRS LN
TIQQFDYQKKLDNREKERVAARQAWSVVGTIKDLKQGYLSQVIHEIVDLMIHYQAV
VVLENLNFGFKSKRTGIAEKAVYQQFEKMLIDKLNCLVLKDYPAEKVGGVLNPYQL
TDQFTSFAKMGTQSGFLFYVPAPYTSKIDPLTGFVDPFVWKTIKNHESRKHFLEGFDF
LHYDVKTGDFILHFKMNRNLSFQRGLPGFMPAWDIVFEKNETQFDAKGTPFIAGKRI
VPVIENHRFTGRYRDLYPANELIALLEEKGIVFRDGSNILPKLLENDDSHAIDTMVALI
RSVLQMRNSNAATGEDYINSPVRDLNGVCFDSRFQNPEWPMDADANGAYHIALKG
QLLLNHLKESKDLKLQNGISNQDWLAYIQELRN (SEQ ID NO: 684)
AsCpfl (R912A)- Residue A912 is indicated in bold underlining and residues 661-667 are indicated in italics and underlining.
TQFEGFTNLYQVSKTLRFELIPQGKTLKHIQEQGFIEEDKARNDHYKELKPIIDRIYKT
YADQCLQLVQLDWENLSAAIDSYRKEKTEETRNALIEEQATYRNAIHDYFIGRTDNL
TDAINKRHAEIYKGLFKAELFNGKVLKQLGTVTTTEHENALLRSFDKFTTYFSGFYE
NRKNVFSAEDISTAIPHRrVQDNFPKFKENCHIFTRLITAVPSLREHFENVKKAIGIFVS
TSIEEVFSFPFYNQLLTQTQIDLYNQLLGGISREAGTEKIKGLNEVLNLAIQKNDETAH
HAS LPHRFIPLFKQILS DRNTLS FILEEFKS DEE VIQS FC KYKTLLRNEN VLET AE ALFN
ELNSIDLTHIFISHKKLETISSALCDHWDTLRNALYERRISELTGKITKSAKEKVQRSLK
HEDINLQEIISAAGKELSEAFKQKTSEILSHAHAALDQPLPTTMLKKQEEKEILKSQLD
SLLGLYHLLDWFAVDESNEVDPEFSARLTGIKLEMEPSLSFYNKARNYATKKPYSVE
KFKLNFQMPTLAS GWD VNKEKNNGAILFVKNGLYYLGIMPKQKGRYKALS FEPTEK
TSEGFDKMYYDYFPDAAKMIPKCSTQLKAVTAHFQTHTTPILLSNNFIEPLEITKEIYD
LNNPEKEPKKFQTAYA^rG Q^GYREALCKWIDFTRDFLSKYTKTTSIDLSSLRPSS
QYKDLGEYYAELNPLLYHISFQRIAEKEIMDAVETGKLYLFQIYNKDFAKGHHGKPN
LHTLYWTGLFSPENLAKTSIKLNGQAELFYRPKSRMKRMAHRLGEKMLNKKLKDQ
KTPIPDTLYQELYDYVNHRLSHDLSDEARALLPNVITKEVSHEIIKDRRFTSDKFFFHV
PITLNYQAANSPS KFNQRVNA YLKEHPETPIIGIDRGEANLIYITVIDS TGKILEQRS LN
TIQQFDYQKKLDNREKERVAARQAWSVVGTIKDLKQGYLSQVIHEIVDLMIHYQAV
VVLENLNFGFKSKRTGIAEKAVYQQFEKMLIDKLNCLVLKDYPAEKVGGVLNPYQL
TDQFTSFAKMGTQSGFLFYVPAPYTSKIDPLTGFVDPFVWKTIKNHESRKHFLEGFDF
LHYDVKTGDFILHFKMNRNLSFQRGLPGFMPAWDIVFEKNETQFDAKGTPFIAGKRI
VPVIENHRFTGRYRDLYPANELIALLEEKGIVFRDGSNILPKLLENDDSHAIDTMVALI
RSVLQMRNSNAATGEDYINSPVRDLNGVCFDSRFQNPEWPMDADANGAYHIALKG
QLLLNHLKESKDLKLQNGISNQDWLAYIQELRN (SEQ ID NO: 686)
[00144] In some embodiments, the guide nucleotide sequence-programmable DNA binding protein is a Cpfl protein from a Lachnospiraceae species (LbCpfl). Cpf 1 proteins form Lachnospiraceae species have been described previously have been described previously and would be apparent to the skilled artisan. Exemplary Lachnospiraceae Cpfl proteins (LbCpfl) include, without limitation, any of the LbCpfl proteins provided herein.
Wild-type LbCpfl - Residues R836 and R1138 is indicated in bold underlining.
MSKLEKFTNCYSLSKTLRFKAIPVGKTQENIDNKRLLVEDEKRAEDYKGVKKLLDRY
YLSFINDVLHSIKLKNLNNYISLFRKKTRTEKENKELENLEINLRKEIAKAFKGNEGYK
SLFKKDIIETILPEFLDDKDEIALVNSFNGFTTAFTGFFDNRENMFSEEAKSTSIAFRCIN
ENLTRYISNMDIFEKVDAIFDKHEVQEIKEKILNSDYDVEDFFEGEFFNFVLTQEGIDV
YNAIIGGFVTESGEKIKGLNEYINLYNQKTKQKLPKFKPLYKQVLSDRESLSFYGEGY
TS DEE VLE VFRNTLNKNS EIFS S IKKLEKLFKNFDE YS S AGIF VKNGP AIS TIS KDIFGE
WNVIRDKWNAEYDDIHLKKKAVVTEKYEDDRRKSFKKIGSFSLEQLQEYADADLSV
VEKLKEIIIQKVDEIYKVYGSSEKLFDADFVLEKSLKKNDAVVAIMKDLLDSVKSFEN
YIKAFFGEGKETNRDESFYGDFVLAYDILLKVDHIYDAIRNYVTQKPYSKDKFKLYF
QNPQFMGGWDKDKETDYRATILRYGSKYYLAIMDKKYAKCLQKIDKDDVNGNYE
KINYKLLPGPNKMLPKVFFSKKWMAYYNPSEDIQKIYKNGTFKKGDMFNLNDCHKL
IDFFKDS IS R YPKWS N A YDFNFS ETEKYKDI AGFYRE VEEQG YKVS FES AS KKE VDKL
VEEGKLYMFQIYNKDFSDKSHGTPNLHTMYFKLLFDENNHGQIRLSGGAELFMRRA
S LKKEELV VHP ANS PI ANKNPDNPKKTTTLS YD V YKD KRFS EDQ YELHIPIAINKCPK
NIFKINTEVRVLLKHDDNPYVIGIDRGERNLLYIVVVDGKGNIVEQYSLNEIINNFNGI
RIKTD YHS LLDKKEKERFE ARQNWTS IENIKELKAGYIS QVVHKICELVEKYD A VIAL
EDLNSGFKNSRVKVEKQVYQKFEKMLIDKLNYMVDKKSNPCATGGALKGYQITNK
FESFKSMSTQNGFIFYIPAWLTSKIDPSTGFVNLLKTKYTSIADSKKFISSFDRIMYVPE
EDLFEFALDYKNFSRTDADYIKKWKLYSYGNRIRIFRNPKKNNVFDWEEVCLTSAYK
ELFNKYGINYQQGDIRALLCEQSDKAFYSSFMALMSLMLQMRNSITGRTDVDFLISP
VKNSDGIFYDSRNYEAQENAILPKNADANGAYNIARKVLWAIGQFKKAEDEKLDKV
KIAIS NKEWLE Y AQTS VKH (SEQ ID NO: 685)
LbCpf 1 (R836A)- Residue A836 is indicated in bold underlining.
MSKLEKFTNCYSLSKTLRFKAIPVGKTQENIDNKRLLVEDEKRAEDYKGVKKLLDRY
YLSFINDVLHSIKLKNLNNYISLFRKKTRTEKENKELENLEINLRKEIAKAFKGNEGYK
SLFKKDIIETILPEFLDDKDEIALVNSFNGFTTAFTGFFDNRENMFSEEAKSTSIAFRCIN
ENLTRYISNMDIFEKVDAIFDKHEVQEIKEKILNSDYDVEDFFEGEFFNFVLTQEGIDV
YNAIIGGFVTESGEKIKGLNEYINLYNQKTKQKLPKFKPLYKQVLSDRESLSFYGEGY
TS DEE VLE VFRNTLNKNS EIFS S IKKLEKLFKNFDE YS S AGIF VKNGP AIS TIS KDIFGE
WNVIRDKWNAEYDDIHLKKKAVVTEKYEDDRRKSFKKIGSFSLEQLQEYADADLSV
VEKLKEIIIQKVDEIYKVYGSSEKLFDADFVLEKSLKKNDAVVAIMKDLLDSVKSFEN
YIKAFFGEGKETNRDESFYGDFVLAYDILLKVDHIYDAIRNYVTQKPYSKDKFKLYF
QNPQFMGGWDKDKETDYRATILRYGSKYYLAIMDKKYAKCLQKIDKDDVNGNYE
KINYKLLPGPNKMLPKVFFSKKWMAYYNPSEDIQKIYKNGTFKKGDMFNLNDCHKL
IDFFKDS IS R YPKWS N A YDFNFS ETEKYKDI AGFYRE VEEQG YKVS FES AS KKE VDKL
VEEGKLYMFQIYNKDFSDKSHGTPNLHTMYFKLLFDENNHGQIRLSGGAELFMRRA
S LKKEELV VHP ANS PI ANKNPDNPKKTTTLS YD V YKD KRFS EDQ YELHIPIAINKCPK
NIFKINTEVRVLLKHDDNPYVIGIDRGEANLLYIVVVDGKGNIVEQYSLNEIINNFNGI
RIKTD YHS LLDKKEKERFE ARQNWTS IENIKELKAGYIS QVVHKICELVEKYD A VIAL
EDLNSGFKNSRVKVEKQVYQKFEKMLIDKLNYMVDKKSNPCATGGALKGYQITNK
FESFKSMSTQNGFIFYIPAWLTSKIDPSTGFVNLLKTKYTSIADSKKFISSFDRIMYVPE
EDLFEFALDYKNFSRTDADYIKKWKLYSYGNRIRIFRNPKKNNVFDWEEVCLTSAYK
ELFNKYGINYQQGDIRALLCEQSDKAFYSSFMALMSLMLQMRNSITGRTDVDFLISP VKNSDGIFYDSRNYEAQENAILPKNADANGAYNIARKVLWAIGQFKKAEDEKLDKV KIAIS NKEWLE Y AQTS VKH (SEQ ID NO: 687)
LbCpfl (R1138A)- Residue A1138 is indicated in bold underlining.
MSKLEKFTNCYSLSKTLRFKAIPVGKTQENIDNKRLLVEDEKRAEDYKGVKKLLDRY
YLSFINDVLHSIKLKNLNNYISLFRKKTRTEKENKELENLEINLRKEIAKAFKGNEGYK
SLFKKDIIETILPEFLDDKDEIALVNSFNGFTTAFTGFFDNRENMFSEEAKSTSIAFRCIN
ENLTRYISNMDIFEKVDAIFDKHEVQEIKEKILNSDYDVEDFFEGEFFNFVLTQEGIDV
YNAIIGGFVTESGEKIKGLNEYINLYNQKTKQKLPKFKPLYKQVLSDRESLSFYGEGY
TS DEE VLE VFRNTLNKNS EIFS S IKKLEKLFKNFDE YS S AGIF VKNGP AIS TIS KDIFGE
WNVIRDKWNAEYDDIHLKKKAVVTEKYEDDRRKSFKKIGSFSLEQLQEYADADLSV
VEKLKEIIIQKVDEIYKVYGSSEKLFDADFVLEKSLKKNDAVVAIMKDLLDSVKSFEN
YIKAFFGEGKETNRDESFYGDFVLAYDILLKVDHIYDAIRNYVTQKPYSKDKFKLYF
QNPQFMGGWDKDKETDYRATILRYGSKYYLAIMDKKYAKCLQKIDKDDVNGNYE
KINYKLLPGPNKMLPKVFFSKKWMAYYNPSEDIQKIYKNGTFKKGDMFNLNDCHKL
IDFFKDS IS R YPKWS N A YDFNFS ETEKYKDI AGFYRE VEEQG YKVS FES AS KKE VDKL
VEEGKLYMFQIYNKDFSDKSHGTPNLHTMYFKLLFDENNHGQIRLSGGAELFMRRA
S LKKEELV VHP ANS PI ANKNPDNPKKTTTLS YD V YKD KRFS EDQ YELHIPIAINKCPK
NIFKINTEVRVLLKHDDNPYVIGIDRGERNLLYIVVVDGKGNIVEQYSLNEIINNFNGI
RIKTD YHS LLDKKEKERFE ARQNWTS IENIKELKAGYIS QVVHKICELVEKYD A VIAL
EDLNSGFKNSRVKVEKQVYQKFEKMLIDKLNYMVDKKSNPCATGGALKGYQITNK
FESFKSMSTQNGFIFYIPAWLTSKIDPSTGFVNLLKTKYTSIADSKKFISSFDRIMYVPE
EDLFEFALDYKNFSRTDADYIKKWKLYSYGNRIRIFRNPKKNNVFDWEEVCLTSAYK
ELFNKYGINYQQGDIRALLCEQSDKAFYSSFMALMSLMLQMANSITGRTDVDFLISP
VKNSDGIFYDSRNYEAQENAILPKNADANGAYNIARKVLWAIGQFKKAEDEKLDKV
KIAIS NKEWLE Y AQTS VKH (SEQ ID NO: 688)
[00145] In some embodiments, the Cpf 1 protein is a crippled Cpfl protein. As used herein a "crippled Cpfl" protein is a Cpfl protein having diminished nuclease activity as compared to a wild-type Cpfl protein. In some embodiments, the crippled Cpfl protein preferentially cuts the target strand more efficiently than the non-target strand. For example, the Cpfl protein preferentially cuts the strand of a duplexed nucleic acid molecule in which a nucleotide to be edited resides. In some embodiments, the crippled Cpfl protein
preferentially cuts the non-target strand more efficiently than the target strand. For example, the Cpf 1 protein preferentially cuts the strand of a duplexed nucleic acid molecule in which a nucleotide to be edited does not reside. In some embodiments, the crippled Cpfl protein preferentially cuts the target strand at least 5% more efficiently than it cuts the non-target strand. In some embodiments, the crippled Cpfl protein preferentially cuts the target strand at least 5%, at least 10%, at least 15%, at least 20%, at least 25%, at least 30%, at least 35%, at least 40%, at least 50%, at least 60%, at least 70%, at least 80%, at least 90%, or at least 100% more efficiently than it cuts the non-target strand.
[00146] In some embodiments, a crippled Cpfl protein is a non-naturally occurring
Cpfl protein. In some embodiments, the crippled Cpfl protein comprises one or more mutations relative to a wild-type Cpfl protein. In some embodiments, the crippled Cpfl protein comprises 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 mutations relative to a wild-type Cpfl protein. In some embodiments, the crippled Cpfl protein comprises an R836A mutation mutation as set forth in SEQ ID NO: 685, or in a corresponding amino acid in another Cpfl protein. It should be appreciated that a Cpfl comprising a homologous residue (e.g., a corresponding amino acid) to R836A of SEQ ID NO: 685 could also be mutated to achieve similar results. In some embodiments, the crippled Cpfl protein comprises a Rl 138A mutation as set forth in SEQ ID NO: 685, or in a corresponding amino acid in another Cpfl protein. In some embodiments, the crippled Cpfl protein comprises an R912A mutation mutation as set forth in SEQ ID NO: 684, or in a corresponding amino acid in another Cpfl protein. Without wishing to be bound by any particular theory, residue R838 of SEQ ID NO: 685 (LbCpfi) and residue R912 of SEQ ID NO: 684 (AsCpfl) are examples of corresponding (e.g., homologous) residues. For example, a portion of the alignment between SEQ ID NO: 684 and 685 shows that R912 and R838 are corresponding residues.
[00147] In some embodiments, any of the Cpfl proteins provided herein comprises one or more amino acid deletions. In some embodiments, any of the Cpfl proteins provided herein comprises 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acid deletions. Without wishing to be bound by any particular theory, there is a helical region in Cpfl, which includes residues 661-667 of AsCpfl (SEQ ID NO: 684), that may obstruct
the function of a deaminase (e.g., APOBEC) that is fused to the Cpfl. This region comprises the amino acid sequence KKTGDQK (SEQ ID NO: 737). Accordingly, aspects of the disclosure provide Cpfl proteins comprising mutations (e.g., deletions) that disrupt this helical region in Cpfl. In some embodiments, the Cpfl protein comprises one or more deletions of the following residues in SEQ ID NO: 684, or one or more corresponding deletions in another Cpfl protein: K661, K662, T663, G664, D665, Q666, and K667. In some embodiments, the Cpfl protein comprises a T663 and a D665 deletion in SEQ ID NO: 684, or corresponding deletions in another Cpfl protein. In some embodiments, the Cpfl protein comprises a K662,T663, D665, and Q666 deletion in SEQ ID NO: 684, or corresponding deletions in another Cpfl protein. In some embodiments, the Cpfl protein comprises a K661, K662, T663, D665, Q666 and K667 deletion in SEQ ID NO: 684, or corresponding deletions in another Cpfl protein.
AsCpfl (deleted T663 and D665)
TQFEGFTNLYQVSKTLRFELIPQGKTLKHIQEQGFIEEDKARNDHYKELKPIIDRIYKT
YADQCLQLVQLDWENLSAAIDSYRKEKTEETRNALIEEQATYRNAIHDYFIGRTDNL
TDAINKRHAEIYKGLFKAELFNGKVLKQLGTVTTTEHENALLRSFDKFTTYFSGFYE
NRKNVFSAEDISTAIPHRIVQDNFPKFKENCHIFTRLITAVPSLREHFENVKKAIGIFVS
TSIEEVFSFPFYNQLLTQTQIDLYNQLLGGISREAGTEKIKGLNEVLNLAIQKNDETAH
HAS LPHRFIPLFKQILS DRNTLS FILEEFKS DEE VIQS FC KYKTLLRNEN VLET AE ALFN
ELNSIDLTHIFISHKKLETISSALCDHWDTLRNALYERRISELTGKITKSAKEKVQRSLK
HEDINLQEIISAAGKELSEAFKQKTSEILSHAHAALDQPLPTTMLKKQEEKEILKSQLD
SLLGLYHLLDWFAVDESNEVDPEFSARLTGIKLEMEPSLSFYNKARNYATKKPYSVE
KFKLNFQMPTLAS GWD VNKEKNNGAILFVKNGLYYLGIMPKQKGRYKALS FEPTEK
TSEGFDKMYYDYFPDAAKMIPKCSTQLKAVTAHFQTHTTPILLSNNFIEPLEITKEIYD
LNNPEKEPKKFQT A YAKKGQKGYRE ALCKWIDFTRDFLS KYTKTTS IDLS SLRPS S Q
YKDLGEYYAELNPLLYHISFQRIAEKEIMDAVETGKLYLFQIYNKDFAKGHHGKPNL
HTLYWTGLFSPENLAKTSIKLNGQAELFYRPKSRMKRMAHRLGEKMLNKKLKDQK
TPIPDTLYQELYDYVNHRLSHDLSDEARALLPNVITKEVSHEIIKDRRFTSDKFFFHVP
ITLNYQAANSPSKFNQRVNAYLKEHPETPIIGIDRGERNLIYITVIDSTGKILEQRSLNTI
QQFDYQKKLDNREKERVAARQAWSVVGTIKDLKQGYLSQVIHEIVDLMIHYQAVV
VLENLNFGFKSKRTGIAEKAVYQQFEKMLIDKLNCLVLKDYPAEKVGGVLNPYQLT
DQFTSFAKMGTQSGFLFYVPAPYTSKIDPLTGFVDPFVWKTIKNHESRKHFLEGFDFL
HYDVKTGDFILHFKMNRNLSFQRGLPGFMPAWDIVFEKNETQFDAKGTPFIAGKRIV
PVIENHRFTGRYRDLYPANELIALLEEKGIVFRDGSNILPKLLENDDSHAIDTMVALIR SVLQMRNSNAATGEDYINSPVRDLNGVCFDSRFQNPEWPMDADANGAYHIALKGQ LLLNHLKES KDLKLQNGIS NQDWLA YIQELRN (SEQ ID NO: 689)
AsCpfl (deleted K662, T663, D665, and Q666)
TQFEGFTNLYQVSKTLRFELIPQGKTLKHIQEQGFIEEDKARNDHYKELKPIIDRIYKT
YADQCLQLVQLDWENLSAAIDSYRKEKTEETRNALIEEQATYRNAIHDYFIGRTDNL
TDAINKRHAEIYKGLFKAELFNGKVLKQLGTVTTTEHENALLRSFDKFTTYFSGFYE
NRKNVFSAEDISTAIPHRrVQDNFPKFKENCHIFTRLITAVPSLREHFENVKKAIGIFVS
TSIEEVFSFPFYNQLLTQTQIDLYNQLLGGISREAGTEKIKGLNEVLNLAIQKNDETAH
HAS LPHRFIPLFKQILS DRNTLS FILEEFKS DEE VIQS FC KYKTLLRNEN VLET AE ALFN
ELNSIDLTHIFISHKKLETISSALCDHWDTLRNALYERRISELTGKITKSAKEKVQRSLK
HEDINLQEIISAAGKELSEAFKQKTSEILSHAHAALDQPLPTTMLKKQEEKEILKSQLD
SLLGLYHLLDWFAVDESNEVDPEFSARLTGIKLEMEPSLSFYNKARNYATKKPYSVE
KFKLNFQMPTLAS GWD VNKEKNNGAILFVKNGLYYLGIMPKQKGRYKALS FEPTEK
TSEGFDKMYYDYFPDAAKMIPKCSTQLKAVTAHFQTHTTPILLSNNFIEPLEITKEIYD
LNNPEKEPKKFQT A YAKGKGYREALCKWIDFTRDFLS KYTKTTS IDLS S LRPS S QYK
DLGEYYAELNPLLYHISFQRIAEKEIMDAVETGKLYLFQIYNKDFAKGHHGKPNLHT
LYWTGLFSPENLAKTSIKLNGQAELFYRPKSRMKRMAHRLGEKMLNKKLKDQKTPI
PDTLYQELYDYVNHRLSHDLSDEARALLPNVITKEVSHEIIKDRRFTSDKFFFHVPITL
NYQAANSPSKFNQRVNAYLKEHPETPIIGIDRGERNLIYITVIDSTGKILEQRSLNTIQQ
FDYQKKLDNREKERVAARQAWSVVGTIKDLKQGYLSQVIHEIVDLMIHYQAVVVLE
NLNFGFKSKRTGIAEKAVYQQFEKMLIDKLNCLVLKDYPAEKVGGVLNPYQLTDQF
TSFAKMGTQSGFLFYVPAPYTSKIDPLTGFVDPFVWKTIKNHESRKHFLEGFDFLHYD
VKTGDFILHFKMNRNLSFQRGLPGFMPAWDIVFEKNETQFDAKGTPFIAGKRIVPVIE
NHRFTGRYRDLYPANELIALLEEKGIVFRDGSNILPKLLENDDSHAIDTMVALIRSVL
QMRNS N A ATGED YINS P VRDLNG VCFDS RFQNPEWPMD AD ANG A YHIALKGQLLL
NHLKESKDLKLQNGISNQDWLA YIQELRN (SEQ ID NO: 690)
AsCpfl (deleted K661, K662, T663,D665, Q666, and K667)
TQFEGFTNLYQVSKTLRFELIPQGKTLKHIQEQGFIEEDKARNDHYKELKPIIDRIYKT YADQCLQLVQLDWENLSAAIDSYRKEKTEETRNALIEEQATYRNAIHDYFIGRTDNL TDAINKRHAEIYKGLFKAELFNGKVLKQLGTVTTTEHENALLRSFDKFTTYFSGFYE NRKNVFSAEDISTAIPHRIVQDNFPKFKENCHIFTRLITAVPSLREHFENVKKAIGIFVS
TSIEEVFSFPFYNQLLTQTQIDLYNQLLGGISREAGTEKIKGLNEVLNLAIQKNDETAH
HAS LPHRFIPLFKQILS DRNTLS FILEEFKS DEE VIQS FC KYKTLLRNEN VLET AE ALFN
ELNSIDLTHIFISHKKLETISSALCDHWDTLRNALYERRISELTGKITKSAKEKVQRSLK
HEDINLQEIISAAGKELSEAFKQKTSEILSHAHAALDQPLPTTMLKKQEEKEILKSQLD
SLLGLYHLLDWFAVDESNEVDPEFSARLTGIKLEMEPSLSFYNKARNYATKKPYSVE
KFKLNFQMPTLAS GWD VNKEKNNGAILFVKNGLYYLGIMPKQKGRYKALS FEPTEK
TSEGFDKMYYDYFPDAAKMIPKCSTQLKAVTAHFQTHTTPILLSNNFIEPLEITKEIYD
LNNPEKEPKKFQT A YAGGYREALCKWIDFTRDFLS KYTKTTS IDLS SLRPS S QYKDLG
EYYAELNPLLYHISFQRIAEKEIMDAVETGKLYLFQIYNKDFAKGHHGKPNLHTLYW
TGLFSPENLAKTSIKLNGQAELFYRPKSRMKRMAHRLGEKMLNKKLKDQKTPIPDTL
YQELYD Y VNHRLS HDLS DE AR ALLPN VITKE VS HEIIKDRRFTS DKFFFH VPITLN YQ
AANSPSKFNQRVNAYLKEHPETPIIGIDRGERNLIYITVIDSTGKILEQRSLNTIQQFDY
QKKLDNREKERVAARQAWSVVGTIKDLKQGYLSQVIHEIVDLMIHYQAVVVLENLN
FGFKSKRTGIAEKAVYQQFEKMLIDKLNCLVLKDYPAEKVGGVLNPYQLTDQFTSFA
KMGTQSGFLFYVPAPYTSKIDPLTGFVDPFVWKTIKNHESRKHFLEGFDFLHYDVKT
GDFILHFKMNRNLSFQRGLPGFMPAWDIVFEKNETQFDAKGTPFIAGKRIVPVIENHR
FTGRYRDLYPANELIALLEEKGIVFRDGSNILPKLLENDDSHAIDTMVALIRSVLQMR
NSNAATGEDYINSPVRDLNGVCFDSRFQNPEWPMDADANGAYHIALKGQLLLNHLK
ESKDLKLQNGISNQDWLAYIQELRN (SEQ ID NO: 691)
[00148] In some embodiments, the guide nucleotide sequence-programmable DNA- binding protein domain of the present disclosure has no requirements for a PAM sequence. One example of such a guide nucleotide sequence-programmable DNA-binding protein may be an Argonaute protein from Natronobacterium gregoryi (NgAgo). NgAgo is a ssDNA- guided endonuclease. NgAgo binds 5' phosphorylated ssDNA of -24 nucleotides (gDNA) to guide it to its target site and will make DNA double-strand breaks at the gDNA site. In contrast to Cas9, the NgAgo-gDNA system does not require a protospacer-adjacent motif (PAM). Using a nuclease inactive NgAgo (dNgAgo) can greatly expand the codons that may be targeted. The characterization and use of NgAgo have been described in Gao et al., Nat Biotechnol., 2016 Jul;34(7):768-73. PubMed PMID: 27136078; Swarts et al., Nature.
507(7491) (2014):258-61; and Swarts et al., Nucleic Acids Res. 43(10) (2015):5120-9, each of which is incorporated herein by reference. The sequence of Natronobacterium gregoryi Argonaute is provided in SEQ ID NO: 348.
Wild type Natronobacterium gregoryi Argonaute (SEQ ID NO: 348)
MTVIDLDSTTTADELTSGHTYDISVTLTGVYDNTDEQHPRMSLAFEQDNGERRYITL
WKNTTPKDVFTYDYATGSTYIFTNIDYEVKDGYENLTATYQTTVENATAQEVGTTD
EDETFAGGEPLDHHLDDALNETPDDAETESDSGHVMTSFASRDQLPEWTLHTYTLT
ATDGAKTDTEYARRTLAYTVRQELYTDHDAAPVATDGLMLLTPEPLGETPLDLDCG
VRVE ADETRTLD YTT AKDRLLARELVEEGLKRS LWDD YLVRGIDE VLS KEPVLTCD
EFDLHERYDLSVEVGHSGRAYLHINFRHRFVPKLTLADIDDDNIYPGLRVKTTYRPR
RGHIVWGLRDECATDSLNTLGNQSVVAYHRNNQTPINTDLLDAIEAADRRVVETRR
QGHGDD A VS FPQELL A VEPNTHQIKQFAS D GFHQQ ARS KTRLS AS RC S EKAQ AF AER
LDPVRLNGSTVEFSSEFFTGNNEQQLRLLYENGESVLTFRDGARGAHPDETFSKGIVN
PPES FE V A V VLPEQQ ADTC KAQWDTM ADLLNQ AG APPTRS ET VQ YD AFS S PES IS LN
VAGAIDPSEVDAAFVVLPPDQEGFADLASPTETYDELKKALANMGIYSQMAYFDRF
RDAKIFYTRNVALGLLAAAGGVAFTTEHAMPGDADMFIGIDVSRSYPEDGASGQINI
AATATAVYKDGTILGHSSTRPQLGEKLQSTDVRDIMKNAILGYQQVTGESPTHIVIHR
DGFMNEDLDPATEFLNEQGVEYDIVEIRKQPQTRLLAVSDVQYDTPVKSIAAINQNEP
RATVATFGAPEYLATRDGGGLPRPIQIERVAGETDIETLTRQVYLLSQSHIQVHNSTA
RLPITTAYADQASTHATKGYLVQTGAFESNVGFL
[00149] In some embodiments, the guide nucleotide sequence-programmable DNA- binding protein is a prokaryotic homolog of an Argonaute protein. Prokaryotic homologs of Argonaute proteins are known and have been described, for example, in Makarova K., et al., "Prokaryotic homologs of Argonaute proteins are predicted to function as key components of a novel system of defense against mobile genetic elements", Biol. Direct. 2009 Aug 25;4:29. doi: 10.1186/1745-6150-4-29, which is incorporated herein by reference. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein is a Marinitoga piezophila Argunaute (MpAgo) protein. The CRISPR-associated Marinitoga piezophila Argonaute (MpAgo) protein cleaves single- stranded target sequences using 57 - phosphorylated guides. The 57 guides are used by all known Argonautes. The crystal structure of an MpAgo-RNA complex shows a guide strand binding site comprising residues that block 57 phosphate interactions. This data suggests the evolution of an Argonaute subclass with noncanonical specificity for a 57 -hydroxylated guide. See, e.g., Kaya et ah, "A bacterial Argonaute with noncanonical guide RNA specificity", Proc Natl Acad Sci U S A. 2016 Apr 12;113(15):4057-62, the entire contents of which are hereby incorporated by
reference). It should be appreciated that other Argonaute proteins may be used in any of the fusion proteins (e.g., base editors) described herein, for example, to guide a deaminase (e.g., cytidine deaminase) to a target nucleic acid (e.g., ssRNA).
[00150] In some embodiments, the guide nucleotide sequence-programmable DNA- binding protein is a single effector of a microbial CRISPR-Cas system. Single effectors of microbial CRISPR-Cas systems include, without limitation, Cas9, Cpfl, C2cl, C2c2, and C2c3. Typically, microbial CRISPR-Cas systems are divided into Class 1 and Class 2 systems. Class 1 systems have multisubunit effector complexes, while Class 2 systems have a single protein effector. Cas9 and Cpfl are Class 2 effectors. In addition to Cas9 and Cpfl, three distinct Class 2 CRISPR-Cas systems (C2cl, C2c2, and C2c3) have been described by Shmakov et ah, "Discovery and Functional Characterization of Diverse Class 2 CRISPR Cas Systems", Mol. Cell, 2015 Nov 5; 60(3): 385-397, the entire contents of which are herein incorporated by reference. Effectors of two of the systems, C2cl and C2c3, contain RuvC- like endonuclease domains related to Cpfl . A third system, C2c2 contains an effector with two predicted HEPN RNase domains. Production of mature CRISPR RNA is tracrRNA- independent, unlike production of CRISPR RNA by C2cl. C2cl depends on both CRISPR RNA and tracrRNA for DNA cleavage. Bacterial C2c2 has been shown to possess a unique RNase activity for CRISPR RNA maturation distinct from its RNA-activated single- stranded RNA degradation activity. These RNase functions are different from each other and from the CRISPR RNA-processing behavior of Cpfl. See, e.g., East-Seletsky, et ah , "Two distinct RNase activities of CRISPR-C2c2 enable guide-RNA processing and RNA detection", Nature, 2016 Oct 13 ;538(7624) :270-273, the entire contents of which are hereby
incorporated by reference. In vitro biochemical analysis of C2c2 in Leptotrichia shahii has shown that C2c2 is guided by a single CRISPR RNA and can be programmed to cleave ssRNA targets carrying complementary protospacers. Catalytic residues in the two conserved HEPN domains mediate cleavage. Mutations in the catalytic residues generate catalytically inactive RNA-binding proteins. See e.g., Abudayyeh et ah, "C2c2 is a single-component programmable RNA-guided RNA-targeting CRISPR effector," Science, 2016 Aug 5;
353(6299), the entire contents of which are hereby incorporated by reference.
[00151] The crystal structure of Alicyclobaccillus acidoterrastris C2cl (AacC2cl) has been reported in complex with a chimeric single-molecule guide RNA (sgRNA). See, e.g., Liu et al, "C2cl-sgRNA Complex Structure Reveals RNA-Guided DNA Cleavage
Mechanism", Mol. Cell, 2017 Jan 19;65(2):310-322, incorporated herein by reference. The crystal structure has also been reported for Alicyclobacillus acidoterrestris C2cl bound to
target DNAs as ternary complexes. See, e.g., Yang et ah, "PAM-dependent Target DNA Recognition and Cleavage by C2C1 CRISPR-Cas endonuclease", Cell, 2016 Dec
15;167(7): 1814-1828, the entire contents of which are hereby incorporated by reference. Catalytically competent conformations of AacC2cl, both with target and non-target DNA strands, have been captured independently positioned within a single RuvC catalytic pocket, with C2cl -mediated cleavage resulting in a staggered seven-nucleotide break of target DNA. Structural comparisons between C2cl ternary complexes and previously identified Cas9 and Cpf 1 counterparts demonstrate the diversity of mechanisms used by CRISPR-Cas9 systems.
[00152] In some embodiments, the guide nucleotide sequence-programmable DNA- binding protein of any of the fusion proteins provided herein is a C2cl, a C2c2, or a C2c3 protein. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein is a C2cl protein. In some embodiments, the guide nucleotide sequence- programmable DNA-binding protein is a C2c2 protein. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein is a C2c3 protein. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein comprises an amino acid sequence that is at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to a naturally-occurring C2cl, C2c2, or C2c3 protein. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein is a naturally-occurring C2cl, C2c2, or C2c3 protein. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein comprises an amino acid sequence that is at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of SEQ ID NOs: 692-694. In some embodiments, the guide nucleotide sequence- programmable DNA-binding protein comprises an amino acid sequence of any one SEQ ID NOs: 692-694. It should be appreciated that C2cl, C2c2, or C2c3 from other bacterial species may also be used in accordance with the present disclosure.
C2c 1 (uniprot.org/uniprot/T0D7 A2#)
splT0D7A2IC2Cl_ALIAG CRIS PR-associated endonuclease C2cl OS=Alicyclobacillus acidoterrestris (strain ATCC 49025 / DSM 3922 / CIP 106132 / NCEVIB 13137 / GD3B) GN=c2cl PE=1 SV=1
MAVKSIKVKLRLDDMPEIRAGLWKLHKEVNAGVRYYTEWLSLLRQENLYRRSPNG DGEQECDKTAEECKAELLERLRARQVENGHRGPAGSDDELLQLARQLYELLVPQAI
GAKGDAQQIARKFLSPLADKDAVGGLGIAKAGNKPRWVRMREAGEPGWEEEKEKA
ETRKS ADRT AD VLR ALADFGLKPLMR V YTDS EMS S VE WKPLRKGQ A VRT WDRDM
FQQAIERMMSWESWNQRVGQEYAKLVEQKNRFEQKNFVGQEHLVHLVNQLQQDM
KEASPGLESKEQTAHYVTGRALRGSDKVFEKWGKLAPDAPFDLYDAEIKNVQRRNT
RRFGS HDLFAKLAEPE YQ ALWRED AS FLTR Y A V YNS ILRKLNH AKMF ATFTLPD AT
AHPIWTRFDKLGGNLHQYTFLFNEFGERRHAIRFHKLLKVENGVAREVDDVTVPISM
SEQLDNLLPRDPNEPIALYFRDYGAEQHFTGEFGGAKIQCRRDQLAHMHRRRGARD
VYLNVSVRVQSQSEARGERRPPYAAVFRLVGDNHRAFVHFDKLSDYLAEHPDDGKL
GS EGLLS GLR VMS VDLGLRTS AS IS VFR V ARKDELKPNS KGRVPFFFPIKGNDNLV A V
HERSQLLKLPGETESKDLRAIREERQRTLRQLRTQLAYLRLLVRCGSEDVGRRERSW
AKLIEQP VD A ANHMTPD WRE AFENELQKLKS LHGIC S DKEWMD A V YES VRRVWRH
MGKQVRDWRKDVRSGERPKIRGYAKDVVGGNSffiQIEYLERQYKFLKSWSFFGKVS
GQVIRAEKGSRFAITLREHIDHAKEDRLKKLADRIIMEALGYVYALDERGKGKWVA
KYPPCQLILLEELSEYQFNNDRPPSENNQLMQWSHRGVFQELINQAQVHDLLVGTM
YAAFSSRFDARTGAPGIRCRRVPARCTQEHNPEPFPWWLNKFVVEHTLDACPLRAD
DLIPTGEGEIFVSPFSAEEGDFHQIHADLNAAQNLQQRLWSDFDISQIRLRCDWGEVD
GELVLIPRLTGKRT AD SYS NKVFYTNTG VT Y YERERGKKRRKVFAQEKLS EEE AELL
VEADEAREKSVVLMRDPSGIINRGNWTRQKEFWSMVNQRIEGYLVKQIRSRVPLQD
SACENTGDI (SEQ ID NO: 692)
C2c2 (uniprot.org/uniprot/P0DOC6)
>splP0DOC6IC2C2_LEPSD CRISPR-associated endoribonuclease C2c2 OS=Leptotrichia shahii (strain DSM 19757 / CCUG 47503 / CIP 107916 / JCM 16776 / LB37) GN=c2c2 PE=1 SV=1
MGNLFGHKRWYEVRDKKDFKIKRKVKVKRNYDGNKYILNINENNNKEKIDNNKFIR
KYINYKKNDNILKEFTRKFHAGNILFKLKGKEGIIRIENNDDFLETEEVVLYIEAYGKS
EKLKALGITKKKIIDEAIRQGITKDDKKIEIKRQENEEEIEIDIRDEYTNKTLNDCSIILRI
IENDELETKKS IYEIFKNINMS LYKIIEKIIENETEKVFENRYYEEHLREKLLKDDKIDVI
LTNFMEIREKIKSNLEILGFVKFYLNVGGDKKKSKNKKMLVEKILNINVDLTVEDIAD
FVIKELEFWNITKRIEKVKKVNNEFLEKRRNRTYIKSYVLLDKHEKFKIERENKKDKI
VKFFVENIKNNSIKEKIEKILAEFKIDELIKKLEKELKKGNCDTEIFGIFKKHYKVNFDS
KKFSKKSDEEKELYKIIYRYLKGRIEKILVNEQKVRLKKMEKIEIEKILNESILSEKILK
RVKQYTLEHIMYLGKLRHNDIDMTTVNTDDFSRLHAKEELDLELITFFASTNMELNK
IFSRENINNDENIDFFGGDREKNYVLDKKILNSKIKIIRDLDFIDNKNNITNNFIRKFTKI
GTNERNRILHAISKERDLQGTQDDYNKVINIIQNLKISDEEVSKALNLDVVFKDKKNII
TKINDIKISEENNNDIKYLPSFSKVLPEILNLYRNNPKNEPFDTIETEKIVLNALIYVNKE
LYKKLILEDDLEENES KNIFLQELKKTLGNIDEIDENIIENYYKNAQIS AS KGNNKAIK
KYQKKVIECYIGYLRKNYEELFDFSDFKMNIQEIKKQIKDINDNKTYERITVKTSDKTI
VINDDFEYIISIFALLNSNAVINKIRNRFFATSVWLNTSEYQNIIDILDEIMQLNTLRNEC
ITENWNLNLEEFIQKMKEIEKDFDDFKIQTKKEIFNNYYEDIKNNILTEFKDDINGCDV
LEKKLEKIVIFDDETKFEIDKKSNILQDEQRKLSNINKKDLKKKVDQYIKDKDQEIKS
KILCRIIFNSDFLKKYKKEIDNLIEDMESENENKFQEIYYPKERKNELYIYKKNLFLNIG
NPNFDKIYGLISNDIKMADAKFLFNIDGKNIRKNKISEIDAILKNLNDKLNGYSKEYKE
KYIKKLKENDDFFAKNIQNKNYKSFEKDYNRVSEYKKIRDLVEFNYLNKIESYLIDIN
WKLAIQMARFERDMHYIVNGLRELGIIKLSGYNTGISRAYPKRNGSDGFYTTTAYYK
FFDEESYKKFEKICYGFGIDLSENSEINKPENESIRNYISHFYIVRNPFADYSIAEQIDRV
S NLLS YS TRYNNS T Y AS VFE VFKKD VNLD YDELKKKFKLIGNNDILERLMKPKKVS V
LELES YNS D YIKNLIIELLTKIENTNDTL (SEQ ID NO: 693)
C2c3, translated from >CEPX01008730.1 marine metagenome genome assembly
TARA_037_MES_0.1-0.22, contig TARA_037_MES_0.1-0.22_scaffold22115_l, whole genome shotgun sequence.
MRSNYHGGRNARQWRKQISGLARRTKETVFTYKFPLETDAAEIDFDKAVQTYGIAE
GVGHGSLIGLVCAFHLSGFRLFSKAGEAMAFRNRSRYPTDAFAEKLSAIMGIQLPTLS
PEGLDLIFQSPPRSRDGIAPVWSENEVRNRLYTNWTGRGPANKPDEHLLEIAGEIAKQ
VFPKFGGWDDLASDPDKALAAADKYFQSQGDFPSIASLPAAIMLSPANSTVDFEGDY
IAIDPAAETLLHQA VS RC AARLGRERPDLDQNKGPFVS S LQD ALVS S QNNGLS WLFG
VGFQHWKEKSPKELIDEYKVPADQHGAVTQVKSFVDAIPLNPLFDTTHYGEFRASVA
GKVRSWVANYWKRLLDLKSLLATTEFTLPESISDPKAVSLFSGLLVDPQGLKKVADS
LPARLVSAEEAIDRLMGVGIPTAADIAQVERVADEIGAFIGQVQQFNNQVKQKLENL
QDADDEEFLKGLKIELPSGDKEPPAINRISGGAPDAAAEISELEEKLQRLLDARSEHFQ
TISEWAEENAVTLDPIAAMVELERLRLAERGATGDPEEYALRLLLQRIGRLANRVSP
VS AGS IRELLKP VFMEEREFNLFFHNRLGS LYRS P YS TS RHQPFS ID VGKAKAID WIAG
LDQIS SDIEKALS GAGE ALGDQLRDWINLAGFAIS QRLRGLPDTVPN ALAQVRCPDD
VRIPPLLAMLLEEDDIARDVCLKAFNLYVSAINGCLFGALREGFIVRTRFQRIGTDQIH
YVPKDKAWEYPDRLNTAKGPINAAVSSDWIEKDGAVIKPVETVRNLSSTGFAGAGV
SEYLVQAPHDWYTPLDLRDVAHLVTGLPVEKNITKLKRLTNRTAFRMVGASSFKTH
LDSVLLSDKIKLGDFTIIIDQHYRQSVTYGGKVKISYEPERLQVEAAVPVVDTRDRTV
PEPDTLFDHIVAIDLGERSVGFAVFDIKSCLRTGEVKPIHDNNGNPVVGTVAVPSIRRL MKAVRSHRRRRQPNQKVNQTYSTALQNYRENVIGDVCNRIDTLMERYNAFPVLEFQ IKNFQAGAKQLEIVYGS (SEQ ID NO: 694)
[00153] In some embodiments, the guide nucleotide sequence-programmable DNA- binding protein of any of the fusion proteins provided herein is a Cas9 from archaea (e.g. nanoarchaea), which constitute a domain and kingdom of single-celled prokaryotic microbes. In some embodiments, the guide nucleotide sequence-programmable DNA -binding protein is CasX or CasY, which have been described in, for example, Burstein et al., "New CRISPR- Cas systems from uncultivated microbes." Cell Res. 2017 Feb 21. doi: 10.1038/cr.2017.21, which is incorporated herein by reference. Using genome-resolved metagenomics, a number of CRISPR-Cas systems were identified, including the first reported Cas9 in the archaeal domain of life. This divergent Cas9 protein was found in nanoarchaea as part of an active CRISPR-Cas system. In bacteria, two previously unknown systems were discovered, CRISPR-CasX and CRISPR-CasY, which are among the most compact systems yet discovered. In some embodiments, Cas9 refers to CasX, or a variant of CasX. In some embodiments, Cas9 refers to a CasY, or a variant of CasY. It should be appreciated that other RNA-guided DNA binding proteins may be used as a guide nucleotide sequence- programmable DNA-binding protein and are within the scope of this disclosure.
[00154] In some embodiments, the guide nucleotide sequence-programmable DNA- binding protein of any of the fusion proteins provided herein is a CasX or CasY protein. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein is a CasX protein. In some embodiments, the guide nucleotide sequence-programmable DNA- binding protein is a CasY protein. In some embodiments, the guide nucleotide sequence- programmable DNA-binding protein comprises an amino acid sequence that is at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to a naturally-occurring CasX or CasY protein. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein is a naturally-occurring CasX or CasY protein. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein comprises an amino acid sequence that is at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of SEQ ID NOs: 695-697. In some embodiments, the guide nucleotide sequence-programmable DNA-binding protein comprises an amino acid sequence of any one
of SEQ ID NOs: 695-697. It should be appreciated that CasX and CasY from other bacterial species may also be used in accordance with the present disclosure.
CasX (uniprot.org/uniprot/F0NN87; uniprot.org/uniprot/F0NH53)
>trlF0NN87IF0NN87_SULIH CRIS PR-associated Casx protein OS=Sulfolobus islandicus (strain HVE10/4) GN=SiH_0402 PE=4 SV=1
MEVPLYNIFGDNYIIQVATEAENSTIYNNKVEIDDEELRNVLNLAYKIAKNNEDAAAE RRGKAKKKKGEEGETTTSNIILPLSGNDKNPWTETLKCYNFPTTVALSEVFKNFSQV KECEE VS APS FVKPEF YEFGRS PGM VERTRRVKLE VEPH YLIIA A AG W VLTRLGKAK VS EGD Y VG VN VFTPTRGILYS LIQN VNGIVPGIKPET AFGLWIARK V VS S VTNPN VS V VRIYTIS D A VGQNPTTINGGFS IDLTKLLEKRYLLS ERLE AIARN ALS IS S NMRERYIVL ANYIYEYLTGSKRLEDLLYFANRDLIMNLNSDDGKVRDLKLISAYVNGELIRGEG
(SEQ ID NO: 695)
>trlF0NH53IF0NH53_SULIR CRISPR associated protein, Casx OS=Sulfolobus islandicus (strain REY15A) GN=SiRe_0771 PE=4 SV=1
MEVPLYNIFGDNYIIQVATEAENSTIYNNKVEIDDEELRNVLNLAYKIAKNNEDAAAE
RRGKAKKKKGEEGETTTSNIILPLSGNDKNPWTETLKCYNFPTTVALSEVFKNFSQV
KECEEVSAPSFVKPEFYKFGRSPGMVERTRRVKLEVEPHYLIMAAAGWVLTRLGKA
KVS EGD YVGVN VFTPTRGILYS LIQN VNGIVPGIKPET AFGLWIARKVVS S VTNPN VS
VVSIYTISDAVGQNPTTINGGFSIDLTKLLEKRDLLSERLEAIARNALSISSNMRERYIV
LANYIYEYLTGSKRLEDLLYFANRDLIMNLNSDDGKVRDLKLISAYVNGELIRGEG
(SEQ ID NO: 696)
CasY (ncbi.nlm.nih.gov/protein/APG80656.1)
>APG80656.1 CRISPR-associated protein CasY [uncultured Parcubacteria group bacterium] MS KRHPRIS G VKG YRLH AQRLE YTGKS G AMRTIKYPLYS S PS GGRT VPRErVS AINDD Y VGLYGLS NFDDLYN AEKRNEEKV YS VLDFW YDC VQ YG A VFS YT APGLLKN V AE V RGGS YELTKTLKGS HLYDELQID KVIKFLNKKEIS R ANGS LDKLKKDIIDCFKAE YRE RHKDQCNKLADDIKNAKKDAGASLGERQKKLFRDFFGISEQSENDKPSFTNPLNLTC CLLPFDTVNNNRNRGEVLFNKLKEYAQKLDKNEGSLEMWEYIGIGNSGTAFSNFLGE GFLGRLRENKITELKKAMMDITDAWRGQEQEEELEKRLRILAALTIKLREPKFDNHW GGYRSDINGKLSSWLQNYINQTVKIKEDLKGHKKDLKKAKEMINRFGESDTKEEAV VSSLLESIEKIVPDDSADDEKPDIPAIAIYRRFLSDGRLTLNRFVQREDVQEALIKERLE
AEKKKKPKKRKKKSDAEDEKETIDFKELFPHLAKPLKLVPNFYGDSKRELYKKYKN
AAIYTD ALWKA VEKIYKS AFS S S LKNS FFDTDFDKDFFIKRLQKIFS VYRRFNTDKWK
PIVKNS F AP YCDIVS L AENE VLYKPKQS RS RKS A AIDKNRVRLPS TENIAKAGIALARE
LSVAGFDWKDLLKKEEHEEYIDLIELHKTALALLLAVTETQLDISALDFVENGTVKD
FMKTRDGNLVLEGRFLEMFSQSIVFSELRGLAGLMSRKEFITRSAIQTMNGKQAELL
YIPHEFQSAKITTPKEMSRAFLDLAPAEFATSLEPESLSEKSLLKLKQMRYYPHYFGY
ELTRTGQGIDGGVAENALRLEKSPVKKREIKCKQYKTLGRGQNKIVLYVRSSYYQTQ
FLEWFLHRPKNVQTDVAVSGSFLIDEKKVKTRWNYDALTVALEPVSGSERVFVSQPF
TIFPEKSAEEEGQRYLGIDIGEYGIAYTALEITGDSAKILDQNFISDPQLKTLREEVKGL
KLDQRRGTFAMPSTKIARIRESLVHSLRNRIHHLALKHKAKIVYELEVSRFEEGKQKI
KKV Y ATLKKAD V YS EID ADKNLQTT VWGKLA V AS EIS AS YTS QFC G AC KKLWR AE
MQVDETITTQELIGTVRVIKGGTLIDAIKDFMRPPIFDENDTPFPKYRDFCDKHHISKK
MRGNSCLFICPFCRANADADIQASQTIALLRYVKEEKKVEDYFERFRKLKNIKVLGQ
MKKI (SEQ ID NO: 697)
Cas9 domains of Nucleobase Editors
Non-limiting, exemplary Cas9 domains are provided herein. The Cas9 domain may be a nuclease active Cas9 domain, a nucleasae inactive Cas9 domain, or a Cas9 nickase. In some embodiments, the Cas9 domain is a nuclease active domain. For example, the Cas9 domain may be a Cas9 domain that cuts both strands of a duplexed nucleic acid {e.g., both strands of a duplexed DNA molecule). In some embodiments, the Cas9 domain comprises any one of the amino acid sequences as set forth herein. In some embodiments the Cas9 domain comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of the amino acid sequences set forth herein. In some embodiments, the Cas9 domain comprises an amino acid sequence that has 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 21, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, or more mutations compared to any one of the amino acid sequences set forth herein. In some embodiments, the Cas9 domain comprises an amino acid sequence that has at least 10, at least 15, at least 20, at least 30, at leat 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, at least 250, at least 300, at least 350, at least 400, at least 500, at least 600, at least 700, at least 800, at least 900, at least 1000, at least
1100, or at least 1200 identical contiguous amino acid residues as compared to any one of the amino acid sequences set forth herein.
[00155] In some embodiments, the Cas9 domain is a nuclease-inactive Cas9 domain
(dCas9). For example, the dCas9 domain may bind to a duplexed nucleic acid molecule (e.g., via a gRNA molecule) without cleaving either strand of the duplexed nucleic acid molecule. In some embodiments, the nuclease-inactive dCas9 domain comprises a D10X mutation and a H840X mutation or a corresponding mutation in any of the amino acid sequences provided in any of the Cas9 proteins provided herein, wherein X is any amino acid change. In some embodiments, the nuclease-inactive dCas9 domain comprises a D10A mutation and a H840A mutation or a corresponding mutation in any of the amino acid sequences provided in any of the Cas9 proteins provided herein. As one example, a nuclease-inactive Cas9 domain comprises the amino acid sequence set forth in SEQ ID NO: 698 (Cloning vector pPlatTET- gRNA2, Accession No. BAV54124).
MDKKYS IGLAIGTNS VGW A VITDE YK VPS KKFKVLGNTDRHS IKKNLIG ALLFDS GE
TAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHE
RHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEG
DLNPDNS D VDKLFIQLVQT YNQLFEENPIN AS G VD AKAILS ARLS KS RRLENLIAQLP
GEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYA
DLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPE
KYKEIFFDQS KNGYAGYIDGGAS QEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQR
TFDNGS IPHQIHLGELH AILRRQEDF YPFLKDNREKIEKILTFRIP Y Y VGPLARGNS RF A
WMTRKS EETITPWNFEE V VDKG AS AQS FIERMTNFDKNLPNEK VLPKHS LLYE YFT V
YNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFD
SVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERL
KTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMQLIHDDS LTFKEDIQKAQVS GQGDS LHEHIANLAGSPAIKKGILQT VKVVDELVK
VMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQL
QNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDAIVPQSFLKDDSIDNKVLTRSDK
NRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIK
RQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKV
REINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGK
ATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSM
PQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVV
AKVEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFE
LENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQ HKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGA PAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO: 698; see, e.g., Qi et ah, Repurposing CRISPR as an RNA-guided platform for sequence- specific control of gene expression. Cell. 2013; 152(5): 1173-83, the entire contents of which are incorporated herein by reference).
[00156] Additional suitable nuclease-inactive dCas9 domains will be apparent to those of skill in the art based on this disclosure and knowledge in the field, and are within the scope of this disclosure. Such additional exemplary suitable nuclease-inactive Cas9 domains include, but are not limited to, D10A/H840A, D10A/D839A/H840A, and
D10A/D839A/H840A/N863A mutant domains (See, e.g., Prashant et al, CAS 9
transcriptional activators for target specificity screening and paired nickases for cooperative genome engineering. Nature Biotechnology . 2013; 31(9): 833-838, the entire contents of which are incorporated herein by reference). In some embodiments the dCas9 domain comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of the dCas9 domains provided herein. In some embodiments, the Cas9 domain comprises an amino acid sequences that has 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 21, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50 or more mutations compared to any one of the amino acid sequences of Cas9 or a Cas9 variant set forth herein. In some embodiments, the Cas9 domain comprises an amino acid sequence that has at least 10, at least 15, at least 20, at least 30, at leat 40, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 150, at least 200, at least 250, at least 300, at least 350, at least 400, at least 500, at least 600, at least 700, at least 800, at least 900, at least 1000, at least 1100, or at least 1200 identical contiguous amino acid residues as compared to any one of the amino acid sequences of Cas9 or a Cas9 variant set forth herein.
[00157] In some embodiments, the Cas9 domain is a Cas9 nickase. The Cas9 nickase may be a Cas9 protein that is capable of cleaving only one strand of a duplexed nucleic acid molecule (e.g., a duplexed DNA molecule). In some embodiments the Cas9 nickase cleaves the target strand of a duplexed nucleic acid molecule, meaning that the Cas9 nickase cleaves the strand that is base paired to (complementary to) a gRNA (e.g., an sgRNA) that is bound to the Cas9. In some embodiments, a Cas9 nickase comprises a D10A mutation and has a histidine at position 840. For example, a Cas9 nickase may comprise the amino acid
sequence as set forth in SEQ ID NO: 683. In some embodiments the Cas9 nickase comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of the Cas9 nickases provided herein. Additional suitable Cas9 nickases will be apparent to those of skill in the art based on this disclosure and knowledge in the field, and are within the scope of this disclosure.
Cas9 Domains with Reduced PAM Exclusivity
[00158] Some aspects of the disclosure provide Cas9 domains that have different PAM specificities. Typically, Cas9 proteins, such as Cas9 from S. pyogenes (spCas9), require a canonical NGG PAM sequence to bind a particular nucleic acid region. This may limit the ability to edit desired bases within a genome. In some embodiments, the base editing fusion proteins provided herein may need to be placed at a precise location, for example where a target base is placed within a four base region {e.g., a "deamination window"), which is approximately 15 bases upstream of the PAM. See Komor, A.C., et ah, "Programmable editing of a target base in genomic DNA without double- stranded DNA cleavage" Nature 533, 420-424 (2016), the entire contents of which are hereby incorporated by reference.
Accordingly, in some embodiments, any of the fusion proteins provided herein may contain a Cas9 domain that is capable of binding a nucleotide sequence that does not contain a canonical {e.g., NGG) PAM sequence and has relaxed PAM requirements (PAMless Cas9). PAMless Cas9 exhibits an increased activity on a target sequence that does not include a canonical PAM {e.g., NGG) sequence at its 3 '-end as compared to Streptococcus pyogenes Cas9 as provided by SEQ ID NO: 1, e.g., increased activity by at least 5-fold, at least 10-fold, at least 50-fold, at least 100-fold, at least 500-fold, at least 1,000-fold, at least 5,000-fold, at least 10,000-fold, at least 50,000-fold, at least 100,000-fold, at least 500,000-fold, or at least 1,000,000-fold. Cas9 domains that bind to non-canonical PAM sequences have been described in the art and would be apparent to the skilled artisan. For example, Cas9 domains that bind non-canonical PAM sequences have been described in Kleinstiver, B. P., et ah, "Engineered CRISPR-Cas9 nucleases with altered PAM specificities" Nature 523, 481-485 (2015); and Kleinstiver, B. P., et ah, "Broadening the targeting range of Staphylococcus aureus CRISPR-Cas9 by modifying PAM recognition" Nature Biotechnology 33, 1293-1298 (2015); the entire contents of each are hereby incorporated by reference. See also US
Provisional Applications, USSN 62/245,828, filed October 23, 2015; 62/279,346, filed January 15, 2016; 62/311,763, filed March 22, 2016; 62/322,178, filed April 13, 2016; and
62/357,332, filed June 30, 2016, each of which is incorporated herein by reference. In some embodiments, the dCas9 or Cas9 nickase useful in the present disclosure may further comprise mutations that relax the PAM requirements, e.g., mutations that correspond to A262T, K294R, S409I, E480K, E543D, M694I, or E1219V in SEQ ID NO: 1.
[00159] In some embodiments, the Cas9 domain is a Cas9 domain from
Staphylococcus aureus (SaCas9). In some embodiments, the SaCas9 domain is a nuclease active SaCas9, a nuclease inactive SaCas9 (SaCas9d), or a SaCas9 nickase (SaCas9n). In some embodiments, the SaCas9 comprises the amino acid sequence SEQ ID NO: 699. In some embodiments, the SaCas9 comprises a N579X mutation of SEQ ID NO: 699, or a corresponding mutation in any of the amino acid sequences provided in any of the Cas9 proteins disclosed herein including, but not limited to, SEQ ID NOs: 1-260, 270-292, 315- 323, 680, and 682, wherein X is any amino acid except for N. In some embodiments, the SaCas9 comprises a N579A mutation of SEQ ID NO: 699, or a corresponding mutation in any of the amino acid sequences provided in SEQ ID NOs: 1-260, 272-292, 315-323, 680, and 682. In some embodiments, the SaCas9 domain, the SaCas9d domain, or the SaCas9n domain can bind to a nucleic acid seuqnce having a non-canonical PAM. In some embodiments, the SaCas9 domain, the SaCas9d domain, or the SaCas9n domain can bind to a nucleic acid sequence having a NNGRRT PAM sequence. In some embodiments, the SaCas9 domain comprises one or more of a E781X, a N967X, and a R1014X mutation of SEQ ID NO: 699, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to in SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682, wherein X is any amino acid. In some embodiments, the SaCas9 domain comprises one or more of a E781K, a N967K, and a R1014H mutation of SEQ ID NO: 699, or one or more corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to in SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, the SaCas9 domain comprises a E781K, a N967K, or a R1014H mutation of SEQ ID NO: 699, or one or more corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to in SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682.
[00160] In some embodiments, the Cas9 domain of any of the fusion proteins provided herein comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of SEQ ID NOs: 699-701. In some embodiments, the Cas9 domain of any of the fusion proteins provided herein comprises
the amino acid sequence of any one of SEQ ID NOs: 699-701. In some embodiments, the Cas9 domain of any of the fusion proteins provided herein consists of the amino acid sequence of any one of SEQ ID NOs: 699-701.
Exemplary SaCas9 sequence
KRNYILGLDIGITSVGYGIIDYETRDVIDAGVRLFKEANVENNEGRRSKRGARRLKRR
RRHRIQR VKKLLFD YNLLTDHS ELS GINP YE AR VKGLS QKLS EEEFS A ALLHLAKRRG
VHNVNEVEEDTGNELSTKEQISRNSKALEEKYVAELQLERLKKDGEVRGSINRFKTS
DYVKEAKQLLKVQKAYHQLDQSFIDTYIDLLETRRTYYEGPGEGSPFGWKDIKEWY
EMLMGHCTYFPEELRSVKYAYNADLYNALNDLNNLVITRDENEKLEYYEKFQIIENV
FKQKKKPTLKQIAKEILVNEEDIKGYRVTSTGKPEFTNLKVYHDIKDITARKEIIENAE
LLD QIAKILTIYQS S EDIQEELTNLNS ELTQEEIEQIS NLKG YTGTHNLS LKAINLILDEL
WHTNDNQIAIFNRLKLVPKK VDLS QQKEIPTTLVDDFILS P V VKRS FIQS IK VIN AIIKK
YGLPNDIIIELAREKNSKDAQKMINEMQKRNRQTNERIEEIIRTTGKENAKYLIEKIKL
HDMQEGKCLYSLEAIPLEDLLNNPFNYEVDHIIPRSVSFDNSFNNKVLVKQEENSKK
GNRTPFQYLSSSDSKISYETFKKHILNLAKGKGRISKTKKEYLLEERDINRFSVQKDFI
NRNLVDTRYATRGLMNLLRSYFRVNNLDVKVKSINGGFTSFLRRKWKFKKERNKG
YKHHAEDALIIANADFIFKEWKKLDKAKKVMENQMFEEKQAESMPEIETEQEYKEIF
ITPHQIKHIKDFKDYKYSHRVDKKPNRELINDTLYSTRKDDKGNTLIVNNLNGLYDK
DNDKLKKLINKSPEKLLMYHHDPQTYQKLKLIMEQYGDEKNPLYKYYEETGNYLTK
YSKKDNGPVIKKIKYYGNKLNAHLDITDDYPNSRNKVVKLSLKPYRFDVYLDNGVY
KFVTVKNLDVIKKENYYEVNSKCYEEAKKLKKISNQAEFIASFYNNDLIKINGELYRV
IGVNNDLLNRIEVNMIDITYREYLENMNDKRPPRIIKTIASKTQSIKKYSTDILGNLYE
VKS KKHPQIIKKG (SEQ ID NO: 699)
Residue N579 of SEQ ID NO: 699, which is underlined and in bold, may be mutated (e.g., to a A579) to yield a SaCas9 nickase.
Exemplary SaCas9d sequence
KRNYILGLAIGITSVGYGIIDYETRDVIDAGVRLFKEANVENNEGRRSKRGARRLKRR
RRHRIQR VKKLLFD YNLLTDHS ELS GINP YE AR VKGLS QKLS EEEFS A ALLHLAKRRG
VHNVNEVEEDTGNELSTKEQISRNSKALEEKYVAELQLERLKKDGEVRGSINRFKTS
DYVKEAKQLLKVQKAYHQLDQSFIDTYIDLLETRRTYYEGPGEGSPFGWKDIKEWY
EMLMGHCTYFPEELRSVKYAYNADLYNALNDLNNLVITRDENEKLEYYEKFQIIENV
FKQKKKPTLKQIAKEILVNEEDIKGYRVTSTGKPEFTNLKVYHDIKDITARKEIIENAE
LLD QIAKILTIYQS S EDIQEELTNLNS ELTQEEIEQIS NLKG YTGTHNLS LKAINLILDEL
WHTNDNQIAIFNRLKLVPKK VDLS QQKEIPTTLVDDFILS P V VKRS FIQS IK VIN AIIKK
YGLPNDIIIELAREKNSKDAQKMINEMQKRNRQTNERIEEIIRTTGKENAKYLIEKIKL
HDMQEGKCLYSLEAIPLEDLLNNPFNYEVDHIIPRSVSFDNSFNNKVLVKQEENSKK
GNRTPFQYLSSSDSKISYETFKKHILNLAKGKGRISKTKKEYLLEERDINRFSVQKDFI
NRNLVDTRYATRGLMNLLRSYFRVNNLDVKVKSINGGFTSFLRRKWKFKKERNKG
YKHHAEDALIIANADFIFKEWKKLDKAKKVMENQMFEEKQAESMPEIETEQEYKEIF
ITPHQIKHIKDFKDYKYSHRVDKKPNRELINDTLYSTRKDDKGNTLIVNNLNGLYDK
DNDKLKKLINKSPEKLLMYHHDPQTYQKLKLIMEQYGDEKNPLYKYYEETGNYLTK
YSKKDNGPVIKKIKYYGNKLNAHLDITDDYPNSRNKVVKLSLKPYRFDVYLDNGVY
KFVTVKNLDVIKKENYYEVNSKCYEEAKKLKKISNQAEFIASFYNNDLIKINGELYRV
IGVNNDLLNRIEVNMIDITYREYLENMNDKRPPRIIKTIASKTQSIKKYSTDILGNLYE
VKS KKHPQIIKKG (SEQ ID NO: 702)
Residue D10 of SEQ ID NO: 702, which is underlined and in bold, may be mutated (e.g., to a A10) to yield a nuclease inactive SaCas9d.
Exemplary SaCas9n sequence
KRNYILGLDIGITSVGYGIIDYETRDVIDAGVRLFKEANVENNEGRRSKRGARRLKRR
RRHRIQR VKKLLFD YNLLTDHS ELS GINP YE AR VKGLS QKLS EEEFS A ALLHLAKRRG
VHNVNEVEEDTGNELSTKEQISRNSKALEEKYVAELQLERLKKDGEVRGSINRFKTS
DYVKEAKQLLKVQKAYHQLDQSFIDTYIDLLETRRTYYEGPGEGSPFGWKDIKEWY
EMLMGHCTYFPEELRSVKYAYNADLYNALNDLNNLVITRDENEKLEYYEKFQIIENV
FKQKKKPTLKQIAKEILVNEEDIKGYRVTSTGKPEFTNLKVYHDIKDITARKEIIENAE
LLD QIAKILTIYQS S EDIQEELTNLNS ELTQEEIEQIS NLKG YTGTHNLS LKAINLILDEL
WHTNDNQIAIFNRLKLVPKK VDLS QQKEIPTTLVDDFILS P V VKRS FIQS IK VIN AIIKK
YGLPNDIIIELAREKNSKDAQKMINEMQKRNRQTNERIEEIIRTTGKENAKYLIEKIKL
HDMQEGKCLYSLEAIPLEDLLNNPFNYEVDHIIPRSVSFDNSFNNKVLVKQEEASKK
GNRTPFQYLSSSDSKISYETFKKHILNLAKGKGRISKTKKEYLLEERDINRFSVQKDFI
NRNLVDTRYATRGLMNLLRSYFRVNNLDVKVKSINGGFTSFLRRKWKFKKERNKG
YKHHAEDALIIANADFIFKEWKKLDKAKKVMENQMFEEKQAESMPEIETEQEYKEIF
ITPHQIKHIKDFKDYKYSHRVDKKPNRELINDTLYSTRKDDKGNTLIVNNLNGLYDK
DNDKLKKLINKSPEKLLMYHHDPQTYQKLKLIMEQYGDEKNPLYKYYEETGNYLTK
YSKKDNGPVIKKIKYYGNKLNAHLDITDDYPNSRNKVVKLSLKPYRFDVYLDNGVY
KFVTVKNLDVIKKENYYEVNSKCYEEAKKLKKISNQAEFIASFYNNDLIKINGELYRV
IGVNNDLLNRIEVNMIDITYREYLENMNDKRPPRIIKTIASKTQSIKKYSTDILGNLYE VKS KKHPQIIKKG (SEQ ID NO: 700).
Residue A579 of SEQ ID NO: 700, which can be mutated from N579 of SEQ ID NO: 699 to yield a SaCas9 nickase, is underlined and in bold.
Exemplary SaKKH Cas9
KRNYILGLDIGITSVGYGIIDYETRDVIDAGVRLFKEANVENNEGRRSKRGARRLKRR
RRHRIQR VKKLLFD YNLLTDHS ELS GINP YE AR VKGLS QKLS EEEFS A ALLHLAKRRG
VHNVNEVEEDTGNELSTKEQISRNSKALEEKYVAELQLERLKKDGEVRGSINRFKTS
DYVKEAKQLLKVQKAYHQLDQSFIDTYIDLLETRRTYYEGPGEGSPFGWKDIKEWY
EMLMGHCTYFPEELRSVKYAYNADLYNALNDLNNLVITRDENEKLEYYEKFQIIENV
FKQKKKPTLKQIAKEILVNEEDIKGYRVTSTGKPEFTNLKVYHDIKDITARKEIIENAE
LLD QIAKILTIYQS S EDIQEELTNLNS ELTQEEIEQIS NLKG YTGTHNLS LKAINLILDEL
WHTNDNQIAIFNRLKLVPKK VDLS QQKEIPTTLVDDFILS P V VKRS FIQS IK VIN AIIKK
YGLPNDIIIELAREKNSKDAQKMINEMQKRNRQTNERIEEIIRTTGKENAKYLIEKIKL
HDMQEGKCLYSLEAIPLEDLLNNPFNYEVDHIIPRSVSFDNSFNNKVLVKQEEASKK
GNRTPFQYLSSSDSKISYETFKKHILNLAKGKGRISKTKKEYLLEERDINRFSVQKDFI
NRNLVDTRYATRGLMNLLRSYFRVNNLDVKVKSINGGFTSFLRRKWKFKKERNKG
YKHHAEDALIIANADFIFKEWKKLDKAKKVMENQMFEEKQAESMPEIETEQEYKEIF
ITPHQIKHIKDFKDYKYSHRVDKKPNR^LINDTLYSTRKDDKGNTLIVNNLNGLYDK
DNDKLKKLINKSPEKLLMYHHDPQTYQKLKLIMEQYGDEKNPLYKYYEETGNYLTK
YSKKDNGPVIKKIKYYGNKLNAHLDITDDYPNSRNKVVKLSLKPYRFDVYLDNGVY
KFVTVKNLDVIKKENYYEVNSKCYEEAKKLKKISNQAEFIASFYZNDLIKINGELYRV
IGVNNDLLNRIEVNMIDITYREYLENMNDKRPPHIIKTIASKTQSIKKYSTDILGNLYE
VKS KKHPQIIKKG (SEQ ID NO: 701).
Residue A579 of SEQ ID NO: 701, which can be mutated from N579 of SEQ ID NO: 699 to yield a SaCas9 nickase, is underlined and in bold. Residues K781, K967, and H1014 of SEQ ID NO: 701, which can be mutated from E781, N967, and R1014 of SEQ ID NO: 699 to yield a SaKKH Cas9 are underlined and in italics.
[00161] In some embodiments, the Cas9 domain is a Cas9 domain from Streptococcus pyogenes (SpCas9). In some embodiments, the SpCas9 domain is a nuclease active SpCas9, a nuclease inactive SpCas9 (SpCas9d), or a SpCas9 nickase (SpCas9n). In some
embodiments, the SpCas9 comprises the amino acid sequence SEQ ID NO: 703. In some
embodiments, the SpCas9 comprises a D9X mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682, wherein X is any amino acid except for D. In some embodiments, the SpCas9 comprises a D9A mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, the SpCas9 domain, the SpCas9d domain, or the SpCas9n domain can bind to a nucleic acid sequence having a non-canonical PAM. In some embodiments, the SpCas9 domain, the SpCas9d domain, or the SpCas9n domain can bind to a nucleic acid sequence having a NGG, a NGA, or a NGCG PAM sequence. In some embodiments, the SpCas9 domain comprises one or more of a Dl 134X, a R1334X, and a T1336X mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682, wherein X is any amino acid. In some embodiments, the SpCas9 domain comprises one or more of a Dl 134E, R1334Q, and T1336R mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, the SpCas9 domain comprises a Dl 134E, a R1334Q, and a T1336R mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, the SpCas9 domain comprises one or more of a Dl 134X, a R1334X, and a T1336X mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1- 260, 270-292, 315-323, 680, or 682, wherein X is any amino acid. In some embodiments, the SpCas9 domain comprises one or more of a Dl 134V, a R1334Q, and a T1336R mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, the SpCas9 domain comprises a Dl 134V, a R1334Q, and a T1336R mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, the SpCas9 domain comprises one or more of a Dl 134X, a G1217X, a R1334X, and a T1336X mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682, wherein X is any
amino acid. In some embodiments, the SpCas9 domain comprises one or more of a Dl 134V, a G1217R, a R1334Q, and a T1336R mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to, SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, the SpCas9 domain comprises a D1134V, a G1217R, a R1334Q, and a T1336R mutation of SEQ ID NO: 703, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682.
[00162] In some embodiments, the Cas9 domain of any of the fusion proteins provided herein comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any one of SEQ ID NOs: 4276-4280. In some embodiments, the Cas9 domain of any of the fusion proteins provided herein comprises the amino acid sequence of any one of SEQ ID NOs: 703-707. In some embodiments, the Cas9 domain of any of the fusion proteins provided herein consists of the amino acid sequence of any one of SEQ ID NOs: 703-707.
Exemplary SpCas9
DKKYSIGLDIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETA
EATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERH
PIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDL
NPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGE
KKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADL
FLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKY
KEIFFDQS KNGYAGYIDGGAS QEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTF
DNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAW
MTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVY
NELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDS
VEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERL
KTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMQLIHDDS LTFKEDIQKAQVS GQGDS LHEHIANLAGSPAIKKGILQT VKVVDELVK
VMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQL
QNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDK
NRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIK
RQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKV
REINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGK ATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSM PQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVV AKVEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFE LENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQ HKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGA PAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO: 703)
Exemplary SpCas9n
DKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETA
EATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERH
PIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDL
NPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGE
KKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADL
FLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKY
KEIFFDQS KNGYAGYIDGGAS QEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTF
DNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAW
MTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVY
NELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDS
VEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERL
KTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMQLIHDDS LTFKEDIQKAQVS GQGDS LHEHIANLAGSPAIKKGILQT VKVVDELVK
VMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQL
QNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDK
NRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIK
RQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKV
REINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGK
ATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSM
PQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVV
AKVEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFE
LENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQ
HKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGA
PAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO: 704)
Exemplary SpEQR Cas9
DKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETA
EATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERH
PIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDL
NPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGE
KKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADL
FLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKY
KEIFFDQS KNGYAGYIDGGAS QEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTF
DNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAW
MTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVY
NELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDS
VEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERL
KTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMQLIHDDS LTFKEDIQKAQVS GQGDS LHEHIANLAGSPAIKKGILQT VKVVDELVK
VMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQL
QNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDK
NRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIK
RQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKV
REINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGK
ATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSM
PQ VNIVKKTE VQTGGFS KES ILPKRNS DKLI ARKKD WDPKKYGGFES PT V A YS VLV V
AKVEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFE
LENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQ
HKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGA
PAAFKYFDTTIDRKQYRSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
705)
Residues El 134, Q1334, and R1336 of SEQ ID NO: 705, which can be mutated from D1134, R1334, and T1336 of SEQ ID NO: 703 to yield a SpEQR Cas9, are underlined and in bold.
Exemplary SpVQR Cas9
DKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETA
EATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERH
PIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDL
NPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGE
KKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADL
FLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKY
KEIFFDQS KNGYAGYIDGGAS QEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTF
DNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAW
MTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVY
NELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDS
VEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERL
KTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMQLIHDDS LTFKEDIQKAQVS GQGDS LHEHIANLAGSPAIKKGILQT VKVVDELVK
VMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQL
QNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDK
NRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIK
RQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKV
REINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGK
ATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSM
PQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFVSPTVAYSVLVV
AKVEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFE
LENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQ
HKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGA
PAAFKYFDTTIDRKQYRSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
706)
Residues VI 134, Q1334, and R1336 of SEQ ID NO: 706, which can be mutated from D1134, R1334, and T1336 of SEQ ID NO: 703 to yield a SpVQR Cas9, are underlined and in bold.
Exemplary SpVRER Cas9
DKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETA EATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERH PIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDL NPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGE
KKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADL
FLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKY
KEIFFDQS KNGYAGYIDGGAS QEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTF
DNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAW
MTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVY
NELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDS
VEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERL
KTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRN
FMQLIHDDS LTFKEDIQKAQVS GQGDS LHEHIANLAGSPAIKKGILQT VKVVDELVK
VMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQL
QNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDK
NRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIK
RQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKV
REINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGK
ATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSM
PQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFVSPTVAYSVLVV
AKVEKGKS KKLKS VKELLGITIMERS S FEKNPIDFLE AKG YKE VKKDLIIKLPKYS LFE
LENGRKRMLASARELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQ
HKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGA
PAAFKYFDTTIDRKEYRSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO:
707)
Residues VI 134, R1217, Q1334, and R1336 of SEQ ID NO: 707, which can be mutated from D1134, G1217, R1334, and T1336 of SEQ ID NO: 703 to yield a SpVRER Cas9, are underlined and in bold.
High Fidelity Base Editors
[00163] Some aspects of the disclosure provide Cas9 fusion proteins {e.g., any of the fusion proteins provided herein) comprising a Cas9 domain that has high fidelity. Additional aspects of the disclosure provide Cas9 fusion proteins {e.g., any of the fusion proteins provided herein) comprising a Cas9 domain with decreased electrostatic interactions between the Cas9 domain and a sugar-phosphate backbone of a DNA, as compared to a wild- type Cas9 domain. In some embodiments, a Cas9 domain {e.g., a wild type Cas9 domain) comprises one or more mutations that decreases the association between the Cas9 domain and a sugar-phosphate backbone of a DNA. In some embodiments, any of the Cas9 fusion
proteins provided herein comprise one or more of a N497X, a R661X, a Q695X, and/or a Q926X mutation of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to the sequences seen in SEQ ID NOs: 1-260, 270-292, and 315-323, wherein X is any amino acid. In some embodiments, any of the Cas9 fusion proteins provided herein comprise one or more of a N497A, a R661A, a Q695A, and/or a Q926A mutation of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to the sequences seen in SEQ ID NOs: 1-260, 270-292, 315-323, 680, and 682. In some embodiments, the Cas9 domain comprises a D10A mutation of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the Cas9 amino acid sequences provided herein, including but not limited to the sequences seen in SEQ ID NOs: 1-260, 270-292, 315-323, 680, and 682. In some embodiments, the Cas9 domain (e.g., of any of the fusion proteins provided herein) comprises the amino acid sequence as set forth in SEQ ID NO: 708. In some embodiments, the fusion protein comprises the amino acid sequence as set forth in SEQ ID NO: 709. Cas9 domains with high fidelity are known in the art and would be apparent to the skilled artisan. For example, Cas9 domains with high fidelity have been described in Kleinstiver, B.P., et al. "High-fidelity CRISPR-Cas9 nucleases with no detectable genome-wide off-target effects." Nature 529, 490-495 (2016); and Slaymaker, I.M., et al. "Rationally engineered Cas9 nucleases with improved specificity." Science 351, 84-88 (2015); the entire contents of each are incorporated herein by reference.
[00164] It should be appreciated that the base editors provided herein, for example, base editor 2 (BE2) or base editor 3 (BE3), may be converted into high fidelity base editors by modifying the Cas9 domain as described herein to generate high fidelity base editors, for example, high fidelity base editor 2 (HF-BE2) or high fidelity base editor 3 (HF-BE3). In some embodiments, base editor 2 (BE2) comprises a deaminase domain, a dCas9 domain, and a UGI domain. In some embodiments, base editor 3 (BE3) comprises a deaminase domain, a nCas9 domain, and a UGI domain.
Cas9 domain where mutations relative to Cas9 of SEQ ID NO: 1 are shown in bold and underlines
DKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARR RYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRK KLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAK
AILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLL
AQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYK
EIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGE
LHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASA
QSFIERMTAFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTN
RKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFE
DREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGALSRKLINGIRDKQSGKTILDFLKSDGFANRNFM
ALIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEM
ARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDIN
RLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFD
NLTKAERGGLSELDKAGFIKRQLVETRAITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFR
KDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATA
KYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTG
GFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERS
SFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASH
YEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIH
LFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGD (SEQ ID NO: 708)
HF-BE3
MSSETGPVAVDPTLRRRIEPHEFEVFFDPRELRKETCLLYEINWGGRHSIWRHTSQNTNKHVEVNFIEKF
TTERYFCPNTRCSITWFLSWSPCGECSRAITEFLSRYPHVTLFIYIARLYHHADPRNRQGLRDLISSGVTI
QIMTEQESGYCWRNFVNYSPSNEAHWPRYPHLWVRLYVLELYCIILGLPPCLNILRRKQPQLTFFTIALQ
SCHYQRLPPHILWATGLKSGSETPGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLG
NTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFL
VEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLN
PDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALS
LGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITK
APLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKM
DGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGP
LARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTAFDKNLPNEKVLPKHSLLYEYFTVYN
ELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASL
GTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWG
ALSRKLINGIRDKQSGKTILDFLKSDGFANRNFMALIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGS
PAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEH
PVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKS
DNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRAITKHVAQIL
DSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPK
LESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIV
WDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVA
YSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGR
KRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKR VILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIH QSITGLYETRIDLSQLGGD (SEQ ID NO: 709)
Fusion Proteins comprising Gam
[00165] Some aspects of the disclosure provide fusion proteins comprising a Gam protein. Some aspects of the disclosure provide base editors that further comprise a Gam protein. Base editors are known in the art and have been described previously, for example, in U.S. Patent Application Publication Nos.: U.S. 2015-0166980, published June 18, 2015; U.S. 2015-0166981, published June 18, 2015; U.S. 2015-0166984, published June 18, 2015; U.S. 2015-01669851, published June 18, 2015; U.S. 2016-0304846, published October 20, 2016; U.S. 2017-0121693-A1, published May 4, 2017; and PCT Application publication Nos.: WO 2015089406, published June 18, 2015; and WO2017070632, published April 27, 2017; the entire contents of each of which are hereby incorporated by reference. A skilled artisan would understand, based on the disclosure, how to make and use base editors that further comprise a Gam protein.
[00166] In some embodiments, the disclosure provides fusion proteins comprising a guide nucleotide sequence-programmable DNA-binding protein and a Gam protein. In some embodiments, the disclosure provides fusion proteins comprising a cytidine deaminase domain and a Gam protein. In some embodiments, the disclosure provides fusion proteins comprising a UGI domain and a Gam protein. In some embodiments, the disclosure provides fusion proteins comprising a guide nucleotide sequence-programmable DNA-binding protein, a cytidine deaminase domain and a Gam protein. In some embodiments, the disclosure provides fusion proteins comprising a guide nucleotide sequence-programmable DNA- binding protein, a cytidine deaminase domain a Gam protein and a UGI domain.
[00167] In some embodiments, the Gam protein is a protein that binds to double strand breaks in DNA and prevents or inhibits degradation of the DNA at the double strand breaks. In some embodiments, the Gam protein is encoded by the bacteriophage Mu, which binds to double stranded breaks in DNA. Without wishing to be bound by any particular theory, Mu transposes itself between bacterial genomes and uses Gam to protect double stranded breaks in the transposition process. Gam can be used to block homologous recombination with sister chromosomes to repair double strand breaks, sometimes leading to cell death. The survival of cells exposed to UV is similar for cells expression Gam and cells where the recB is mutated. This indicates that Gam blocks DNA repair (Cox, 2013). The Gam protein can thus promote
Cas9-mediated killing (Cui et al, 2016). GamGFP is used to label double stranded breaks, although this can be difficult in eukaryotic cells as the Gam protein competes with similar eukaryotic protein Ku (Shee et al., 2013).
[00168] Gam is related to Ku70 and Ku80, two eukaryotic proteins involved in nonhomologous DNA end-joining (Cui et al., 2016). Gam has sequence homology with both subunits of Ku (Ku70 and Ku80), and can have a similar structure to the core DNA-binding region of Ku. Orthologs to Mu Gam are present in the bacterial genomes of Haemophilus influenzae, Salmonella typhi, Neisseria meningitidis, and the enterohemorrhagic 0157:H7 strain of E. coli (d'Adda di Fagagna et al., 2003). Gam proteins have been described previously, for example, in COX, Proteins pinpoint double strand breaks. eLife. 2013; 2: e01561.; Cui et al., Consequences of Cas9 cleavage in the chromosome of Escherichia coli. Nucleic Acids Res. 2016 May 19;44(9):4243-51. doi: 10.1093/nar/gkw223. Epub 2016 Apr 8.; D'ADDA DI FAGAGNA et al, The Gam protein of bacteriophage Mu is an orthologue of eukaryotic Ku. EMBO Rep. 2003 Jan;4(l):47-52.; and SHEE et al, Engineered proteins detect spontaneous DNA breakage in human and bacterial cells. Elife. 2013 Oct 29;2:e01222. doi: 10.7554/eLife.01222; the contents of each of which are incorporated herein by reference.
[00169] In some embodiments, the Gam protein is a protein that binds double strand breaks in DNA and prevents or inhibits degradation of the DNA at the double strand breaks. In some embodiments, the Gam protein is a naturally occurring Gam protein from any organism {e.g., a bacterium), for example, any of the organisms provided herein. In some embodiments, the Gam protein is a variant of a naturally-occurring Gam protein from an organism. In some embodiments, the Gam protein does not occur in nature. In some embodiments, the Gam protein is at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75% at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to a naturally-occurring Gam protein. In some embodiments, the Gam protein is at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75% at least 80%, at least 85%, at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or at least 99.5% identical to any of the Gam proteins provided herein {e.g., SEQ ID NO: 9). Exemplary Gam proteins are provided below. In some embodiments, the Gam protein comprises any of the Gam proteins provided herein {e.g., SEQ ID NO: 710-734). In some embodiments, the Gam protein is a truncated version of any of the Gam proteins provided herein. In some embodiments, the truncated Gam protein is missing 1, 2, 3, 4, 5 ,6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 6, 17, 18, 19, or 20 N- terminal amino acid residues relative to a full-length Gam protein. In some embodiments, the
truncated Gam protein may be missing 1, 2, 3, 4, 5 ,6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 6, 17, 18, 19, or 20 C-terminal amino acid residues relative to a full-length Gam protein. In some embodiments, the Gam protein does not comprise an N-terminal methionine.
[00170] In some embodiments, the Gam protein comprises an amino acid sequence that is at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90%, at least 95, at least 98%, at least 99%, or at least 99.5% identical to any of the Gam proteins provided herein. In some embodiments, the Gam protein comprises an amino acid sequence that has 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 21, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50 or more mutations compared to any one of the Gam Proteins provided herein (e.g., SEQ ID NOs: 710-734). In some embodiments, the Gam protein comprises an amino acid sequence that has at least 5, at least 10, at least 15, at least 20, at least 25, at least 30, at least 35, at least 40, at least 45, at least 50, at least 60, at least 70, at least 80, at least 90, at least 100, at least 110, at least 120, at least 130, at least 140, at least 150, at least 160, or at least 170, identical contiguous amino acid residues as compared to any of the Gam proteins provided herein. In some embodiments, the Gam protein comprises the amino acid sequence of any of the Gam proteins provided herein. In some embodiments, the Gam protein consists of the any of the Gam proteins provided herein (e.g., SEQ ID NO: 710 or 711-734).
Gam form bacteriophage Mu
AKPAKRIKSAAAAYVPQNRDAVITDIKRIGDLQREASRLETEMNDAIAEITEKFAARI APIKTDIETLSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRVRPPSVSIRGMD AVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 710)
>WP_001107930.1 MULTISPECIES: host-nuclease inhibitor protein Gam
[Enterobacteriaceae]
MAKPAKRIKSAAAAYVPQNRDAVITDIKRIGDLQREASRLETEMNDAIAEITEKFAAR IAPIKTDIETLSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRVRPPSVSIRGMD AVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 711)
>CAA27978.1 unnamed protein product [Escherichia virus Mu]
MAKPAKRIKSAAAAYVPQNRDAVITDIKRIGDLQREASRLETEMNDAIAEITEKFAAR IAPIKTDIETLSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRVRPPSVSIRGMD A VMETLERLGLQRFVRTKQEINKEAILLEPKA VAGVAGIT VKS GIEDFS IIPFEQEAGI
(SEQ ID NO: 712)
>WP_001107932.1 host-nuclease inhibitor protein Gam [Escherichia coli]
MAKPAKRIKSAAAAYVPQNRDAVITDIKRIGDLQREASRLETEMNDAIAEITEKFAAR IAPLKTDIETLSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRVRPPSVSIRGM DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 713)
>WP_061335739.1 host-nuclease inhibitor protein Gam [Escherichia coli]
MAKPAKRIKSAAAAYVPQNRDAVITDIKRIGDLQREASRLETEMNDAIAEITEKFAAR IAPIKTDIETLSKGVQGWCEANRDELTNGGKVKTANLITGDVSWRVRPPSVSIRGMD AVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 714)
>WP_001107937.1 MULTISPECIES: host-nuclease inhibitor protein Gam
[Enterobacteriaceae] >EJL11163.1 bacteriophage Mu Gam like family protein [Shigella sonnei str. Moseley] >CS081529.1 host-nuclease inhibitor protein [Shigella sonnet]
>OCE38605.1 host-nuclease inhibitor protein Gam [Shigella sonnei] >SJK50067.1 host- nuclease inhibitor protein [Shigella sonnei] >SJK19110.1 host-nuclease inhibitor protein [Shigella sonnei] >SIY81859.1 host-nuclease inhibitor protein [Shigella sonnei] >SJJ34359.1 host-nuclease inhibitor protein [Shigella sonnei] >SJK07688.1 host-nuclease inhibitor protein [Shigella sonnei] >SJI95156.1 host-nuclease inhibitor protein [Shigella sonnei] >SIY86865.1 host-nuclease inhibitor protein [Shigella sonnei] >SJJ67303.1 host-nuclease inhibitor protein [Shigella sonnei] >SJJ18596.1 host-nuclease inhibitor protein [Shigella sonnei] >SIX52979.1 host-nuclease inhibitor protein [Shigella sonnei] >SJD05143.1 host-nuclease inhibitor protein [Shigella sonnei] >SJD37118.1 host-nuclease inhibitor protein [Shigella sonnei]
>SJE51616.1 host-nuclease inhibitor protein [Shigella sonnei]
MAKPAKRIRNAAAAYVPQSRDAVVCDIRRIGDLQREAARLETEMNDAIAEITEKYAS QIAPLKTSIETLSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRQRPPSVSIRGV DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 715)
>WP_089552732.1 host-nuclease inhibitor protein Gam [Escherichia coli]
MAKPAKRIKNAAAAYVPQSRDAVVCDIRRIGDLQREAARLETEMNDAIAEITEKYAS QIAPLKTS IETIS KGVQGWCE ANRDELTNGGKVKT ANLVTGD VS WRQRPPS VS IRGV DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 716)
>WP_042856719.1 host-nuclease inhibitor protein Gam [Escherichia coli] >CDL02915.1 putative host-nuclease inhibitor protein [Escherichia coli IS35]
MAKPAKRIKNAAAAYVPQSRDAVVCDIRRIGDLQREAARLETEMNDAIADITEKYAS QIAPLKTSIETLSKGVQGWCEANRDELTNGGKVKT ANLVTGD VSWRQRPPSVSIRGV DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 717)
>WP_001129704.1 host-nuclease inhibitor protein Gam [Escherichia coli] >EDU62392.1 bacteriophage Mu Gam like protein [Escherichia coli 53638]
MAKSAKRIRNAAAAYVPQSRDAVVCDIRRIGNLQREAARLETEMNDAIAEITEKFAA RIAPLKTDIETLSKGVQGWCEANRDELTNGGKVKT ANLVTGD VSWRQRPPSVSIRGV D A VMETLERLGLQRFIRTKQEINREAILLEPKA VAGVAGIT VKS GIEDFS IIPFEQD AGI
(SEQ ID NO: 718)
>WP_001107936.1 MULTISPECIES: host-nuclease inhibitor protein Gam
[Enterobacteriaceae] >EGI94970.1 host-nuclease inhibitor protein gam [Shigella boydii 5216-82] >CSR34065.1 host-nuclease inhibitor protein [Shigella sonnet] >CSQ65903.1 host- nuclease inhibitor protein [Shigella sonnei] >CSQ94361.1 host-nuclease inhibitor protein [Shigella sonnei] >SJK23465.1 host-nuclease inhibitor protein [Shigella sonnei]
>SJB59111.1 host-nuclease inhibitor protein [Shigella sonnei] >SJI55768.1 host-nuclease inhibitor protein [Shigella sonnei] >SJI56601.1 host-nuclease inhibitor protein [Shigella sonnei] >SJJ20109.1 host-nuclease inhibitor protein [Shigella sonnei] >SJJ54643.1 host- nuclease inhibitor protein [Shigella sonnei] >S JI29650.1 host-nuclease inhibitor protein
[Shigella sonnei] >SIZ53226.1 host-nuclease inhibitor protein [Shigella sonnei]
>SJA65714.1 host-nuclease inhibitor protein [Shigella sonnei] >SJJ21793.1 host-nuclease inhibitor protein [Shigella sonnei] >SJD61405.1 host-nuclease inhibitor protein [Shigella
sonnei] >SJJ14326.1 host-nuclease inhibitor protein [Shigella sonnei] >SIZ57861.1 host- nuclease inhibitor protein [Shigella sonnei] >SJD58744.1 host-nuclease inhibitor protein [Shigella sonnei] >SJD84738.1 host-nuclease inhibitor protein [Shigella sonnei] >SJJ51125.1 host-nuclease inhibitor protein [Shigella sonnei] >SJD01353.1 host-nuclease inhibitor protein [Shigella sonnei] >SJE63176.1 host-nuclease inhibitor protein [Shigella sonnei]
MAKPAKRIRNAAAAYVPQSRDAVVCDIRRIGDLQREAARLETEMNDAIAEITEKYAS QIAPLKTSIETLSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRQRPPSVSIRGV DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQDAGI
(SEQ ID NO: 719)
>WP_050939550.1 host-nuclease inhibitor protein Gam [Escherichia coli] >KNF77791.1 host-nuclease inhibitor protein Gam [Escherichia coli]
MAKPAKRIKNAAAAYVPQSRDAVVCDIRRIGDLQREAARLETEMNDAIAEITEKYAS QIAPLKTS IETLS KGVQGWCEANRDELTNGGKVKTANLVTGD VS WRLRPPS VS IRGV DAVMETLERLGLQRFICTKQEINKEAILLEPKVVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 720)
>WP_085334715.1 host-nuclease inhibitor protein Gam [Escherichia coli] >OSC 16757.1 host-nuclease inhibitor protein Gam [Escherichia coli]
MAKPVKRIRNAAAAYVPQSRDAVVCDIRRIGDLQREAARLETEMNDAIAEITEKYAS QIAPLKTSIETLSKGIQGWCEANRDELTNGGKVKTANLVTGDVSWRQRPPSVSIRGV DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 721)
>WP_065226797.1 host-nuclease inhibitor protein Gam [Escherichia coli] >AN088858.1 host-nuclease inhibitor protein Gam [Escherichia coli] >ANO89006.1 host-nuclease inhibitor protein Gam [Escherichia coli]
MAKPAKRIRNAAAAYVPQSRDAVVCDIRWIGDLQREAVRLETEMNDAIAEITEKYA SRIAPLKTRIETLSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRQRPPSVSIRG VD A VMETLERLGLQRFIRTKQEINKE AILLEPKA VAGV AGIT VKS GIEDFS IIPFEQEA GI (SEQ ID NO: 722)
>WP_032239699.1 host-nuclease inhibitor protein Gam [Escherichia coli] >KDU26235.1 bacteriophage Mu Gam like family protein [Escherichia coli 3-373-03_S4_C2]
>KDU49057.1 bacteriophage Mu Gam like family protein [Escherichia coli 3-373- 03_S4_C1] >KEL21581.1 bacteriophage Mu Gam like family protein [Escherichia coli 3- 373-03_S4_C3]
MAKSAKRIRNAAATYVPQSRDAVVCDIRRIGDLQREAARLETEMNDAIAEITEKYAS QIAPLKTSIETLSKGIQGWCEANRDELTNGGKVKTANLVTGDVSWRQRPPSVSIRGV DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 723)
>WP_080172138.1 host-nuclease inhibitor protein Gam [Salmonella enterica]
MAKSAKRIKSAAATYVPQSRDAVVCDIRRIGDLQREAARLETEMNDAIAEITEKYAS QIAPLKTSIETLSKGVQGWCEANRDELTNGGKVKSANLVTGDVQWRQRPPSVSIRGV DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQEAGI
(SEQ ID NO: 724)
>WP_077134654.1 host-nuclease inhibitor protein Gam [Shigella sonnet] >SIZ51898.1 host- nuclease inhibitor protein [Shigella sonnet] >SJK07212.1 host-nuclease inhibitor protein [Shigella sonnet]
MAKSAKRIRNAAAAYVPQSRDAVVCDIRRIGNLQREAARLETEMNDAIAEITEKYAS QIAPLKTSIETLSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRQRPPSVSIRGV DAVMETLERLGLQRFIRTKQEINKEAILLEPKAVAGVAGITVKSGIEDFSIIPFEQDAGI
(SEQ ID NO: 725)
>WP_000261565.1 host-nuclease inhibitor protein Gam [Shigella flexneri] >EGK20651.1 host-nuclease inhibitor protein gam [Shigella flexneri K-272] >EGK34753.1 host-nuclease inhibitor protein gam [Shigella flexneri K-227]
MVVSAIASTPHDAVVCDIRRIGDLQREAARLETEMNDAIAEITEKDASQIAPLKTSIET LSKGVQGWCEANRDELTNGGKVKTANLVTGDVSWRQRPPSVSIRGVDAVMETLER LGLQRFIRTKQEINKE AILLEPKA VAGVAGIT VKS GIEDFS IIPFEQE AGI (SEQ ID NO: 726)
>ASG63807.1 host-nuclease inhibitor protein Gam [Kluyvera georgiana]
MVSKPKRIKAAAANYVSQSRDAVITDIRKIGDLQREATRLESAMNDEIAVITEKYAG LIKPLKADVEMLSKGVQGWCEANRDDLTSNGKVKTANLVTGDIQWRIRPPSVSVRG PDAVMETLTRLGLSRFIRTKQEINKEAILNEPLAVAGVAGITVKSGIEDFSIIPFEQTAD
I (SEQ ID NO: 727)
>WP_078000363.1 host-nuclease inhibitor protein Gam [Edwardsiella tarda]
MASKPKRIKSAAANYVSQSRDAVIIDIRKIGDLQREATRLESAMNDEIAVITEKYAGLI KPLKADVEMLSKGVQGWCEANRDELTCNGKVKTANLVTGDIQWRIRPPSVSVRGP DSVMETLLRLGLSRFIRTKQEINKEAILNEPLAVAGVAGITVKTGVEDFSIIPFEQTADI
(SEQ ID NO: 728)
>WP_047389411.1 host-nuclease inhibitor protein Gam [Citrobacter freundii]
>KGY86764.1 host-nuclease inhibitor protein Gam [Citrobacter freundii] >OIZ37450.1 host-nuclease inhibitor protein Gam [Citrobacter freundii]
MVS KPKRIKAAAANY VS QS KEA VIADIRKIGDLQRE ATRLES AMNDEIA VITEKYAG LIKPLKTDVEILSKGVQGWCEANRDELTSNGKVKTANLVTGDIQWRIRPPSVAVRGP DAVMETLLRLGLSRFIRTKQEINKEAILNEPLAVAGVAGITVKSGVEDFSIIPFEQTADI
(SEQ ID NO: 729)
>WP_058215121.1 host-nuclease inhibitor protein Gam [Salmonella enterica] >KSU39322.1 host-nuclease inhibitor protein Gam [Salmonella enterica subsp. enterica] >OHJ24376.1 host-nuclease inhibitor protein Gam [Salmonella enterica] >ASG15950.1 host-nuclease inhibitor protein Gam [Salmonella enterica subsp. enterica serovar Macclesfield str. S-1643] MASKPKRIKAAAALYVSQSREDVVRDIRMIGDFQREIVRLETEMNDQIAAVTLKYAD KIKPLQEQLKTLSEGVQNWCEANRSDLTNGGKVKTANLVTGDVQWRVRPPSVTVR GVDSVMETLRRLGLSRFIRIKEEINKEAILNEPGAVAGVAGITVKSGVEDFSIIPFEQSA TN (SEQ ID NO: 730)
>WP_016533308.1 phage host-nuclease inhibitor protein Gam [Pasteurella multocida] >EPE65165.1 phage host-nuclease inhibitor protein Gam [Pasteurella multocida P1933] >ESQ71800.1 host-nuclease inhibitor protein Gam [Pasteurella multocida subsp. multocida P1062] >ODS44103.1 host-nuclease inhibitor protein Gam [Pasteurella multocida]
>OPC87246.1 host-nuclease inhibitor protein Gam [Pasteurella multocida subsp. multocida] >OPC98402.1 host-nuclease inhibitor protein Gam [Pasteurella multocida subsp. multocida] M AKKATRIKTT AQ V Y VPQS RED V AS DIKTIGDLNREITRLETEMND KIAEITES YKGQ FSPIQERIKNLSTGVQFWAEANRDQITNGGKTKTANLITGEVSWRVRNPSVKITGVDS VLQNLKIHGLTKFIRVKEEINKEAILNEKHEVAGIAGIKVVSGVEDFVITPFEQEI (SEQ
ID NO: 731)
>WP_005577487.1 host-nuclease inhibitor protein Gam [Aggregatibacter
actinomycetemcomitans] >EHK90561.1 phage host-nuclease inhibitor protein Gam
[Aggregatibacter actinomycetemcomitans RhAAl] >KNE77613.1 host-nuclease inhibitor protein Gam [Aggregatibacter actinomycetemcomitans RhAAl]
MAKSATRVKATAQIYVPQTREDAAGDIKTIGDLNREVARLEAEMNDKIAAITEDYK DKFAPLQERIKTLSNGVQYWSEANRDQITNGGKTKTANLVTGEVSWRVRNPSVKVT GVDSVLQNLRIHGLERFIRTKEEINKEAILNEKSAVAGIAGIKVITGVEDFVITPFEQEA
A (SEQ ID NO: 732)
>WP_090412521.1 host-nuclease inhibitor protein Gam [Nitrosomonas halophila]
>SDX89267.1 Mu-like prophage host-nuclease inhibitor protein Gam [Nitrosomonas halophila]
MARNAARLKTKSIAYVPQSRDDAAADIRKIGDLQRQLTRTSTEMNDAIAAITQNFQP RMDAIKEQINLLQAGVQGYCEAHRHALTDNGRVKTANLITGEVQWRQRPPSVSIRG QQVVLETLRRLGLERFIRTKEEVNKEAILNEPDEVRGVAGLNVITGVEDFVITPFEQE QP (SEQ ID NO: 733)
>WP_077926574.1 host-nuclease inhibitor protein Gam [Wohlfahrtiimonas larvae]
MAKKRIKAAATVYVPQSKEEVQNDIREIGDISRKNERLETEMNDRIAEITNEYAPKFE VNKVRLELLTKGVQSWCEANRDDLTNSGKVKSANLVTGKVEWRQRPPSISVKGMD A VIEWLQDS KYQRFLRTKVEVNKE AMLNEPED AKTIPGITIKS GIEDFAITPFEQEAG V
(SEQ ID NO: 734)
Deaminase Domains
[00171] In some embodiments, the nucleobase editor useful in the present disclosure comprises: (i) a guide nucleotide sequence-programmable DNA-binding protein domain; and (ii) a deaminase domain. In certain embodiments, the deaminase domain of the fusion protein is a cytosine deaminase. In some embodiments, the deaminase is an APOBEC1 deaminase. In some embodiments, the deaminase is a rat APOBEC1. In some embodiments, the deaminase is a human APOBEC1. In some embodiments, the deaminase is an APOBEC2 deaminase. In some embodiments, the deaminase is an APOBEC3A deaminase. In some embodiments, the deaminase is an APOBEC3B deaminase. In some embodiments, the
deaminase is an APOBEC3C deaminase. In some embodiments, the deaminase is an APOBEC3D deaminase. In some embodiments, is an APOBEC3F deaminase. In some embodiments, the deaminase is an APOBEC3G deaminase. In some embodiments, the deaminase is an APOBEC3H deaminase. In some embodiments, the deaminase is an APOBEC4 deaminase. In some embodiments, the deaminase is an activation-induced deaminase (AID). In some embodiments, the deaminase is a Lamprey CDAl (pmCDAl). In some embodiments, the deaminase is a human APOBEC3G or a functional fragment thereof. In some embodiments, the deaminase is an APOBEC3G variant comprising mutations correspond to the D316R/D317R mutations in the human APOBEC3G. Exemplary, non- limiting cytosine deaminase sequences that may be used in accordance with the methods of the present disclosure are provided in Example 1 below.
[00172] In some embodiments, the cytosine deaminase is a wild type deaminase or a deaminase as set forth in SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, the cytosine deaminase domains of the fusion proteins provided herein include fragments of deaminases and proteins homologous to either a deaminase or a deaminase fragment. For example, in some embodiments, a deaminase domain may comprise a fragment of the amino acid sequence set forth in any of SEQ ID NOs: 1-260, 270-292, 315- 323, 680, or 682. In some embodiments, a deaminase domain comprises an amino acid sequence homologous to the amino acid sequence set forth in any of SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682, or an amino acid sequence homologous to a fragment of the amino acid sequence set forth in any of SEQ ID NOs: 1-260, 270-292, 315-323, 680, or 682. In some embodiments, proteins comprising a deaminase, a fragment of a deaminase, or a homolog of a deaminase are referred to as "deaminase variants." A deaminase variant shares homology to a deaminase, or a fragment thereof. For example a deaminase variant is at least about 70% identical, at least about 80% identical, at least about 90% identical, at least about 95% identical, at least about 96% identical, at least about 97% identical, at least about 98% identical, at least about 99% identical, at least about 99.5% identical, or at least about 99.9% identical to a wild type deaminase or a deaminase as set forth in any of SEQ ID NOs: 1-260, 270-292, or 315-323. In some embodiments, the deaminase variant comprises a fragment of the deaminase, such that the fragment is at least about 70% identical, at least about 80% identical, at least about 90% identical, at least about 95% identical, at least about 96% identical, at least about 97% identical, at least about 98% identical, at least about 99% identical, at least about 99.5% identical, or at least about 99.9% identical to the corresponding fragment of wild type deaminase or a deaminase as set forth in any of SEQ ID NOs: 1-260,
270-292, 315-323, 680, or 682. In some embodiments, the cytosine deaminase is at least at least about 70% identical, at least about 80% identical, at least about 90% identical, at least about 95% identical, at least about 96% identical, at least about 97% identical, at least about 98% identical, at least about 99% identical, at least about 99.5% identical, or at least about 99.9% identical to an APOBEC3G variant as set forth in SEQ ID NO: 291 or SEQ ID NO: 292, and comprises mutations corresponding to the D316E/D317R mutations in SEQ ID NO: 290.
[00173] In some embodiments, the cytosine deaminase domain is fused to the N- terminus of the guide nucleotide sequence-programmable DNA-binding protein domain. For example, the fusion protein may have an architecture of NH2-[cytosine deaminase] -[guide nucleotide sequence-programmable DNA-binding protein domain] -COOH. The "-" used in the general architecture above indicates the presence of an optional linker. The term "linker," as used herein, refers to a chemical group or a molecule linking two molecules or moieties, e.g., two domains of a fusion protein, such as, for example, a dCas9 domain and a cytosine deaminase domain. Typically, the linker is positioned between, or flanked by, two groups, molecules, or other moieties and connected to each one via a covalent bond, thus connecting the two. In some embodiments, the linker is an amino acid or a plurality of amino acids (e.g., a peptide or protein). In some embodiments, the linker is an organic molecule, group, polymer, or chemical moiety. In some embodiments, the linker is 5-100 amino acids in length, for example, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 30-35, 35-40, 40-45, 45-50, 50-60, 60-70, 70-80, 80-90, 90-100, 100-150, or 150-200 amino acids in length. Longer or shorter linkers are also contemplated. Linkers may be of any form known in the art. For example, the linker may be a linker from a website, such as www[dot]ibi[dot]vu[dot]nl/programs/linkerdbwww/ or from www[dot] ibi[dot]vu[dot]nl/programs/linkerdbwww/src/database.txt. The linkers may also be unstructured, structured, helical, or extended.
[00174] In some embodiments, the cytosine deaminase domain and the Cas9 domain are fused to each other via a linker. Various linker lengths and flexibilities between the deaminase domain (e.g., APOBEC1) and the Cas9 domain can be employed (e.g., ranging from flexible linkers of the form (GGGS)n (SEQ ID NO: 303), (GGGGS)n (SEQ ID NO: 304), (GGS)n, and (G)„ to more rigid linkers of the form (EAAAK)n (SEQ ID NO: 305, SGSETPGTSESATPES (SEQ ID NO: 306) (see, e.g., Guilinger et al, Nat. Biotechnol. 2014; 32(6): 577-82; the entire contents of which is incorporated herein by reference), (XP)n, or a combination of any of these, wherein X is any amino acid, and n is independently an
integer between 1 and 30, in order to achieve the optimal length for deaminase activity for the specific application. In some embodiments, n is independently 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, or 30, or, if more than one linker or more than one linker motif is present, any combination thereof. In some
embodiments, the linker comprises a (GGS)n motif, wherein n is 1,2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15. In some embodiments, the linker comprises a (GGS)n motif, wherein n is 1, 3, or 7. In some embodiments, the linker comprises the amino acid sequence
SGSETPGTSESATPES (SEQ ID NO: 306), also referred to as the XTEN linker. In some embodiments, the linker comprises an amino acid sequence chosen from the group including, but not limited to, AGVF (SEQ ID NO: 307), GFLG (SEQ ID NO: 308), FK, AL, ALAL (SEQ ID NO: 349), and ALALA (SEQ ID NO: 309). In some embodiments, suitable linker motifs and configurations include those described in Chen et ah, Fusion protein linkers: property, design and functionality. Adv Drug Deliv Rev. 2013; 65(10): 1357-69, which is incorporated herein by reference. In some embodiments, the linker may comprise any of the following amino acid sequences: VPFLLEPDNINGKTC (SEQ ID NO: 350),
GSAGSAAGSGEF (SEQ ID NO: 351), SIVAQLSRPDPA (SEQ ID NO: 352),
MKIIEQLPSA (SEQ ID NO: 353), VRHKLKRVGS (SEQ ID NO: 354), GHGTGSTGSGSS (SEQ ID NO: 355), MSRPDPA (SEQ ID NO: 356), GSAGSAAGSGEF (SEQ ID NO: 357), SGSETPGTSESA (SEQ ID NO: 358), SGSETPGTSESATPEGGSGGS (SEQ ID NO: 359), and GGSM (SEQ ID NO: 360). Additional suitable linker sequences will be apparent to those of skill in the art based on the instant disclosure.
[00175] To successfully edit the desired target C base, the linker between Cas9 and
APOBEC may be optimized, as described in Komor et al., Nature, 533, 420-424 (2016), which is incorporated herein by reference. The numbering scheme for base editing is based on the predicted location of the target C within the single stranded stretch of DNA (R-loop) displaced by a programmable guide RNA sequence occurring when a DNA -binding domain (e.g. Cas9, nCas9, dCas9) binds a genomic site (see Figure 4). Conveniently, the sequence immediately surrounding the target C also matches the sequence of the guide RNA, which may be used as a reference as done in the Tables herein. The numbering scheme for base editing is based on a standard 20-mer programmable sequence, and defines position "21" as the first DNA base of the PAM sequence, resulting in position "1" assigned to the first DNA base matching the 5 '-end of the 20-mer programmable guide RNA sequence. Therefore, for all Cas9 variants, position "21" is defined as the first base of the PAM sequence (e.g. NGG, NGAN, NGNG, NGAG, NGCG, NNGRRT, NGRRN, NNNRRT, NNNGATT, NNAGAA,
NAAAC). When a longer programmable guide RNA sequence is used (e.g. 21-mer) the 5'- end bases are assigned a decreasing negative number starting at "-1". For other DNA- binding domains that differ in the position of the PAM sequence, or that require no PAM sequence, the programmable guide RNA sequence is used as a reference for numbering. A 3- aa linker gives a 2-5 base editing window (e.g., positions 2, 3, 4, or 5 relative to the PAM sequence in positions 20-23). A 9-aa linker gives a 3-6 base editing window (e.g., positions 3, 4, 5, or 6 relative to the PAM sequence at position 21). A 16-aa linker (e.g., the
SGSETPGTSESATPES (SEQ ID NO: 306) linker) gives a 4-7 base editing window (e.g., positions 4, 5, 6, or 7 relative to the PAM sequence at position 21). A 21-aa linker gives a 5- 8 base editing window (e.g., positions 5, 6, 7, 8 relative to the PAM sequence at position 21). Each of these windows can be useful for editing different targeted C bases. For example, the targeted C bases may be at different distances from the adjacent PAM sequence, and by varying the linker length, the precise editing of the desired C base is ensured. One skilled in the art, based on the teachings of CRISPR/Cas9 technology, in particular the teachings of US Provisional Applications, 62/245,828, 62/279,346, 62/311,763, 62/322,178, 62/357,352, 62/370,700, and 62/398,490, and in Komor et ah, Nature, "Programmable editing of a target base in genomic DNA without double-stranded DNA cleavage," 533, 420-424 (2016), each of which is incorporated herein by reference, will be able to determine the editing window for his/her purpose, and properly design the linker of the cytosine deaminase-dCas9 protein for the precise targeting of the desired C base. To successfully edit the desired target C base, the sequence identity of the homolog of Cas9 attached to APOBEC may be optimized based on the teachings of CRISPR/Cas9 technology. As a non-limiting example, the teachings of any of the following documents may be used: U.S. Provisional Application Nos. 62/245,828, 62/279,346, 62/311,763, 62/322,178, 62/357,352, 62/370,700, and 62/398,490, and Komor et ah, Nature, 533, 420-424 (2016), each of which is incorporated herein by reference in its entirety. APOBECl-XTEN-SaCas9n-UGI gives a 1-12 base editing window (e.g., positions 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, or 12 relative to the NNNRRT PAM sequence in positions 20-26). One skilled in the art, based on the teachings of CRISPR/Cas9 technology, will be able to determine the editing window for his/her purpose, and properly determine the required Cas9 homolog and linker attached to the cytosine deaminase for the precise targeting of the desired C base.
[00176] In some embodiments, the fusion protein useful in the present disclosure further comprises a uracil glycosylase inhibitor (UGI) domain. A "uracil glycosylase inhibitor" refers to a protein that inhibits the activity of uracil-DNA glycosylase. The C to T
base change induced by deamination results in a U:G heteroduplex, which triggers a cellular DNA-repair response. Uracil DNA glycosylase (UDG) catalyzes removal of U from DNA in cells and initiates base excision repair, with reversion of the U:G pair to a C:G pair as the most common outcome. Thus, such cellular DNA-repair response may be responsible for the decrease in nucleobase editing efficiency in cells. Uracil DNA Glycosylase Inhibitor (UGI) is known in the art to potently blocks human UDG activity. As described in Komor et ah, Nature (2016), fusing a UGI domain to the cytidine deaminase-dCas9 fusion protein reduced the activity of UDG and significantly enhanced editing efficiency.
[00177] Suitable UGI protein and nucleotide sequences are provided herein and additional suitable UGI sequences are known to those in the art, and include, for example, those published in Wang et ah, Uracil-DNA glycosylase inhibitor gene of bacteriophage PBS2 encodes a binding protein specific for uracil-DNA glycosylase. J. Biol. Chem.
264: 1163-1171(1989); Lundquist et ah, Site-directed mutagenesis and characterization of uracil-DNA glycosylase inhibitor protein. Role of specific carboxylic amino acids in complex formation with Escherichia coli uracil-DNA glycosylase. J. Biol. Chem.
272:21408-21419(1997); Ravishankar et ah, X-ray analysis of a complex of Escherichia coli uracil DNA glycosylase (EcUDG) with a proteinaceous inhibitor. The structure elucidation of a prokaryotic UDG. Nucleic Acids Res. 26:4880-4887(1998); and Putnam et al, Protein mimicry of DNA from crystal structures of the uracil-DNA glycosylase inhibitor protein and its complex with Escherichia coli uracil-DNA glycosylase. J. Mol. Biol. 287:331- 346(1999), each of which is incorporated herein by reference. In some embodiments, the UGI comprises the following amino acid sequence:
Bacillus phage PBS2 (Bacteriophage PBS2)Uracil-DNA glycosylase inhibitor
MTNLSDIIEKETGKQLVIQESILMLPEEVEEVIGNKPESDILVHTAYDESTDENVMLLT S D APE YKPW ALVIQDS NGENKIKML (SEQ ID NO: 361)
[00178] In some embodiments, the UGI protein comprises a wild type UGI or a UGI as set forth in SEQ ID NO: 361. In some embodiments, the UGI proteins useful in the present disclosure include fragments of UGI and proteins homologous to a UGI or a UGI fragment. For example, in some embodiments, a UGI comprises a fragment of the amino acid sequence set forth in SEQ ID NO: 361. In some embodiments, a UGI comprises an amino acid sequence homologous to the amino acid sequence set forth in SEQ ID NO: 361 or an amino acid sequence homologous to a fragment of the amino acid sequence set forth in SEQ ID NO:
361. In some embodiments, proteins comprising UGI or fragments of UGI or homologs of either UGI or UGI fragments are referred to as "UGI variants." A UGI variant shares homology with UGI, or a fragment thereof. For example, a UGI variant is at least about 70% identical, at least about 80% identical, at least about 85% identical, at least about 90% identical, at least about 95% identical, at least about 96% identical, at least about 97% identical, at least about 98% identical, at least about 99% identical, at least about 99.5% identical, or at least about 99.9% identical to a wild type UGI or a UGI as set forth in SEQ ID NO: 361. In some embodiments, the UGI variant comprises a fragment of UGI, such that the fragment is at least about 70% identical, at least about 80% identical, at least about 90% identical, at least about 95% identical, at least about 96% identical, at least about 97% identical, at least about 98% identical, at least about 99% identical, at least about 99.5% identical, or at least about 99.9% identical to the corresponding fragment of wild type UGI or a UGI as set forth in SEQ ID NO: 361.
[00179] It should be appreciated that additional proteins may be uracil glycosylase inhibitors. For example, other proteins that are capable of inhibiting (e.g., sterically blocking) a uracil-DNA glycosylase base-excision repair enzyme are within the scope of this disclosure. In some embodiments, a uracil glycosylase inhibitor is a protein that binds DNA. In some embodiments, a uracil glycosylase inhibitor is a protein that binds single-stranded DNA. For example, a uracil glycosylase inhibitor may be a Erwinia tasmaniensis single- stranded binding protein. In some embodiments, the single-stranded binding protein comprises the amino acid sequence (SEQ ID NO: 362). In some embodiments, a uracil glycosylase inhibitor is a protein that binds uracil. In some embodiments, a uracil glycosylase inhibitor is a protein that binds uracil in DNA. In some embodiments, a uracil glycosylase inhibitor is a catalytically inactive uracil DNA-glycosylase protein. In some embodiments, a uracil glycosylase inhibitor is a catalytically inactive uracil DNA-glycosylase protein that does not excise uracil from the DNA. For example, a uracil glycosylase inhibitor is a UdgX. In some embodiments, the UdgX comprises the amino acid sequence (SEQ ID NO: 363). As another example, a uracil glycosylase inhibitor is a catalytically inactive UDG. In some embodiments, a catalytically inactive UDG comprises the amino acid sequence (SEQ ID NO: 364). It should be appreciated that other uracil glycosylase inhibitors would be apparent to the skilled artisan and are within the scope of this disclosure. In some
embodiments, the fusion protein comprises a guide nucleotide sequence-programmable DNA-binding protein, a cytidine deaminase domain, a Gam protein, and a UGI domain. In some embodiments, any of the fusion proteins provided herein that comprise a guide
nucleotide sequence-programmable DNA-binding protein (e.g., a Cas9 domain), a cytidine deaminase, and a Gam protein may be further fused to a UGI domain either directly or via a linker. This disclosure also contemplates a fusion protein comprising a Cas9 nickase-nucleic acid editing domain fused to a cytidine deaminase and a Gam protein, which is further fused to a UGI domain.
Erwinia tasmaniensis SSB (themostable single- stranded DNA binding protein)
MASRGVNKVILVGNLGQDPEVRYMPNGGAVANITLATSESWRDKQTGETKEKTEW HRVVLFGKLAEVAGEYLRKGSQVYIEGALQTRKWTDQAGVEKYTTEVVVNVGGT MQMLGGRSQGGGASAGGQNGGSNNGWGQPQQPQGGNQFSGGAQQQARPQQQPQ QNNAPANNEPPIDFDDDIP (SEQ ID NO: 362)
UdgX (binds to Uracil in DNA but does not excise)
MAGAQDFVPHTADLAELAAAAGECRGCGLYRDATQAVFGAGGRSARIMMIGEQPG DKEDLAGLPFVGPAGRLLDRALEAADIDRDALYVTNAVKHFKFTRAAGGKRRIHKT PSRTEVVACRPWLIAEMTSVEPDVVVLLGATAAKALLGNDFRVTQHRGEVLHVDDV PGDPALVATVHPSSLLRGPKEERESAFAGLVDDLRVAADVRP (SEQ ID NO: 363)
UDG (catalytically inactive human UDG, binds to Uracil in DNA but does not excise) MIGQKTLYS FFS PS P ARKRH APS PEP A VQGTG V AG VPEES GD A A AIP AKKAP AGQEE PGTPPSSPLSAEQLDRIQRNKAAALLRLAARNVPVGFGESWKKHLSGEFGKPYFIKL MGFVAEERKHYTVYPPPHQVFTWTQMCDIKDVKVVILGQEPYHGPNQAHGLCFSV QRP VPPPPS LENIYKELS TDIEDFVHPGHGDLS GW AKQG VLLLN A VLT VRAHQ ANS H KERGWEQFTDAVVSWLNQNSNGLVFLLWGSYAQKKGSAIDRKRHHVLQTAHPSPL S VYRGFFGCRHFS KTNELLQKS GKKPIDWKEL (SEQ ID NO: 364)
[00180] In some embodiments, the UGI domain is fused to the C-terminus of the dCas9 domain in the fusion protein. Thus, the fusion protein would have an architecture of NH2-[cytosine deaminase] -[guide nucleotide sequence-programmable DNA-binding protein domain]-[UGI]-COOH. In some embodiments, the UGI domain is fused to the N-terminus of the cytosine deaminase domain. As such, the fusion protein would have an architecture of NH2-[UGI]-[cytosine deaminase] -[guide nucleotide sequence-programmable DNA-binding protein domain]-COOH. In some embodiments, the UGI domain is fused between the guide nucleotide sequence-programmable DNA-binding protein domain and the cytosine deaminase
domain. As such, the fusion protein would have an architecture of NH2-[cytosine
deaminase] -[UGI] -[guide nucleotide sequence-programmable DNA-binding protein domain] - COOH. The linker sequences described herein may also be used for the fusion of the UGI domain to the cytosine deaminase-dCas9 fusion proteins.
[00181] In some embodiments, the fusion protein comprises the structure:
[cytosine deaminase] -[optional linker sequence] -[guide nucleotide sequence-programmable
DNA binding protein] -[optional linker sequence] -[UGI];
[cytosine deaminase] -[optional linker sequence] -[UGI] -[optional linker sequence] -[ guide nucleotide sequence-programmable DNA binding protein] ;
[UGI] -[optional linker sequence] -[cytosine deaminase] -[optional linker sequence] -[guide nucleotide sequence-programmable DNA binding protein] ;
[UGI] -[optional linker sequence] -[guide nucleotide sequence-programmable DNA binding protein] -[optional linker sequence] -[cytosine deaminase];
[guide nucleotide sequence-programmable DNA binding protein] -[optional linker sequence] - [cytosine deaminase] -[optional linker sequence] -[UGI]; or
[guide nucleotide sequence-programmable DNA binding protein] -[optional linker sequence] -
[UGI] -[optional linker sequence] -[cytosine deaminase].
[00182] In some embodiments, the fusion protein is of the structure:
[cytosine deaminase] -[optional linker sequence] -[Cas9 nickase]- [optional linker sequence] -
[UGI]; [cytosine deaminase] -[optional linker sequence] -[UGI] -[optional linker sequence]-
[Cas9 nickase] ; [UGI] - [optional linker sequence] - [cytosine deaminase] - [optional linker sequence] -[Cas9 nickase]; [UGI] -[optional linker sequence]-[Cas9 nickase] -[optional linker sequence] - [cytosine deaminase] ; [Cas9 nickase] - [optional linker sequence] - [cytosine deaminase] -[optional linker sequence] -[UGI]; or [Cas9 nickase] -[optional linker sequence]-
[UGI]- [optional linker sequence] -[cytosine deaminase].
[00183] In some embodiments, fusion proteins provided herein further comprise a nuclear localization sequence (NLS). In some embodiments, the NLS is fused to the N- terminus of the fusion protein. In some embodiments, the NLS is fused to the C-terminus of the fusion protein. In some embodiments, the NLS is fused to the N-terminus of the UGI protein. In some embodiments, the NLS is fused to the C-terminus of the UGI protein. In some embodiments, the NLS is fused to the N-terminus of the guide nucleotide sequence- programmable DNA-binding protein domain. In some embodiments, the NLS is fused to the C-terminus of the guide nucleotide sequence-programmable DNA-binding protein domain. In some embodiments, the NLS is fused to the N-terminus of the cytosine deaminase. In
some embodiments, the NLS is fused to the C-terminus of the deaminase. In some embodiments, the NLS is fused to the fusion protein via one or more linkers. In some embodiments, the NLS is fused to the fusion protein without a linker. Non-limiting, exemplary NLS sequences may be PKKKRKV (SEQ ID NO: 365) or
MDS LLMNRRKFLYQFKNVRW AKGRRET YLC (SEQ ID NO: 366).
[00184] Some aspects of the present disclosure provide nucleobase editors described herein associated with a guide nucleotide sequence (e.g., a guide RNA or gRNA). gRNAs can exist as a complex of two or more RNAs, or as a single RNA molecule. gRNAs that exist as a single RNA molecule may be referred to as single-guide RNAs (sgRNAs), though "gRNA" is used interchangeably to refer to guide RNAs that exist as either single molecules or as a complex of two or more molecules. Typically, gRNAs that exist as a single RNA species comprise two domains: (1) a domain that shares homology to a target nucleic acid (e.g., and directs binding of the Cas9 complex to the target); and (2) a domain that binds the Cas9 protein. In some embodiments, domain (2) corresponds to a sequence known as a tracrRNA, and comprises a stem-loop structure. For example, in some embodiments, domain (2) is identical or homologous to a tracrRNA as provided in Jinek et al., Science 337:816- 821(2012), which is incorporated herein by reference. Other examples of gRNAs (e.g., those including domain 2) can be found in U.S. Provisional Patent Application, U.S. S.N.
61/874,682, filed September 6, 2013, entitled "Switchable Cas9 Nucleases And Uses Thereof," and U.S. Provisional Patent Application, U.S. S.N. 61/874,746, filed September 6, 2013, entitled "Delivery System For Functional Nucleases," each are hereby incorporated by reference in their entirety. The gRNA comprises a nucleotide sequence that complements a target site, which mediates binding of the nuclease/RNA complex to said target site, providing the sequence specificity of the nuclease:RNA complex. These proteins are able to be targeted, in principle, to any sequence specified by the guide RNA. Methods of using RNA-programmable nucleases, such as Cas9, for site-specific cleavage (e.g., to modify a genome) are known in the art (see e.g., Cong, L. et al. Science 339, 819-823 (2013); Mali, P. et al. Science 339, 823-826 (2013); Hwang, W.Y. et al. Nature Biotechnology 31, 227-229 (2013); Jinek, M. et al. eLife 2, e00471 (2013); Dicarlo, J.E. et al. Nucleic acids research (2013); Jiang, W. et al. Nature Biotechnology 31, 233-239 (2013); the entire contents of each of which are incorporated herein by reference). In particular, examples of guide nucleotide sequences (e.g., sgRNAs) that may be used to target the fusion protein of the present disclosure to its target sequence to deaminate the targeted C bases are described in Komor et al., Nature, 533, 420-424 (2016), which is incorporated herein by reference.
[00185] The specific structure of the guide nucleotide sequences (e.g., sgRNAs) depends on its target sequence and the relative distance of a PAM sequence downstream of the target sequence. One skilled in the art will understand, that no unifying structure of guide nucleotide sequence is given, because the target sequences are different for each and every C targeted to be deaminated.
[00186] However, the present disclosure provides guidance in how to design the guide nucleotide sequence, e.g., an sgRNA, so that one skilled in the art may use such teachings to design these for a target sequence of interest. A gRNA typically comprises a tracrRNA framework allowing for Cas9 binding, and a guide sequence, which confers sequence specificity to fusion proteins disclosed herein to target the CCR5 gene. In some
embodiments, the guide RNA comprises a structure 5'-[guide sequence]- tracrRNA-3' . Non- limiting, exemplary tracrRNA sequences are shown in Table 10. The tracrRNA sequence may vary from the presented sequences.
Table 10. TracrRNA othologues and sequences
[00187] The guide sequence of the gRNA comprises a sequence that is complementary to the target sequence. The guide sequence is typically about 20 nucleotides long. For
example, the guide sequence may be 15-25 nucleotides long. In some embodiments, the guide sequence is 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 nucleotides long. In some embodiments, the guide sequence is more than 25 nucleotides long. Such suitable guide RNA sequences typically comprise guide sequences that are complementary to a nucleic sequence within 50 nucleotides upstream or downstream of the target nucleotide to be edited.
[00188] In some embodiments, the guide RNA is about 15-100 nucleotides long and comprises a sequence of at least 10 contiguous nucleotides that is complementary to a target sequence. In some embodiments, the guide RNA is 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, or 50 nucleotides long. In some embodiments, the guide RNA comprises a sequence of 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, or 40 contiguous nucleotides that is complementary to a target sequence.
Compositions
[00189] Aspects of the present disclosure relate to compositions that may be used for editing CCR5-encoding polynucleotides, CCR2-encoding polynucleotides, or both CCR5- encoding polynucleotides and CCR2-encoding polynucleotides. In some embodiments, the editing is carried out in vitro. In some embodiments, the editing is carried out in a cultured cell. In some embodiments, the editing is carried out in vivo. In some embodiments, the editing is carried out in a mammal. In some embodiments, the mammal is a human. In some embodiments, the mammal may be a rodent. In some embodiments, the editing is carried out ex vivo.
[00190] In some embodiments, the composition comprises: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; and (ii) a guide nucleotide sequence targeting the fusion protein of (i) to a polynucleotide encoding a C-C chemokine receptor type 5 (CCR5) protein.
[00191] In some embodiments, the composition comprises: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; (ii) a guide nucleotide sequence targeting the fusion protein of (i) to a polynucleotide encoding a C-C chemokine receptor type 2 (CCR2) protein.
[00192] In some embodiments, the composition comprises: (i) a fusion protein comprising: (a) a guide nucleotide sequence-programmable DNA binding protein domain; and (b) a cytosine deaminase domain; (ii) a guide nucleotide sequence targeting the fusion
protein of (i) to a polynucleotide encoding a C-C chemokine receptor type 5 (CCR5) protein; (iii) a guide nucleotide sequence targeting the fusion protein of (i) to a polynucleotide encoding a C-C chemokine receptor type 2 (CCR2) protein.
[00193] The guide nucleotide sequence used in the compositions described herein for editing the CCR5-encoding polynucleotide is selected from SEQ ID NOs: 381-657. In some embodiments, the composition comprises a nucleic acid encoding a fusion protein described herein and a guide nucleotide sequence described herein. In some embodiments, the composition described herein further comprises a pharmaceutically acceptable carrier. In some embodiments, the nucleobase editor (i.e., the fusion protein) and the gRNA are provided in two different compositions.
[00194] As used here, the term "pharmaceutically-acceptable carrier" means a pharmaceutically-acceptable material, composition or vehicle, such as a liquid or solid filler, diluent, excipient, manufacturing aid (e.g., lubricant, talc magnesium, calcium or zinc stearate, or steric acid), or solvent encapsulating material, involved in carrying or transporting the compound from one site (e.g., the delivery site) of the body to another site (e.g., organ, tissue or portion of the body). A pharmaceutically acceptable carrier is "acceptable" in the sense of being compatible with the other ingredients of the formulation and not injurious to the tissue of the subject (e.g., physiologically compatible, sterile, having physiologic pH, etc.). Some examples of materials which can serve as pharmaceutically-acceptable carriers include: (1) sugars, such as lactose, glucose and sucrose; (2) starches, such as corn starch and potato starch; (3) cellulose, and its derivatives, such as sodium carboxymethyl cellulose, methylcellulose, ethyl cellulose, microcrystalline cellulose, and cellulose acetate; (4) powdered tragacanth; (5) malt; (6) gelatin; (7) lubricating agents, such as magnesium stearate, sodium lauryl sulfate, and talc; (8) excipients, such as cocoa butter and suppository waxes; (9) oils, such as peanut oil, cottonseed oil, safflower oil, sesame oil, olive oil, corn oil, and soybean oil; (10) glycols, such as propylene glycol; (11) polyols, such as glycerin, sorbitol, mannitol, and polyethylene glycol (PEG); (12) esters, such as ethyl oleate and ethyl laurate; (13) agar; (14) buffering agents, such as magnesium hydroxide and aluminum hydroxide; (15) alginic acid; (16) pyrogen-free water; (17) isotonic saline; (18) Ringer's solution; (19) ethyl alcohol; (20) pH buffered solutions; (21) polyesters, polycarbonates and/or polyanhydrides; (22) bulking agents, such as polypeptides and amino acids (23) serum component, such as serum albumin, HDL and LDL; (22) C2-C12 alcohols, such as ethanol; and (23) other non-toxic compatible substances employed in pharmaceutical formulations. Wetting agents, coloring agents, release agents, coating agents, sweetening agents, flavoring
agents, perfuming agents, preservatives, and antioxidants can also be present in the formulation. The terms such as "excipient," "carrier," "pharmaceutically acceptable carrier," or the like are used interchangeably herein.
[00195] In some embodiments, the nucleobase editors and the guide nucleotides in a composition of the present disclosure are administered by injection, by means of a catheter, by means of a suppository, or by means of an implant, the implant being of a porous, non- porous, or gelatinous material, including a membrane, such as a sialastic membrane, or a fiber. In some embodiments, the nucleobase editors and the guide nucleotides in a composition of the present disclosure are administered by injection into the bloodstream.
[00196] In other embodiments, the nucleobase editors and the guide nucleotides are delivered in a controlled release system. In one embodiment, a pump may be used (see, e.g., Langer, 1990, Science 249: 1527-1533; Sefton, 1989, CRC Crit. Ref. Biomed. Eng. 14:201; Buchwald et al., 1980, Surgery 88:507; Saudek et al, 1989, N. Engl. J. Med. 321:574, the entire contents of each of which are incorporated herein by reference). In another
embodiment, polymeric materials can be used (See, e.g., Medical Applications of Controlled Release (Langer and Wise eds., CRC Press, Boca Raton, Fla., 1974); Controlled Drug Bioavailability, Drug Product Design and Performance (Smolen and Ball eds., Wiley, New York, 1984); Ranger and Peppas, 1983, Macromol. Sci. Rev. Macromol. Chem. 23:61; See also: Levy et al, 1985, Science 228: 190; During et al, 1989, Ann. Neurol. 25:351; Howard et al., 1989, J. Neurosurg. 71: 105, each of which is incorporated herein by reference). Other controlled release systems are discussed, for example, in Langer, supra.
[00197] In typical embodiments, the pharmaceutical composition is formulated in accordance with routine procedures as a pharmaceutical composition adapted for intravenous or subcutaneous administration to a subject, e.g., a human. Typically, compositions for administration by injection are solutions in sterile isotonic aqueous buffer. Where necessary, the pharmaceutical can also include a solubilizing agent and a local anesthetic such as lignocaine to ease pain at the site of the injection. Generally, the ingredients are supplied either separately or mixed together in a unit dosage form, for example, as a dry lyophilized powder or water free concentrate in a hermetically sealed container such as an ampoule or sachette indicating the quantity of active agent. Where the pharmaceutical is to be administered by infusion, it can be dispensed with an infusion bottle containing sterile pharmaceutical grade water or saline. Where the pharmaceutical is administered by injection, an ampoule of sterile water for injection or saline can be provided so that the ingredients can be mixed prior to administration.
[00198] A pharmaceutical composition for systemic administration may be a liquid, e.g., sterile saline, lactated Ringer's or Hank's solution. In addition, the pharmaceutical composition can be in solid forms and re-dissolved or suspended immediately prior to use. Lyophilized forms are also contemplated.
[00199] The pharmaceutical composition can be contained within a lipid particle or vesicle, such as a liposome or microcrystal, which is also suitable for parenteral
administration. The particles can be of any suitable structure, such as unilamellar or plurilamellar, so long as compositions are contained therein. Compounds can be entrapped in 'stabilized plasmid-lipid particles' (SPLP) containing the fusogenic lipid
dioleoylphosphatidylethanolamine (DOPE), low levels (5-10 mol%) of cationic lipid, and stabilized by a polyethyleneglycol (PEG) coating (Zhang Y. P. et al., Gene Ther. 1999, 6: 1438-47, the entire contents of which is incorporated herein by reference). Positively charged lipids such as N-[l-(2,3-dioleoyloxi)propyl]-N,N,N-trimethyl- amoniummethylsulfate, or "DOTAP," are particularly preferred for such particles and vesicles. The preparation of such lipid particles is well known. See, e.g., U.S. Patent Nos. 4,880,635; 4,906,477; 4,911,928; 4,917,951; 4,920,016; and 4,921,757, each of which is incorporated herein by reference.
[00200] The pharmaceutical compositions of this disclosure may be administered or packaged as a unit dose, for example. The term "unit dose" when used in reference to a pharmaceutical composition of the present disclosure refers to physically discrete units suitable as unitary dosage for the subject, each unit containing a predetermined quantity of active material calculated to produce the desired therapeutic effect in association with the required diluent; i.e., carrier, or vehicle.
[00201] In some embodiments, the nucleobase editors or the guide nucleotides described herein may be conjugated to a therapeutic moiety, e.g., an anti-inflammatory agent. Techniques for conjugating such therapeutic moieties to polypeptides, including e.g., Fc domains, are well known; see, e.g., Amon et al., "Monoclonal Antibodies For
Immunotargeting Of Drugs In Cancer Therapy", in Monoclonal Antibodies And Cancer Therapy, Reisfeld et al. (eds.), 1985, pp. 243-56, Alan R. Liss, Inc.); Hellstrom et al., "Antibodies For Drug Delivery", in Controlled Drug Delivery (2nd Ed.), Robinson et al. (eds.), 1987, pp. 623-53, Marcel Dekker, Inc.); Thorpe, "Antibody Carriers Of Cytotoxic Agents In Cancer Therapy: A Review", in Monoclonal Antibodies '84: Biological And Clinical Applications, Pinchera et al. (eds.), 1985, pp. 475-506); "Analysis, Results, And Future Prospective Of The Therapeutic Use Of Radiolabeled Antibody In Cancer Therapy",
in Monoclonal Antibodies For Cancer Detection And Therapy, Baldwin et al. (eds.), 1985, pp. 303-16, Academic Press; and Thorpe et al. (1982) "The Preparation And Cytotoxic Properties Of Antibody-Toxin Conjugates," Immunol. Rev., 62: 119-158; each of which is incorporated herein by reference.
[00202] Further, the compositions of the present disclosure may be assembled into kits.
In some embodiments, the kit comprises nucleic acid vectors for the expression of the nucleobase editors described herein. In some embodiments, the kit further comprises appropriate guide nucleotide sequences (e.g., gRNAs) or nucleic acid vectors for the expression of such guide nucleotide sequences, to target the nucleobase editors to the desired target sequence.
[00203] The kit described herein may include one or more containers housing components for performing the methods described herein and optionally instructions of uses. Any of the kit described herein may further comprise components needed for performing the assay methods. Each component of the kits, where applicable, may be provided in liquid form (e.g., in solution), or in solid form, (e.g., a dry powder). In certain cases, some of the components may be reconstitutable or otherwise processible (e.g., to an active form), for example, by the addition of a suitable solvent or other species (for example, water or certain organic solvents), which may or may not be provided with the kit.
[00204] In some embodiments, the kits may optionally include instructions and/or promotion for use of the components provided. As used herein, "instructions" can define a component of instruction and/or promotion, and typically involve written instructions on or associated with packaging of the disclosure. Instructions also can include any oral or electronic instructions provided in any manner such that a user will clearly recognize that the instructions are to be associated with the kit, for example, audiovisual (e.g., videotape, DVD, etc.), Internet, and/or web-based communications, etc. The written instructions may be in a form prescribed by a governmental agency regulating the manufacture, use, or sale of pharmaceuticals or biological products, which can also reflect approval by the agency of manufacture, use or sale for animal administration. As used herein, "promoted" includes all methods of doing business including methods of education, hospital and other clinical instruction, scientific inquiry, drug discovery or development, academic research,
pharmaceutical industry activity including pharmaceutical sales, and any advertising or other promotional activity including written, oral and electronic communication of any form, associated with the disclosure. Additionally, the kits may include other components depending on the specific application, as described herein.
[00205] The kits may contain any one or more of the components described herein in one or more containers. The components may be prepared sterilely, packaged in a syringe, and shipped refrigerated. Alternatively it may be housed in a vial or other container for storage. A second container may have other components prepared sterilely. Alternatively the kits may include the active agents premixed and shipped in a vial, tube, or other container.
[00206] The kits may have a variety of forms, such as a blister pouch, a shrink wrapped pouch, a vacuum sealable pouch, a sealable thermoformed tray, or a similar pouch or tray form, with the accessories loosely packed within the pouch, one or more tubes, containers, a box or a bag. The kits may be sterilized after the accessories are added, thereby allowing the individual accessories in the container to be otherwise unwrapped. The kits can be sterilized using any appropriate sterilization techniques, such as radiation sterilization, heat sterilization, or other sterilization methods known in the art. The kits may also include other components, depending on the specific application, for example, containers, cell media, salts, buffers, reagents, syringes, needles, a fabric such as gauze, for applying or removing a disinfecting agent, disposable gloves, a support for the agents prior to administration, etc.
Therapeutics
[00207] The compositions and kits described herein may be administered to a subject in need thereof, in a therapeutically effective amount, to prevent or treat conditions related to HIV infection and/or AIDS. The compositions and kits are effective in preventing or treating HIV infection in the subject or reducing the potential for HIV infection in the subject (including prevention of HIV infection in a subject).
[00208] "A therapeutically effective amount" as used herein refers to the amount of each therapeutic agent of the present disclosure required to confer therapeutic effect on the subject, either alone or in combination with one or more other therapeutic agents. Effective amounts vary, as recognized by those skilled in the art, depending on the particular condition being treated, the severity of the condition, the individual subject parameters including age, physical condition, size, gender and weight, the duration of the treatment, the nature of concurrent therapy (if any), the specific route of administration and like factors within the knowledge and expertise of the health practitioner. These factors are well known to those of ordinary skill in the art and can be addressed with no more than routine experimentation. It is generally preferred that a maximum dose of the individual components or combinations thereof be used, that is, the highest safe dose according to sound medical judgment. It will be understood by those of ordinary skill in the art, however, that a subject may insist upon a
lower dose or tolerable dose for medical reasons, psychological reasons or for virtually any other reasons. Empirical considerations, such as the half-life, generally will contribute to the determination of the dosage. For example, therapeutic agents that are compatible with the human immune system, such as polypeptides comprising regions from humanized antibodies or fully human antibodies, may be used to prolong the half-life of the polypeptide and to prevent the polypeptide being attacked by the host's immune system.
[00209] Frequency of administration may be determined and adjusted over the course of therapy, and is generally, but not necessarily, based on treatment and/or suppression and/or amelioration and/or delay of a disease. Alternatively, sustained continuous release formulations of a polypeptide or a polynucleotide (e.g., RNA or DNA) may be appropriate. Various formulations and devices for achieving sustained release are known in the art. In some embodiments, dosage is daily, every other day, every three days, every four days, every five days, or every six days. In some embodiments, dosing frequency is once every week, every 2 weeks, every 4 weeks, every 5 weeks, every 6 weeks, every 7 weeks, every 8 weeks, every 9 weeks, or every 10 weeks; or once every month, every 2 months, or every 3 months, or longer. The progress of this therapy is easily monitored by conventional techniques and assays.
[00210] The dosing regimen (including the polypeptide or the polynucleotide used) can vary over time. In some embodiments, for an adult subject of normal weight, doses ranging from about 0.01 to 1000 mg/kg may be administered. In some embodiments, the dose is between 1 to 200 mg. The particular dosage regimen, i.e., dose, timing and repetition, will depend on the particular subject and that subject's medical history, as well as the properties of the polypeptide or the polynucleotide (such as the half-life of the polypeptide or the polynucleotide, and other considerations well known in the art).
[00211] For the purpose of the present disclosure, the appropriate dosage of a therapeutic agent as described herein will depend on the specific agent (or compositions thereof) employed, the formulation and route of administration, the type and severity of the disease, whether the polypeptide or the polynucleotide is administered for preventive or therapeutic purposes, previous therapy, the subject's clinical history and response to the antagonist, and the discretion of the attending physician. Typically the clinician will administer a polypeptide or a polynucleotide until a dosage is reached that achieves the desired result.
[00212] Administration of one or more polypeptides or polynucleotides can be continuous or intermittent, depending, for example, upon the recipient's physiological
condition, whether the purpose of the administration is therapeutic or prophylactic, and other factors known to skilled practitioners. The administration of a polypeptide or a
polynucleotide may be essentially continuous over a preselected period of time or may be in a series of spaced dose, e.g., either before, during, or after developing a disease. As used herein, the term "treating" refers to the application or administration of a polypeptide or a polynucleotide or composition including the polypeptide or the polynucleotide to a subject in need thereof. As used herein, "treating" a disease includes preventing disease onset, e.g., preventing HIV infection and/or preventing the onset of AIDS.
[00213] "A subject in need thereof refers to an individual who has a disease, a symptom of the disease, or a predisposition or susceptibility toward the disease, with the purpose to prevent, cure, heal, alleviate, relieve, alter, remedy, ameliorate, improve, or affect the disease, one or more symptoms of the disease, or predisposition toward the disease. In some embodiments, the subject is at risk of becoming infected with HIV. In some embodiments, the subject is infected with HIV. In some embodiments, the subject has AIDS. In some embodiments, the subject is a mammal. In some embodiments, the subject is a non- human primate. In some embodiments, the subject is human. Alleviating a disease includes delaying the development or progression of the disease (i.e., AIDS), or reducing disease severity. Alleviating the disease does not necessarily require curative results.
[00214] As used therein, "delaying" the development of a disease means to defer, hinder, slow, retard, stabilize, and/or postpone progression of the disease. This delay can be of varying lengths of time, depending on the history of the disease and/or individuals being treated. A method that "delays" or alleviates the development of a disease, or delays the onset of the disease, is a method that reduces probability of developing one or more symptoms of the disease in a given time frame and/or reduces extent of the symptoms in a given time frame, when compared to not using the method. Such comparisons are typically based on clinical studies, using a number of subjects sufficient to give a statistically significant result.
[00215] "Development" or "progression" of a disease means initial manifestations and/or ensuing progression of the disease. Development of the disease can be detectable and assessed using standard clinical techniques as well known in the art. However, development also refers to progression that may be undetectable. For purpose of this disclosure, development or progression refers to the biological course of the symptoms. "Development" includes occurrence, recurrence, and onset.
[00216] As used herein "onset" or "occurrence" of a disease includes initial onset
and/or recurrence. Conventional methods, known to those of ordinary skill in the art of medicine, can be used to administer the isolated polypeptide or pharmaceutical composition to the subject, depending upon the type of disease to be treated or the site of the disease. This composition can also be administered via other conventional routes, e.g., administered orally, parenterally, by inhalation spray, topically, rectally, nasally, buccally, vaginally, or via an implanted reservoir.
[00217] The term "parenteral," as used herein, includes subcutaneous, intracutaneous, intravenous, intramuscular, intraarticular, intraarterial, intrasynovial, intrasternal, intrathecal, intralesional, and intracranial injection or infusion techniques. In addition, the compositions described herein can be administered to the subject via injectable depot routes of
administration such as using 1-, 3-, or 6-month depot injectable or biodegradable materials and methods.
Host Cells and Organisms
[00218] Other aspects of the present disclosure provide host cells and organisms for the production and/or isolation of the nucleobase editors, e.g., for in vitro editing. Host cells are genetically engineered to express the nucleobase editors and components of the translation system described herein. In some embodiments, host cells comprise vectors encoding the nucleobase editors and components of the translation system (e.g., transformed, transduced, or transfected), which can be, for example, a cloning vector or an expression vector. The vector can be, for example, in the form of a plasmid, a bacterium, a virus, a naked polynucleotide, or a conjugated polynucleotide. The vectors are introduced into cells and/or microorganisms by standard methods including electroporation, infection by viral vectors, high velocity ballistic penetration by small particles with the nucleic acid either within the matrix of small beads or particles, or on the surface (Klein et ah, Nature 327, 70- 73 (1987), which is incorporated herein by reference). In some embodiments, the host cell is a prokaryotic cell. In some embodiments, the host cell is a eukaryotic cell. In some embodiments, the host cell is a bacterial cell. In some embodiments, the host cell is a yeast cell. In some embodiments, the host cell is a mammalian cell. In some embodiments, the host cell is a human cell. In some embodiments, the host cell is a cultured cell. In some embodiments, the host cell is within a tissue or an organism.
[00219] The engineered host cells can be cultured in conventional nutrient media modified as appropriate for such activities as, for example, screening steps, activating promoters or selecting transformants. These cells can optionally be cultured into transgenic
organisms.
[00220] Several well-known methods of introducing target nucleic acids into bacterial cells are available, any of which can be used in the present disclosure. These include: fusion of the recipient cells with bacterial protoplasts containing the DNA, electroporation, projectile bombardment, and infection with viral vectors (discussed further, below), etc. Bacterial cells can be used to amplify the number of plasmids containing DNA constructs of the present disclosure. The bacteria are grown to log phase and the plasmids within the bacteria can be isolated by a variety of methods known in the art (see, for instance,
Sambrook). In addition, a plethora of kits are commercially available for the purification of plasmids from bacteria, (see, e.g., EasyPrep™, FlexiPrep™, both from Pharmacia Biotech; StrataClean™, from Stratagene; and, QIAprep™ from Qiagen). The isolated and purified plasmids are then further manipulated to produce other plasmids, used to transfect cells or incorporated into related vectors to infect organisms. Typical vectors contain transcription and translation terminators, transcription and translation initiation sequences, and promoters useful for regulation of the expression of the particular target nucleic acid. The vectors optionally comprise generic expression cassettes containing at least one independent terminator sequence, sequences permitting replication of the cassette in eukaryotes, or prokaryotes, or both, (e.g., shuttle vectors) and selection markers for both prokaryotic and eukaryotic systems. Vectors are suitable for replication and integration in prokaryotes, eukaryotes, or preferably both. See, Giliman & Smith, Gene 8:81 (1979); Roberts, et al., Nature, 328:731 (1987); and Schneider, B., et al, Protein Expr. Purifi 6435: 10 (1995)), the entire contents of each of which are incorporated herein by reference.
[00221] Bacteriophages useful for cloning is provided, e.g., by the ATCC, e.g., The
ATCC Catalogue of Bacteria and Bacteriophage (1992) Gherna et al. (eds) published by the ATCC. Additional basic procedures for sequencing, cloning and other aspects of molecular biology and underlying theoretical considerations are also found in Watson et al. (1992) Recombinant DNA Second Edition Scientific American Books, NY, the entire contents of which is incorporated herein by reference.
[00222] Other useful references, e.g., for cell isolation and culture (e.g., for subsequent nucleic acid isolation) include Freshney (1994) Culture of Animal Cells, a Manual of Basic Technique, third edition, Wiley- Liss, New York and the references cited therein; Payne et al. (1992) Plant Cell and Tissue Culture in Liquid Systems John Wiley & Sons, Inc. New York, NY; Gamborg and Phillips (eds) (1995) Plant Cell. Tissue and Organ Culture; Fundamental Methods Springer Lab Manual, Springer- Verlag (Berlin Heidelberg
New York) and Atlas and Parks (eds) The Handbook of Microbiological Media (1993) CRC Press, Boca Raton, FL, the entire contents of each of which are incorporated herein by reference. In addition, essentially any nucleic acid (and virtually any labeled nucleic acid, whether standard or non-standard) can be custom or standard ordered from any of a variety of commercial sources, such as The Midland Certified Reagent Company (mcrc@oligos.com), The Great American Gene Company (www.genco.com), ExpressGen Inc.
(www.expressgen.com), Operon Technologies Inc. (Alameda, CA), and many others.
[00223] Without further elaboration, it is believed that one skilled in the art can, based on the above description, utilize the present disclosure to its fullest extent. The following specific embodiments are, therefore, to be construed as merely illustrative, and not limitative of the remainder of the disclosure in any way whatsoever. All publications cited herein are incorporated by reference for the purposes or subject matter referenced herein.
EXAMPLES
[00224] In order that the compositions and methods described herein may be more fully understood, the following examples are set forth. The synthetic examples described in this application are offered to illustrate the compounds and methods provided herein and are not to be construed in any way as limiting their scope.
Example 1: Guide nucleotide sequence-programmable DNA-binding protein domains, deaminases, and base editors
[00225] Non-limiting examples of suitable guide nucleotide sequence-programmable
DNA-binding protein domains are provided. The disclosure provides Cas9 variants, for example, Cas9 proteins from one or more organisms, which may comprise one or more mutations (e.g., to generate dCas9 or Cas9 nickase). In some embodiments, one or more of the amino acid residues, identified below by an asterisk, of a Cas9 protein may be mutated. In some embodiments, the DIO and/or H840 residues of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the amino acid sequences provided in SEQ ID NOs: 11-260, are mutated. In some embodiments, the DIO residue of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the amino acid sequences provided in SEQ ID NOs: 11-260, is mutated to any amino acid residue, except for D. In some embodiments, the DIO residue of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the amino acid sequences provided in SEQ ID NOs: 11-260, is mutated to an A. In some embodiments, the H840 residue of the amino acid
sequence provided in SEQ ID NO: 1, or a corresponding residue in any of the amino acid sequences provided in SEQ ID NOs: 11-260, is an H. In some embodiments, the H840 residue of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the amino acid sequences provided in SEQ ID NOs: 11-260, is mutated to any amino acid residue, except for H. In some embodiments, the H840 residue of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding mutation in any of the amino acid sequences provided in SEQ ID NOs: 11-260, is mutated to an A. In some embodiments, the D10 residue of the amino acid sequence provided in SEQ ID NO: 1, or a corresponding residue in any of the amino acid sequences provided in SEQ ID NOs: 11-260, is a D.
[00226] A number of Cas9 sequences from various species were aligned to determine whether corresponding homologous amino acid residues of D10 and H840 of SEQ ID NO: 1 or SEQ ID NO: 11 can be identified in other Cas9 proteins, allowing the generation of Cas9 variants with corresponding mutations of the homologous amino acid residues. The alignment was carried out using the NCBI Constraint-based Multiple Alignment Tool (COBALT(accessible at st-va.ncbi. nlm.nih.gov/tools/cobalt), with the following parameters. Alignment parameters: Gap penalties -11,-1; End-Gap penalties -5,-1. CDD Parameters: Use RPS BLAST on; Blast E-value 0.003; Find Conserved columns and Recompute on. Query Clustering Parameters: Use query clusters on; Word Size 4; Max cluster distance 0.8;
Alphabet Regular.
[00227] An exemplary alignment of four Cas9 sequences is provided below. The Cas9 sequences in the alignment are: Sequence 1 (S I): SEQ ID NO: 11 I WP_010922251I gi 499224711 I type II CRISPR RNA-guided endonuclease Cas9 [Streptococcus pyogenes]; Sequence 2 (S2): SEQ ID NO: 12 I WP_039695303 I gi 746743737 I type II CRISPR RNA- guided endonuclease Cas9 [Streptococcus gallolyticus]; Sequence 3 (S3): SEQ ID NO: 13 I WP_045635197 I gi 782887988 I type II CRISPR RNA-guided endonuclease Cas9
[Streptococcus mitis]; Sequence 4 (S4): SEQ ID NO: 14 I 5AXW_A I gi 924443546 I Staphylococcus aureus Cas9. The HNH domain (bold and underlined) and the RuvC domain (boxed) are identified for each of the four sequences. Amino acid residues 10 and 840 in S I and the homologous amino acids in the aligned sequences are identified with an asterisk following the respective amino acid residue.


[00228] The alignment demonstrates that amino acid sequences and amino acid residues that are homologous to a reference Cas9 amino acid sequence or amino acid residue can be identified across Cas9 sequence variants, including, but not limited to Cas9 sequences from different species, by identifying the amino acid sequence or residue that aligns with the reference sequence or the reference residue using alignment programs and algorithms known in the art. This disclosure provides Cas9 variants in which one or more of the amino acid residues identified by an asterisk in SEQ ID NOs: 11-14 (e.g., S I, S2, S3, and S4,
respectively) are mutated as described herein. The residues D10 and H840 in Cas9 of SEQ ID NO: 1 that correspond to the residues identified in SEQ ID NOs: 11-14 by an asterisk are referred to herein as "homologous" or "corresponding" residues. Such homologous residues can be identified by sequence alignment, e.g., as described above, and by identifying the sequence or residue that aligns with the reference sequence or residue. Similarly, mutations in Cas9 sequences that correspond to mutations identified in SEQ ID NO: 1 herein, e.g., mutations of residues 10, and 840 in SEQ ID NO: 1, are referred to herein as "homologous" or "corresponding" mutations. For example, the mutations corresponding to the D10A mutation in SEQ ID NO: 1 or S I (SEQ ID NO: 11) for the four aligned sequences above are Dl 1A for S2, D10A for S3, and D13A for S4; the corresponding mutations for H840A in SEQ ID NO: 1 or S I (SEQ ID NO: 11) are H850A for S2, H842A for S3, and H560A for S4.
[00229] A total of 250 Cas9 sequences (SEQ ID NOs: 11-260) from different species are provided. Amino acid residues homologous to residues 10, and 840 of SEQ ID NO: 1 may be identified in the same manner as outlined above. All of these Cas9 sequences may be used in accordance with the present disclosure.










[00230] Non-limiting examples of suitable deaminase domains are provided.



 RDNGVGLNVMVSEHYQCCRKIFIQSSHNQLNENRWLEKTLKRAEKRRSELSIMIQVKILHTTKSPAV (SEQ ID NO: 289)
RDNGVGLNVMVSEHYQCCRKIFIQSSHNQLNENRWLEKTLKRAEKRRSELSIMIQVKILHTTKSPAV (SEQ ID NO: 289)
Human APOBEC3G D316R_D317R
MKPHFRNTVERMYRDTFSYNFYNRPILSRRNTVWLCYEVKTKGPSRPPLDAKIFRGQVYSELKYHPEMRFF
HWFSKWRKLHRDQEYEVTWYISWSPCTKCTRDMATFLAEDPKVTLTIFVARLYYFWDPDYQEALRSLCQ
KRDGPRATMKIMNYDEFQHCWSKFVYSQRELFEPWNNLPKYYILLHIMLGEILRHSMDPPTFTFNFNNEPW
VRGRHETYLCYEVERMHNDTWVLLNQRRGFLCNQAPHKHGFLEGRHAELCFLDVIPFWKLDLDQDYRVT
CFTSWSPCFSCAQEMAKFISKNKHVSLCIFTARIYRRQGRCQEGLRTLAEAGAKISIMTYSEFKHCWDTFVD
HQGCPFQPWDGLDEHSQDLSGRLRAILQNQEN (SEQ ID NO: 290)
Human APOBEC3G chain A
MDPPTFTFNFNNEPWVRGRHETYLCYEVERMHNDTWVLLNQRRGFLCNQAPHKHGFLEGRHAELCFLDV IPFWKLDLDQDYRVTCFTSWSPCFSCAQEMAKFISKNKHVSLCIFTARIYDDQGRCQEGLRTLAEAGAKISI MTYSEFKHCWDTFVDHQGCPFQPWDGLDEHSQDLSGRLRAILQ (SEQ ID NO: 291)
Human APOBEC3G chain A D120R_D121R
MDPPTFTFNFNNEPWVRGRHETYLCYEVERMHNDTWVLLNQRRGFLCNQAPHKHGFLEGRHAELCFLDV IPFWKLDLDQDYRVTCFTSWSPCFSCAQEMAKFISKNKHVSLCIFTARIYRRQGRCQEGLRTLAEAGAKISI MTYSEFKHCWDTFVDHQGCPFQPWDGLDEHSQDLSGRLRAILQ (SEQ ID NO: 292)
[00231] Non-limiting examples of fusion proteins/nucleobase editors are provided.
His6-rAPOBECl-XTEN-dCas9 for Escherichia coli expression (SEQ ID NO: 293)
MGSSHHHHHHMSSETGPVAVDPTLRRRIEPHEFEVFFDPRELRKETCLLYEINWGGRHSIWRHTSONTNKH
VEVNFIEKFTTERYFCPNTRCSITWFLSWSPCGECSRAITEFLSRYPHVTLFIYIARLYHHADPRNRQGLRDLI
SSGVTIOIMTEQESGYCWRNFVNYSPSNEAHWPRYPHLWVRLYVLELYCIILGLPPCLNILRRKQPQLTFFTI
ALQSCHYQRLPPHILWATGLKSGSETPGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLG
NTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVE
EDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSD
VDKLFIOLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFK
SNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDOYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRY
DEHHQDLTLLKALVROOLPEKYKEIFFDQSKNGYAGYIDGGASOEEFYKFIKPILEKMDGTEELLVKLNRE
DLLRKORTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKS
EETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFL
SGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKllKDKDFLDNEEN
EDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKOSGKTILDFLK
SDGFANRNFMOLIHDDSLTFKEDIOKAOVSGOGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRH
KPENIVIEMARENOTTOKGOKNSRERMKRIEEGIKELGSOILKEHPVENTOLONEKLYLYYLQNGRDMYVD
QELDINRLSDYDVDAIVPOSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWROLLNAKLITQR
KFDNLTKAERGGLSELDKAGFIKRQLVETROITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFR
KDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYF
FYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPOVNIVKKTEVQTGGFSKESI
LPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDF
LEAKGYKEVKKDLllKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDN
EQKOLFVEOHKHYLDEllEOISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENllHLFTLTNLGAPAAFK
YFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSOLGGDSGGSPKKKRKV
rAPOBECl-XTEN-dCas9-NLS for Mammalian expression (SEQ ID NO: 294)
MSSETGPVAVDPTLRRRIEPHEFEVFFDPRELRKETCLLYEINWGGRHSIWRHTSQNTNKHVEVNFIEKFTT
ERYFCPNTRCSITWFLSWSPCGECSRAITEFLSRYPHVTLFIYIARLYHHADPRNRQGLRDLISSGVTIQIMTE
QESGYCWRNFVNYSPSNEAHWPRYPHLWVRLYVLELYC11LGLPPCLNILRRKQPQLTFFTIALQSCHYQRL
PPHILWATGLKSGSETPGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKN
LIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIF
GNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQT
YNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKL
QLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLK
ALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDN
GSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEV
VDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDL
LFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLK11KDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFM
QLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARE
NQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDY
DVDAIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERG
GLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREI
NNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKT
EITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIA
RKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVK
KDL11KLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQH
KHYLDE11EQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAEN11HLFTLTNLGAPAAFKYFDTTIDRKRY TSTKEVLDATLIHQSITGLYETRIDLSQLGGDSGGSPKKKRKV hAPOBECl-XTEN-dCas9-NLS for Mammalian expression (SEQ ID NO: 295)
MTSEKGPSTGDPTLRRRIEPWEFDVFYDPRELRKEACLLYEIKWGMSRKIWRSSGKNTTNHVEVNFIKKFTS
ERDFHPSMSCSITWFLSWSPCWECSQAIREFLSRHPGVTLVIYVARLFWHMDQQNRQGLRDLVNSGVTIQI
MRASEYYHCWRNFVNYPPGDEAHWPQYPPLWMMLYALELHCIILSLPPCLKISRRWQNHLTFFRLHLQNC
HYQTIPPHILLATGLIHPSVAWRSGSETPGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVL
GNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLV
EEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNS
DVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNF
KSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKR
YDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNR
EDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRK
SEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAF
LSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEE
NEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFL
KSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGR
HKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYV
DQELDINRLSDYDVDAIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQ
RKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDF
RKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAK
YFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSK
ESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPI
DFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPE
DNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAA
FKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDSGGSPKKKRKV rAPOBECl-XTEN-dCas9-UGI-NLS (SEQ ID NO: 296)
MSSETGPVAVDPTLRRRIEPHEFEVFFDPRELRKETCLLYEINWGGRHSIWRHTSQNTNKHVEVNFIEKFTT
ERYFCPNTRCSITWFLSWSPCGECSRAITEFLSRYPHVTLFIYIARLYHHADPRNRQGLRDLISSGVTIQIMTE
QESGYCWRNFVNYSPSNEAHWPRYPHLWVRLYVLELYC11LGLPPCLNILRRKQPQLTFFTIALQSCHYQRL
PPHILWATGLKSGSETPGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKN
LIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIF
GNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQT
YNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKL
QLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLK
ALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDN
GSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEV
VDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDL
LFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLK11KDKDFLDNEENEDILEDIVLTLT
LFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFM
QLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARE
NQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDY
DVDAIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERG
GLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREI
NNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKT
EITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIA
RKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVK
KDL11KLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQH
KHYLDE11EQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAEN11HLFTLTNLGAPAAFKYFDTTIDRKRY
TSTKEVLDATLIHQSITGLYETRIDLSQLGGDSGGSTNLSD11EKETGKQLVIQESILMLPEEVEEVIGNKPESD
ILVHTAYDESTDENVMLLTSDAPEYKPWALVIQDSNGENKIKMLSGGSPKKKRKV rAPOBECl-XTEN-Cas9 nickase-UGI-NLS (BE3, SEQ ID NO: 297)
MSSETGPVAVDPTLRRRIEPHEFEVFFDPRELRKETCLLYEINWGGRHSIWRHTSQNTNKHVEVNFIEKFTT
ERYFCPNTRCSITWFLSWSPCGECSRAITEFLSRYPHVTLFIYIARLYHHADPRNRQGLRDLISSGVTIQIMTE
QESGYCWRNFVNYSPSNEAHWPRYPHLWVRLYVLELYC11LGLPPCLNILRRKQPQLTFFTIALQSCHYQRL
PPHILWATGLKSGSETPGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKN
LIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIF
GNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQT
YNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKL
QLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLK
ALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDN
GSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEV
VDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDL
LFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLK11KDKDFLDNEENEDILEDIVLT1TL
FEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQ
LIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMAREN
QTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYD
VDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGG
LSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREIN
NYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTE
ITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIAR
KKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKK DL11KLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHK HYLDE11EQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAEN11HLFTLTNLGAPAAFKYFDTTIDRKRYT STKEVLDATLIHQSITGLYETRIDLSQLGGDSGGSTNLSD11EKETGKQLVIQESILMLPEEVEEVIGNKPESDI LVHTAYDESTDENVMLLTSDAPEYKPWALVIQDSNGENKIKMLSGGSPKKKRKV pmCDAl-XTEN-dCas9-UGI (bacteria) (SEQ ID NO: 298)
MTDAEYVRIHEKLDIYTFKKQFFNNKKSVSHRCYVLFELKRRGERRACFWGYAVNKPQSGTERGIHAEIFSI
RKVEEYLRDNPGQFTINWYSSWSPCADCAEKILEWYNQELRGNGHTLKIWACKLYYEKNARNQIGLWNL
RDNGVGLNVMVSEHYQCCRKIFIQSSHNQLNENRWLEKTLKRAEKRRSELSIMIQVKILHTTKSPAVSGSET
PGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEAT
RLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPT
IYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGV
DAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNL
LAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEI
FFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAIL
RRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERM
TNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLK
EDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTY
AHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQK
AQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRER
MKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDAIVPQSFLKDDSI
DNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQL
VETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAV
VGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIET
NGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFD
SPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELEN
GRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKR
VILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSI
TGLYETRIDLSQLGGDSGGSMTNLSDIIEKETGKQLVIQESILMLPEEVEEVIGNKPESDILVHTAYDESTDEN
VMLLTSDAPEYKPWALVIQDSNGENKIKML pmCDAl-XTEN-nCas9-UGI-NLS (mammalian construct) (SEQ ID NO: 299):
MTDAEYVRIHEKLDIYTFKKQFFNNKKSVSHRCYVLFELKRRGERRACFWGYAVNKPQSGTERGIHAEIFSI RKVEEYLRDNPGQFTINWYSSWSPCADCAEKILEWYNQELRGNGHTLKIWACKLYYEKNARNQIGLWNL RDNGVGLNVMVSEHYQCCRKIFIQSSHNQLNENRWLEKTLKRAEKRRSELSIMIQVKILHTTKSPAVSGSET PGTSESATPESDKKYSIGLAIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEAT
RLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPT
IYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGV
DAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNL
LAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEI
FFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAIL
RRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERM
TNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLK
EDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTY
AHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQK
AQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRER
MKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSI
DNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQL
VETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAV
VGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIET
NGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFD
SPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELEN
GRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKR
VILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSI
TGLYETRIDLSQLGGDSGGSTNLSDIIEKETGKQLVIQESILMLPEEVEEVIGNKPESDILVHTAYDESTDENV
MLLTSDAPEYKPWALVIQDSNGENKIKMLSGGSPKKKRKV huAPOBEC3G-XTEN-dCas9-UGI (bacteria) (SEQ ID NO: 300)
MDPPTFTFNFNNEPWVRGRHETYLCYEVERMHNDTWVLLNQRRGFLCNQAPHKHGFLEGRHAELCFLDV
IPFWKLDLDQDYRVTCFTSWSPCFSCAQEMAKFISKNKHVSLCIFTARIYDDQGRCQEGLRTLAEAGAKISI
MTYSEFKHCWDTFVDHQGCPFQPWDGLDEHSQDLSGRLRAILQSGSETPGTSESATPESDKKYSIGLAIGTN
SVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIF
SNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLAL
AHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPG
EKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILL
SDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYK
FIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIP
YYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFT
VYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNAS
LGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGR
LSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIK
KGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQ
LQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDAIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEV
VKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDE
NDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKV
YDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVL
SMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKL
KSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPS
KYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPI
REQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDSGGSMTN
LSDIIEKETGKQLVIQESILMLPEEVEEVIGNKPESDILVHTAYDESTDENVMLLTSDAPEYKPWALVIQDSN
GENKIKML huAPOBEC3G-XTEN-nCas9-UGI-NLS (mammalian construct) (SEQ ID NO: 301)
MDPPTFTFNFNNEPWVRGRHETYLCYEVERMHNDTWVLLNQRRGFLCNQAPHKHGFLEGRHAELCFLDV
IPFWKLDLDQDYRVTCFTSWSPCFSCAQEMAKFISKNKHVSLCIFTARIYDDQGRCQEGLRTLAEAGAKISI
MTYSEFKHCWDTFVDHQGCPFQPWDGLDEHSQDLSGRLRAILQSGSETPGTSESATPESDKKYSIGLAIGTN
SVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIF
SNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLAL
AHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPG
EKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILL
SDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYK
FIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIP
YYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFT
VYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNAS
LGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGR
LSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIK
KGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQ
LQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEV
VKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDE
NDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKV
YDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVL
SMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKL
KSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPS
KYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPI
REQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDSGGSTNLS
DIIEKETGKQLVIQESILMLPEEVEEVIGNKPESDILVHTAYDESTDENVMLLTSDAPEYKPWALVIQDSNGE
NKIKMLSGGSPKKKRKV huAPOBEC3G (D316R_D317R)-XTEN-nCas9-UGI-NLS (mammalian construct) (SEQ ID NO: 302)
MDPPTFTFNFNNEPWVRGRHETYLCYEVERMHNDTWVLLNQRRGFLCNQAPHKHGFLEGRHAELCFLDV
IPFWKLDLDQDYRVTCFTSWSPCFSCAQEMAKFISKNKHVSLCIFTARIYRRQGRCQEGLRTLAEAGAKISI
MTYSEFKHCWDTFVDHQGCPFQPWDGLDEHSQDLSGRLRAILQSGSETPGTSESATPESDKKYSIGLAIGTN
SVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIF
SNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLAL
AHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPG
EKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILL
SDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYK
FIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIP
YYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFT
VYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNAS
LGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGR
LSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIK
KGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQ
LQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEV
VKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDE
NDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKV
YDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVL
SMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKL
KSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPS
KYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPI
REQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDSGGSTNLS
DIIEKETGKQLVIQESILMLPEEVEEVIGNKPESDILVHTAYDESTDENVMLLTSDAPEYKPWALVIQDSNGE
NKIKMLSGGSPKKKRKV
Example 2: Genome/base-editing methods for modifying the CCR5 receptor gene to protect against HIV infection
[00232] Disclosed herein are new ways for introducing novel engineered variants, as well as naturally-occurring allelic variants, of the co-receptor C-C Chemokine Receptor 5 (CCR5) that prevent or hinder cellular entry of the Human Immunodeficiency Virus (HIV). These methods include CRISPR-Cas9-based tools programmed by guide RNAs requiring either: (i) "base-editors" that catalyze chemical reactions on nucleobases {e.g., cytidine deaminase-Cas9 fusion, e.g. BE3 1 ); (ii) an engineered nuclease with DNA cutting activity (e.g., WT Cas9, 2 Cas9 nickases3 or Fokl-nuclease-dCas9 fusions4). The variants selected (Figure 1, Tables 1-5) include residues that directly alter the affinity for the HIV coat protein and/or destabilize the
CCR5 protein folding, which mimics the potentially curative effects of the CCR5A32 variant.5 Using a similar strategy, the intron-exon splicing junction adjacent to the open-reading frame of CCR5 can be altered to prevent the maturation and/or destabilize the mRNA transcript (Figures 2A to 2C, Table 2).
[00233] Subsequently, other natural protective variants may be identified in human populations that can be replicated in the same manner (Figure 3, Tables 6 and 7). Moreover, new protective variants of CCR5 (Tables 8-10), and also CCR2,6 could be identified by treating cells in vitro with guide-RNA libraries designed for all possible PAMs in these gene, coupled with FACS sorting using reporters/labeling methods and DNA-deep sequencing, to find the guide- RNAs that programmed base-editing reactions that lower CCR5 protein expression, prevent gpl20 binding, and/or hinder HIV entry into the cell. For example, engineered alterations to destabilize CCR5 may follow a simple design of switching hydrophobic to polar residues on the transmembrane helices (Figure 1). The precisely-targeted methods for CCR5 modifications proposed herein are complementary to previous methods that create random indels in the CCR5 genomic site using engineered nucleases such as CRISPR/Cas9, TALEN, or zinc-finger nucleases in hematopoietic cells ex vivo. Moreover, "base-editors" such as BE3 may have a more favorable safety profile, due to the relatively low impact that off-target cytosine deamination has on genomic stability, including oncogene activation or tumor suppressor inactivation9.
Example 3: Exemplary C to T editing demonstrating modification of the CCR5 receptor gene to generate Q186X and Q188X stop codons
[00234] C to T editing of CCR5 was performed in HEK293 cells using KKH-SaBE3 and guide-RNA Q186X-e [spacer sequence TACAGTCAGTATCAATTCTGG (SEQ ID NO: 735); PAM sequence: AAGAAT (SEQ ID NO: 736)]. The results from these experiments are shown in Figure 5, panels A-C. The editing was calculated from total reads (MiSeq). Figure 5, panel A demonstrates that significant editing was observed at position C7 and C13, both of which generate premature stop codons in tandem (Q186X and Q188X, see inset graphic of Figure 5, panel A). The PAM sequence is shown as underlined and the last nucleotide of the protospacer is separated with a line. Raw data used for base-calling and calculating base-editing for KKH- BE3 and Q186X-e treated HEK293 cells is shown in Figure 5, panel B. The indel percentage
was 1.97%. Figure 5, panel C shows raw data collected for untreated control cells.
[00235] Table 1. Introduction of HIV-protective naturally-occurring allelic variants of
CCR5 and CCR2 using genome/base-editing with APOBECl-Cas9 tools (e.g. BE31).
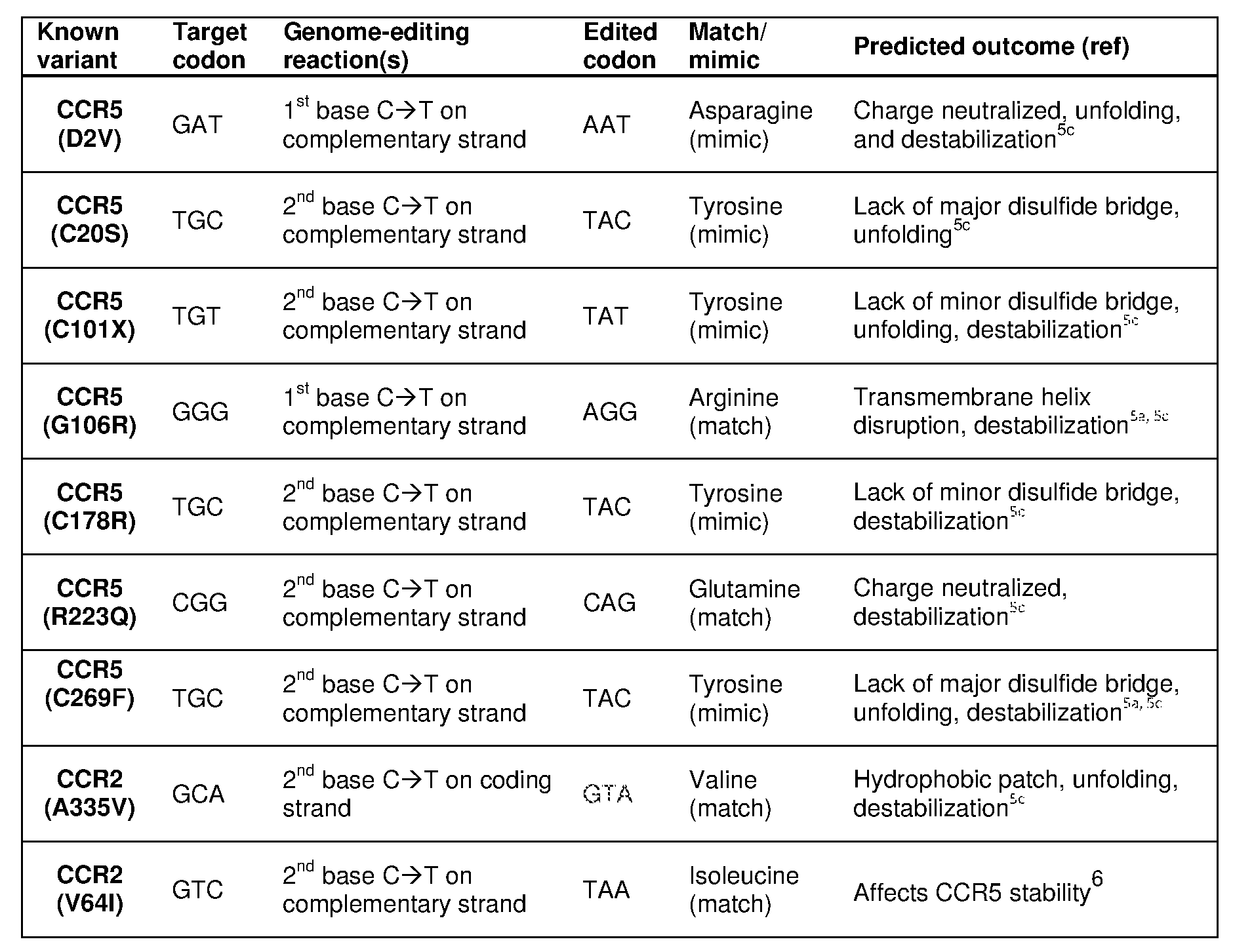
[00236] Table 2. Examples of genome-editing reactions to alter intron-exon junctions and the START site and produce non-functional CCR5 protein, mimicking the HIV protective effect of the CCR5-A32 allele.

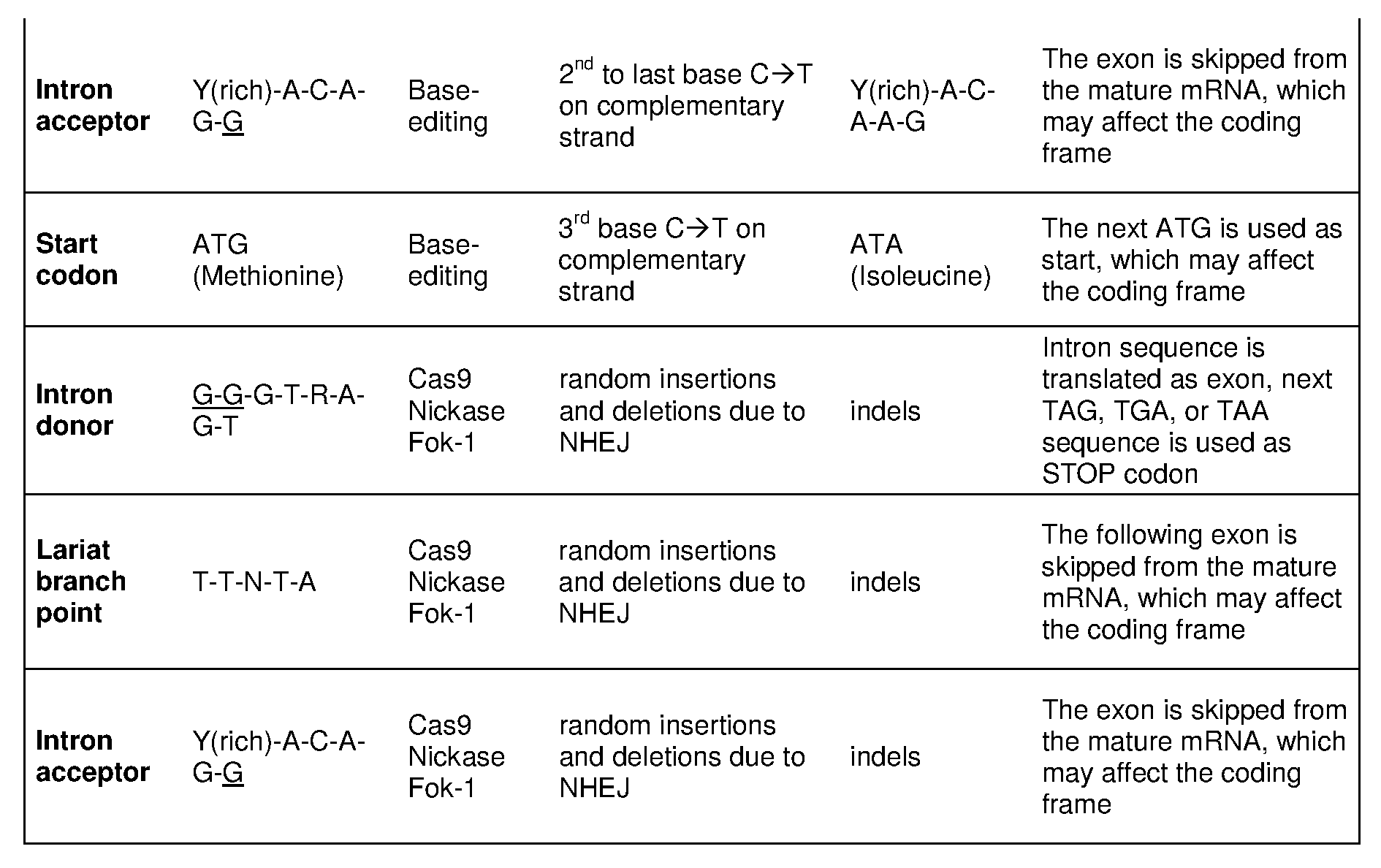
[00237] Table 3. Guide-RNAs designed for introducing naturally-occurring HIV-protective variants of genome/base editing of
CCR5 using base-editor BE3 or WT Cas9.
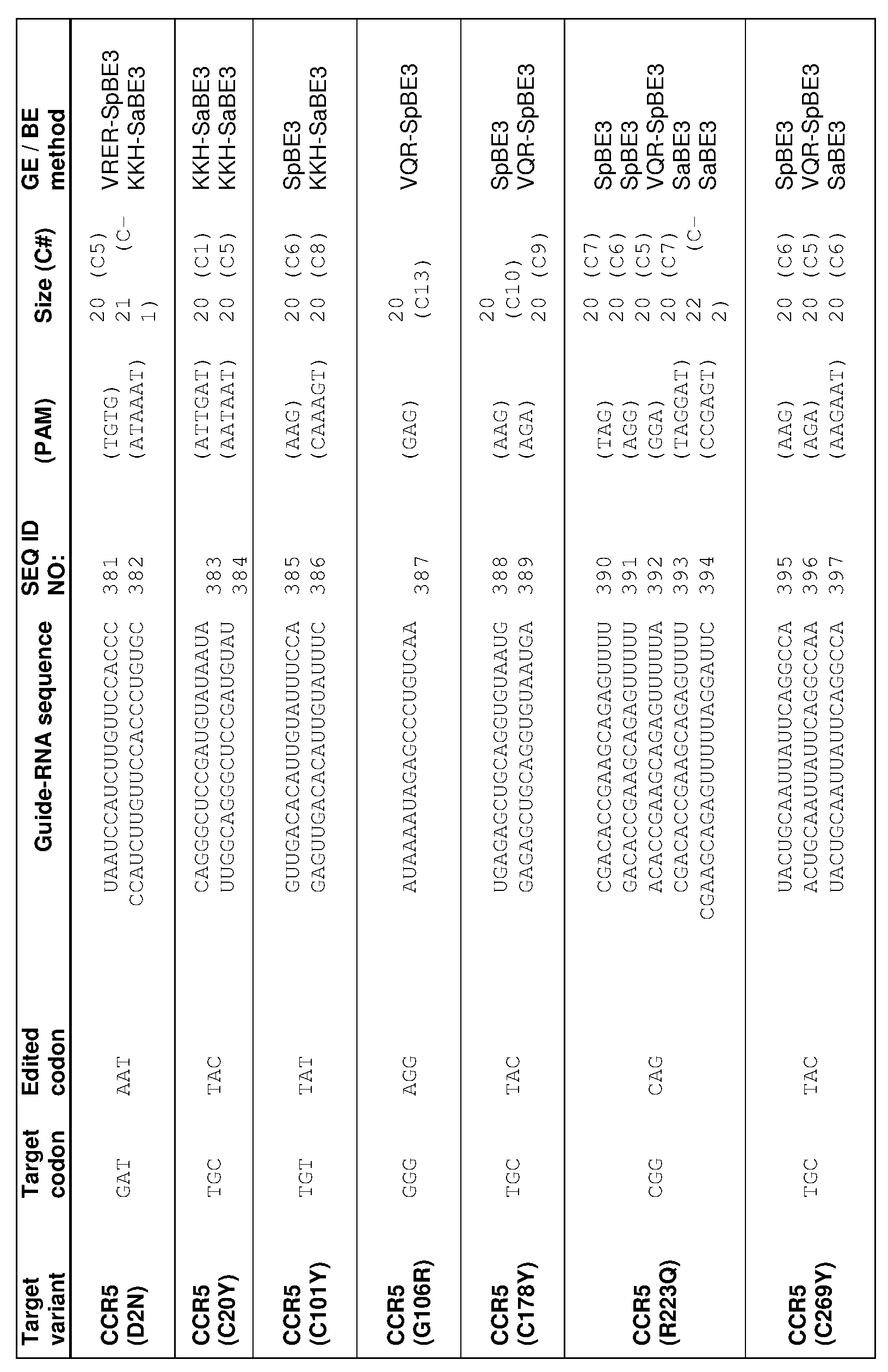

[00238] Table 4. Guide-RNAs designed for engineering new HIV-protective variants of genome/base editing of CCR5 using base-editor BE3.



[00239] Table 5. Guide-RNAs designed for engineering new HIV-protective variants of genome/base editing of CCR5 using base-editor BE3.
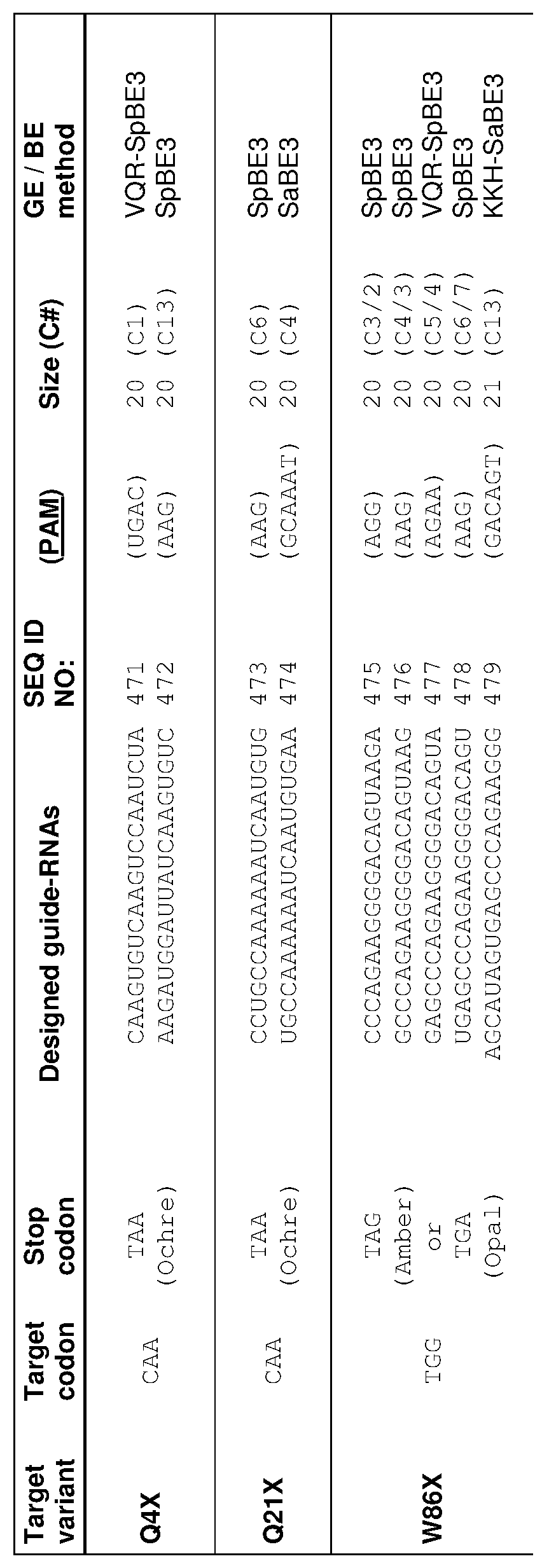
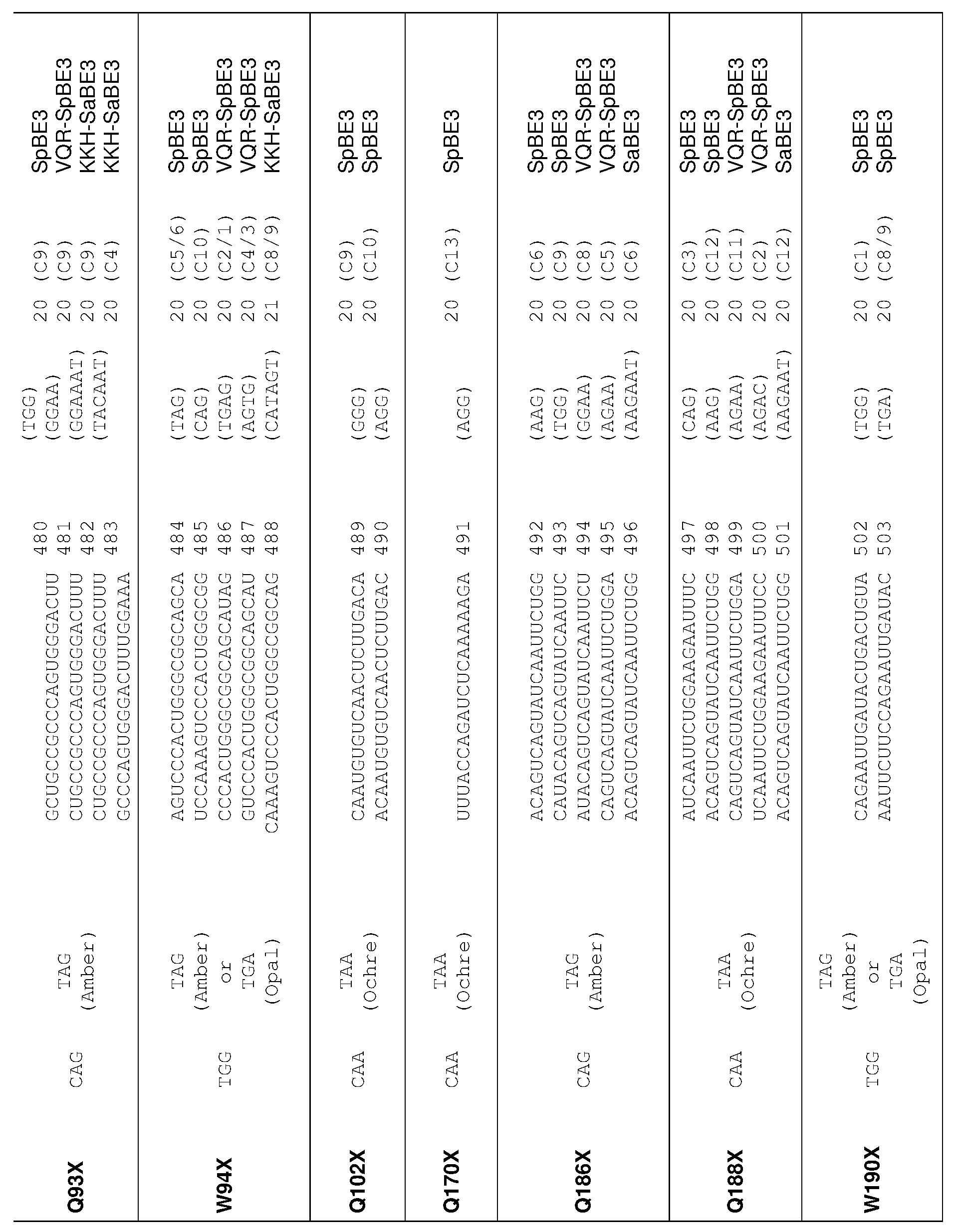
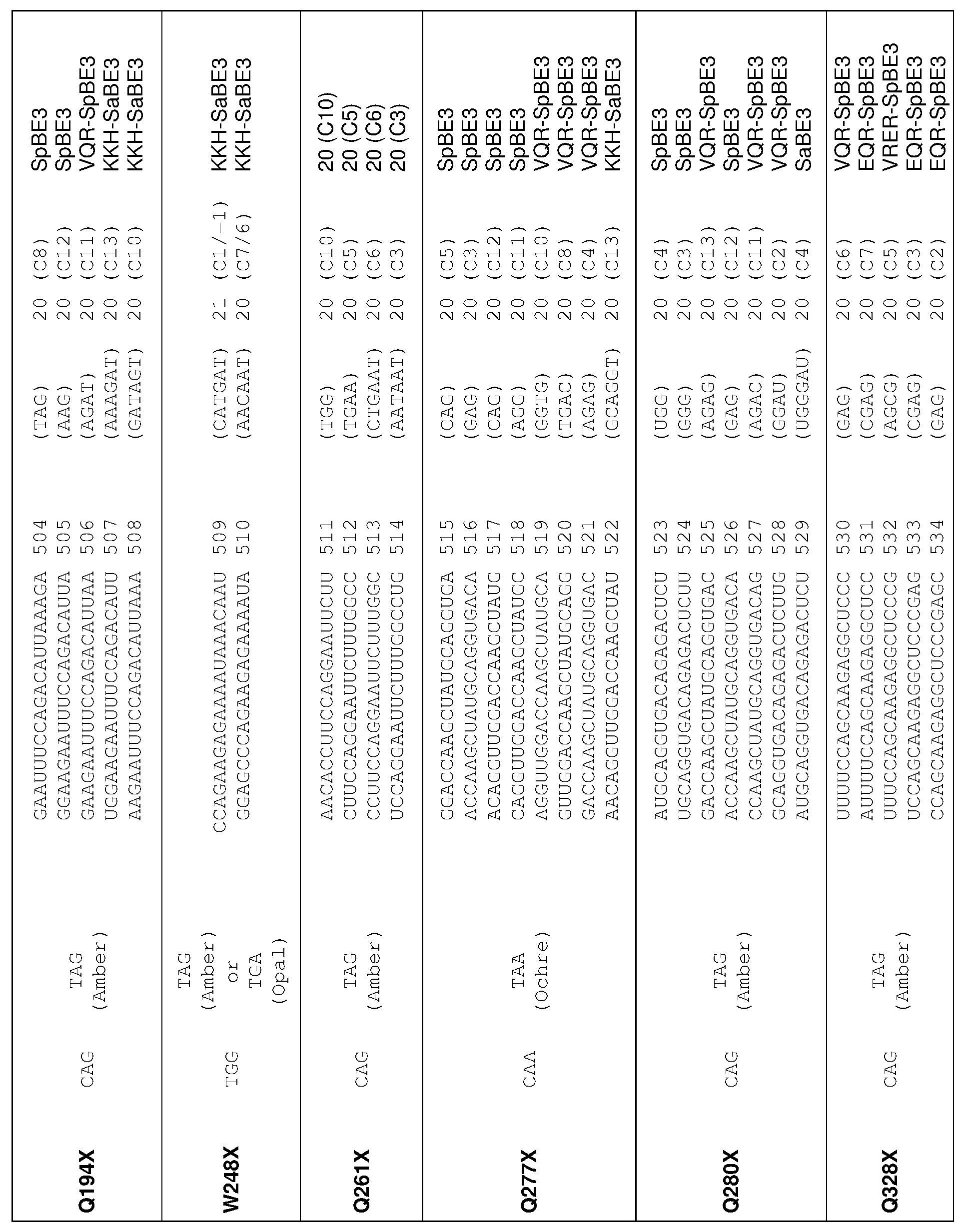
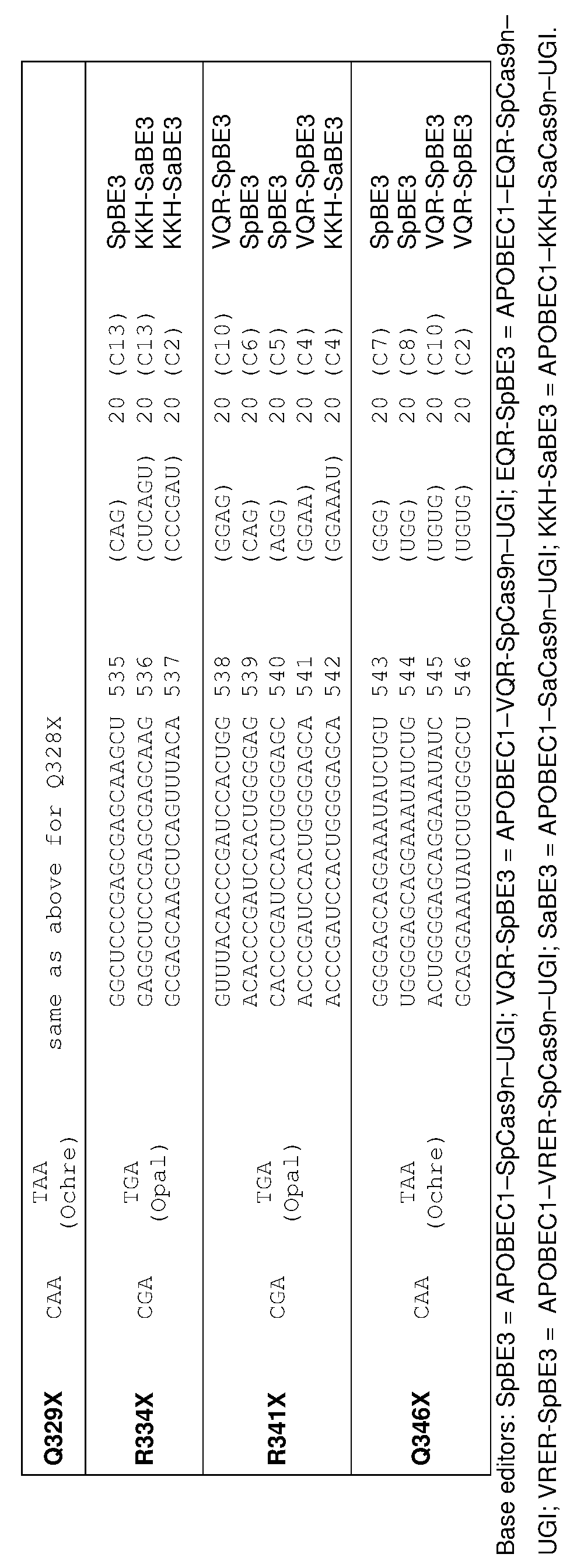
[00240] Table 6. Examples of genome-editing reactions to introduce STOP codons to destabilize or prevent the translation of full-length functional CCR5 protein (Figure 3), mimicking the HIV protective effect of the CCR5-A32 allele.
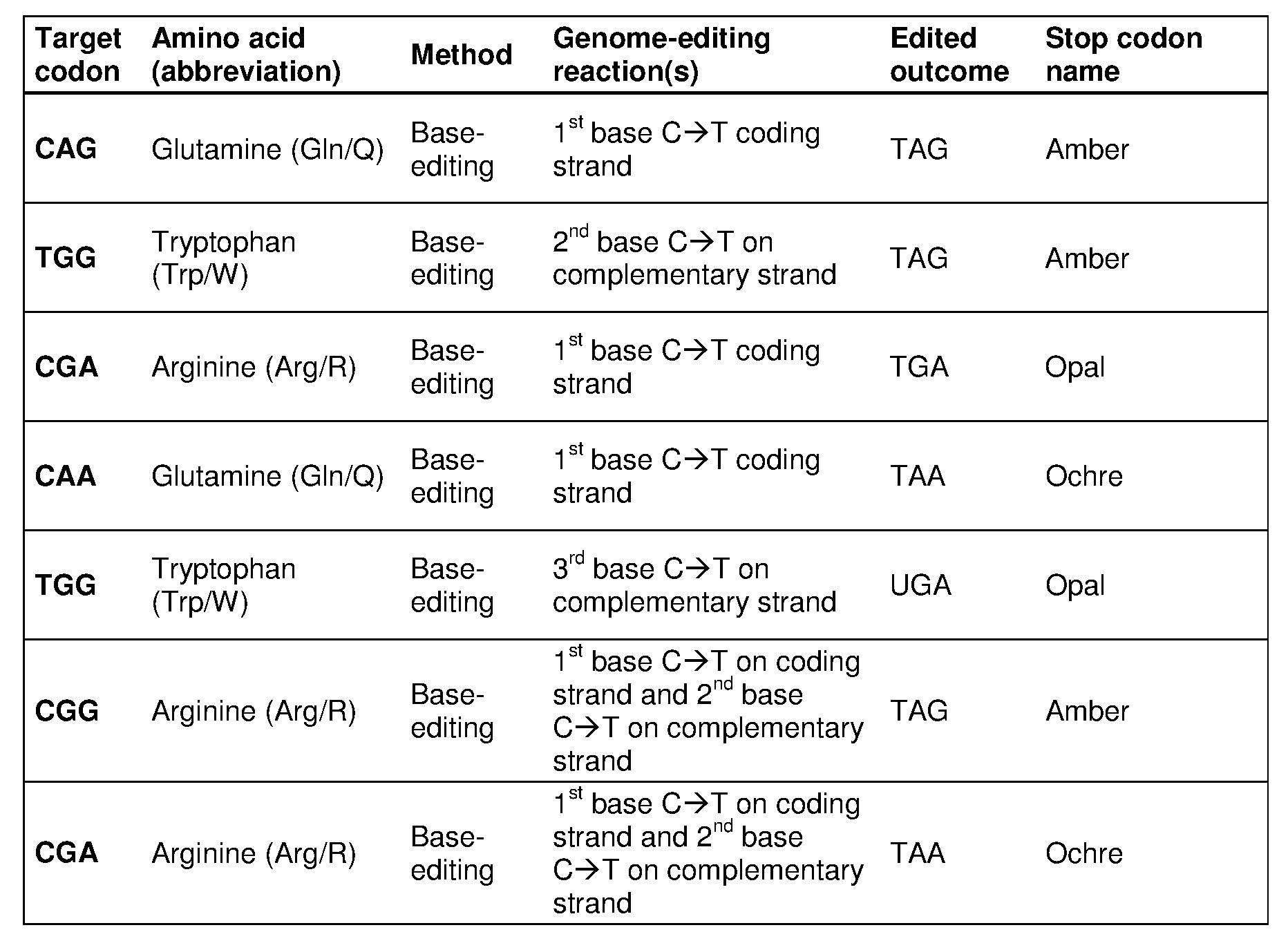
[00241] Table 7. Examples of base-editing reactions to alter amino acid codons in order to produce novel CCR5 variants (Figure 3).
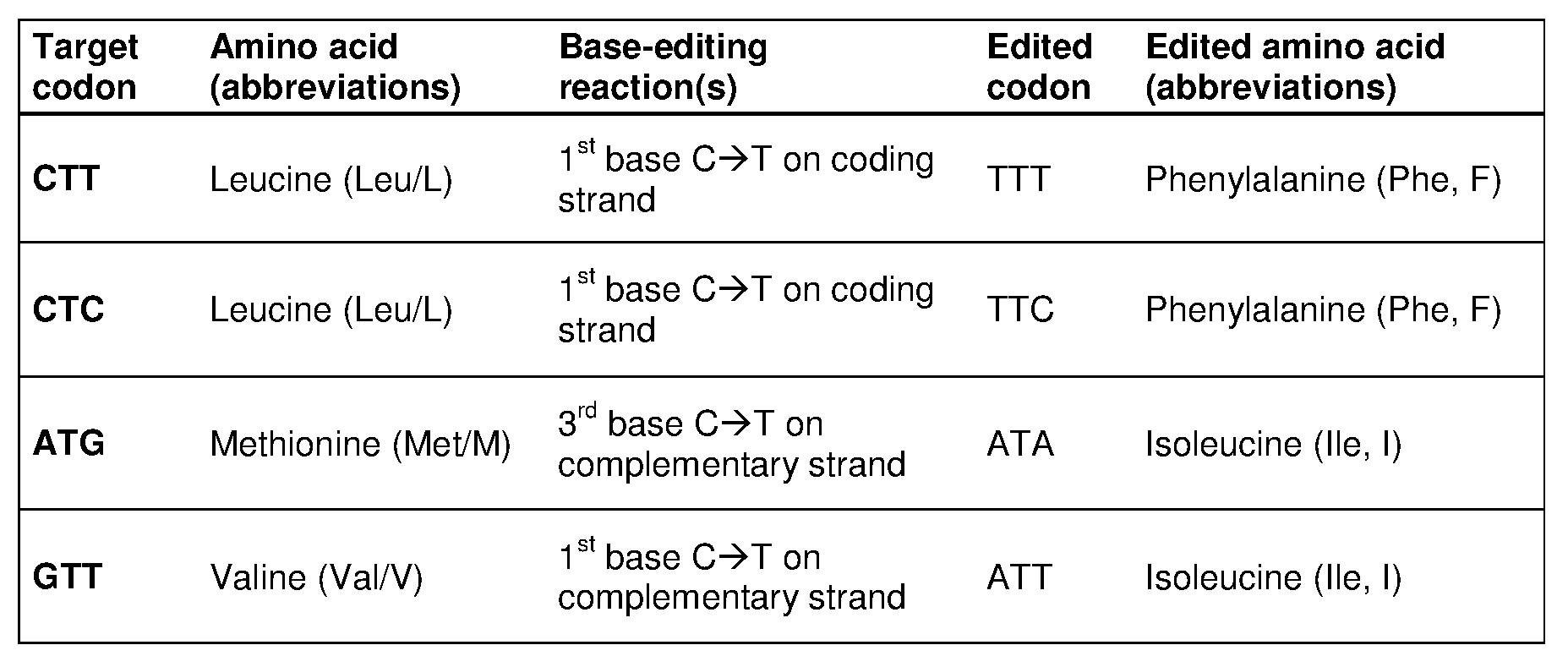
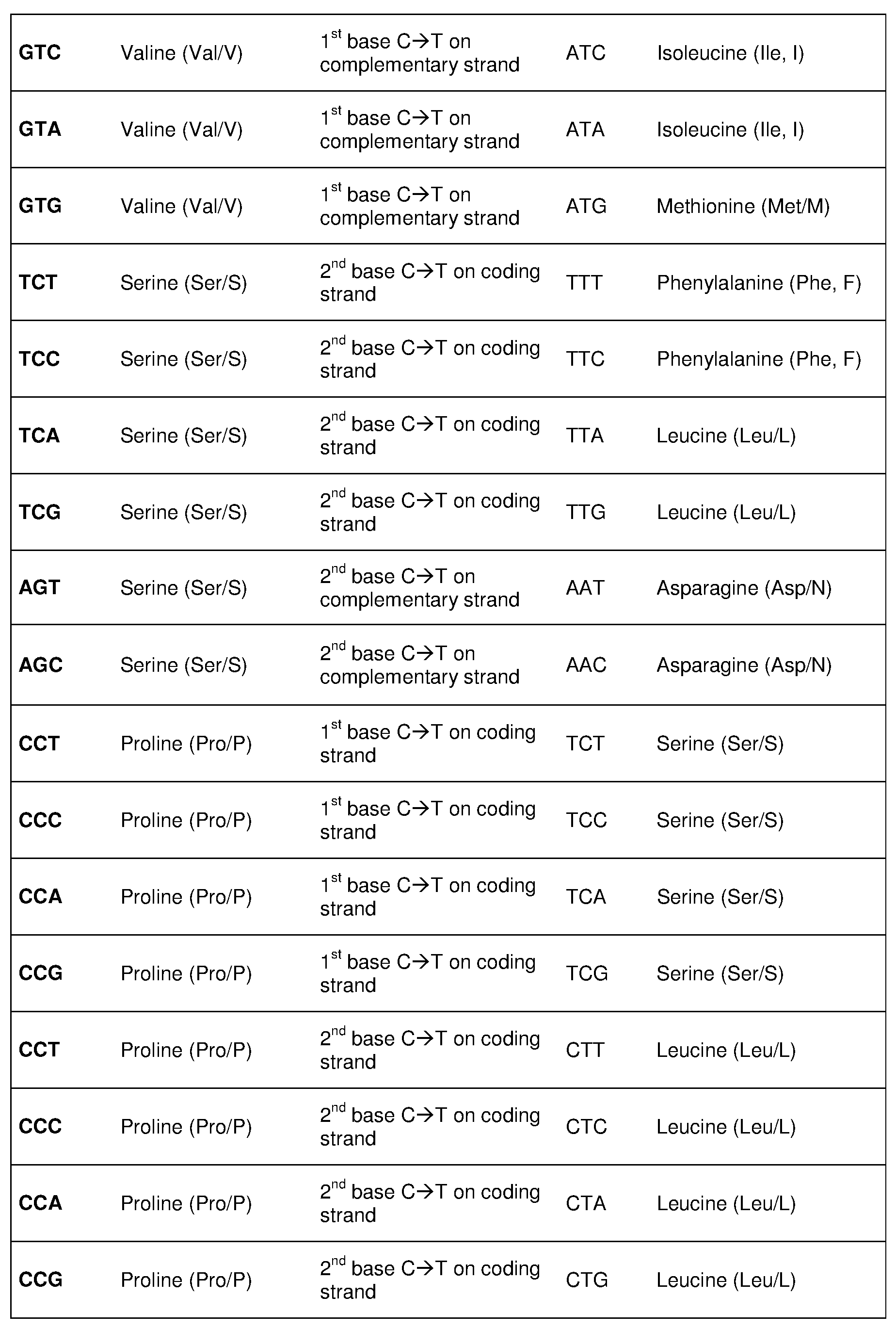

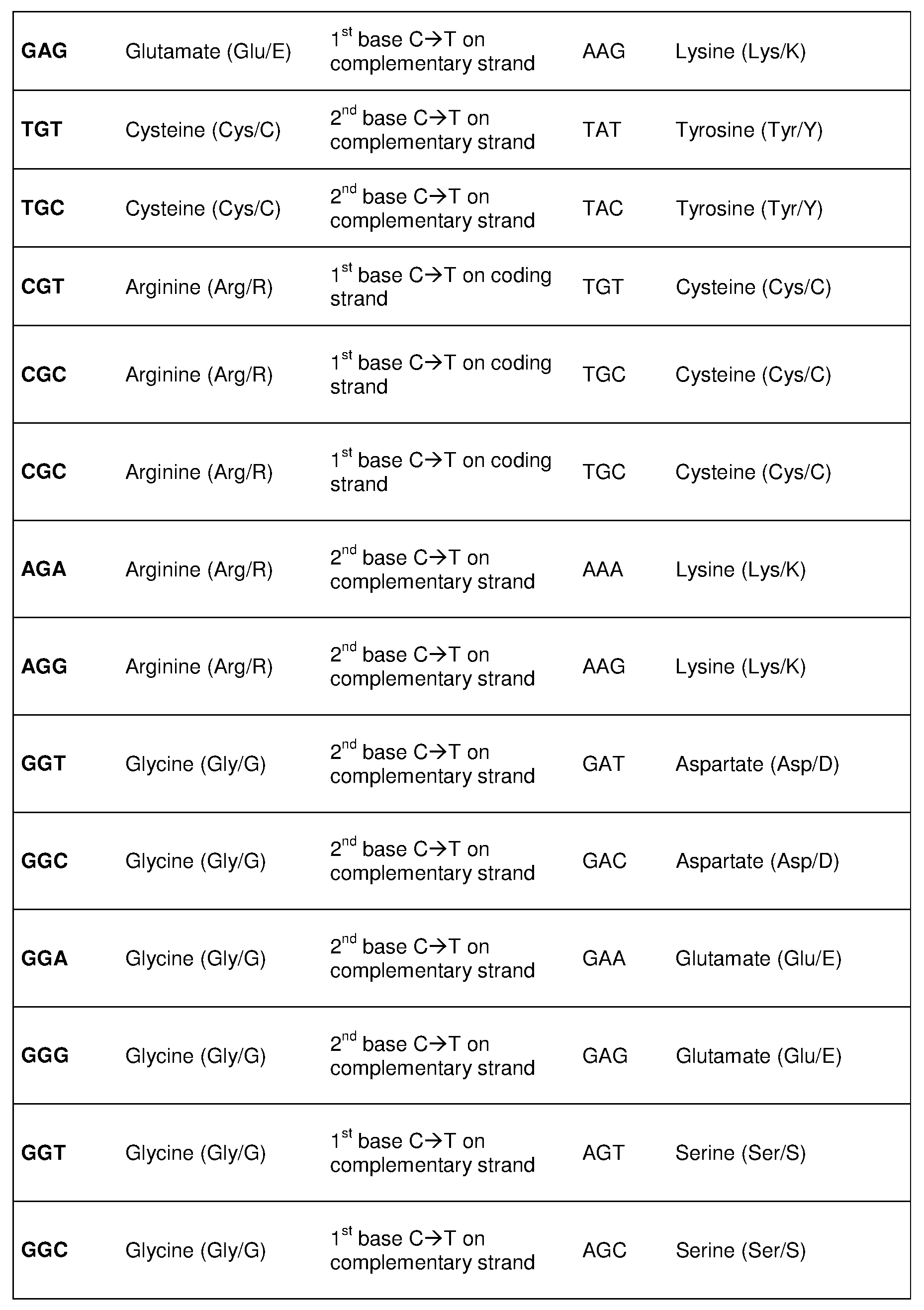

[00242] Table 8. Examples of specific guide RNA sequences used for making variants. The sequences, from top to bottom, correspond to SEQ ID NOs: 547-636.
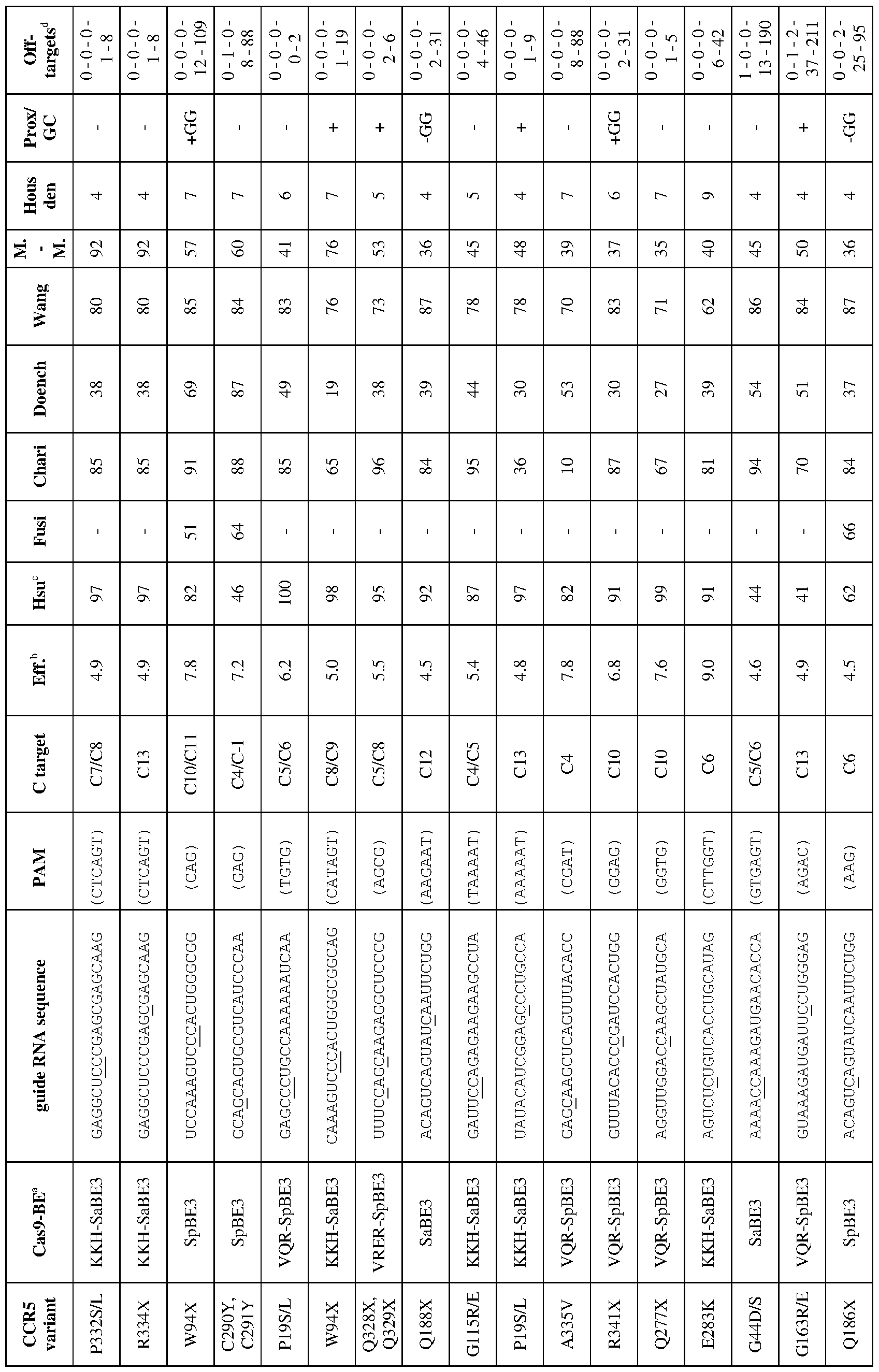
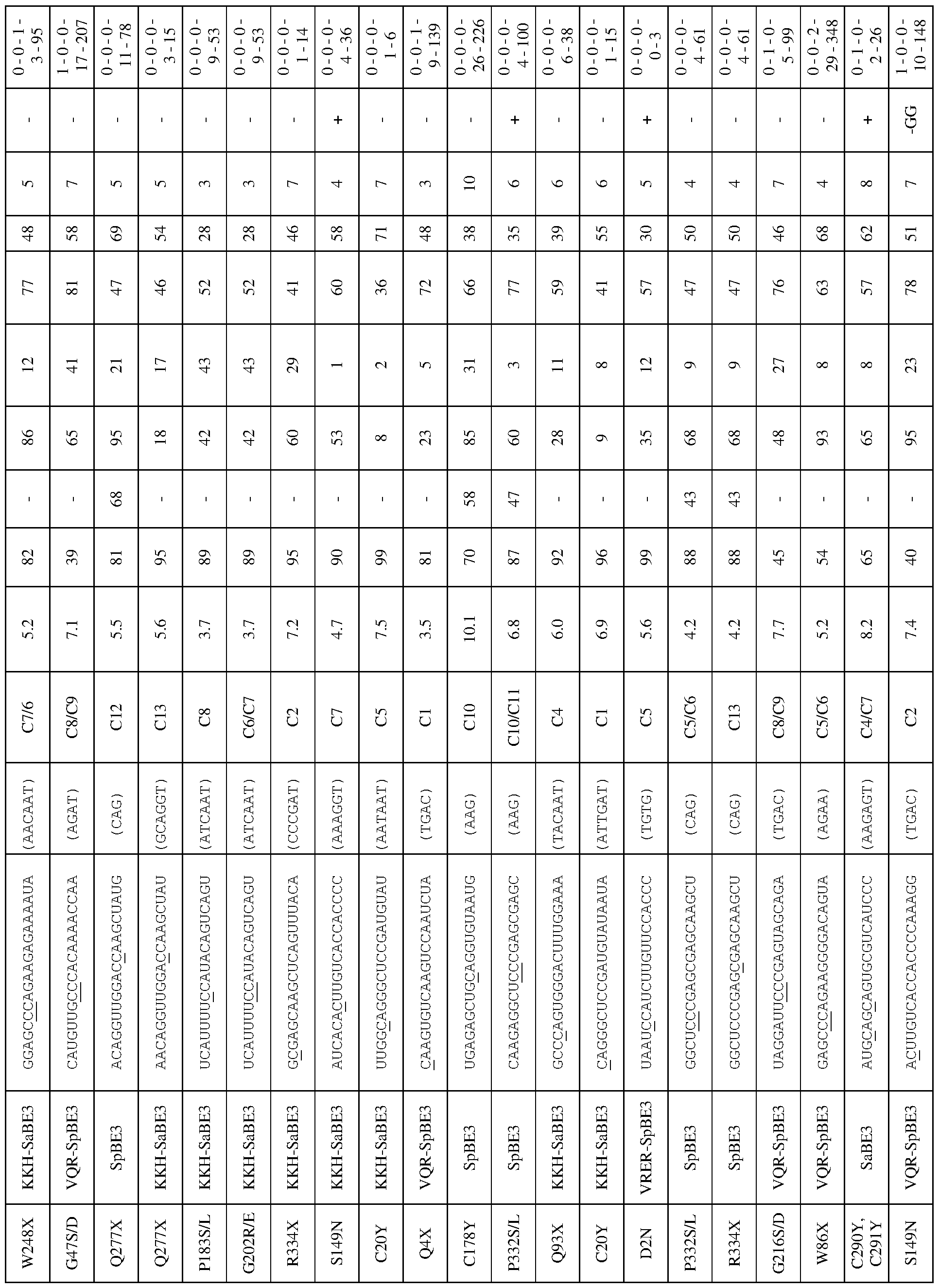
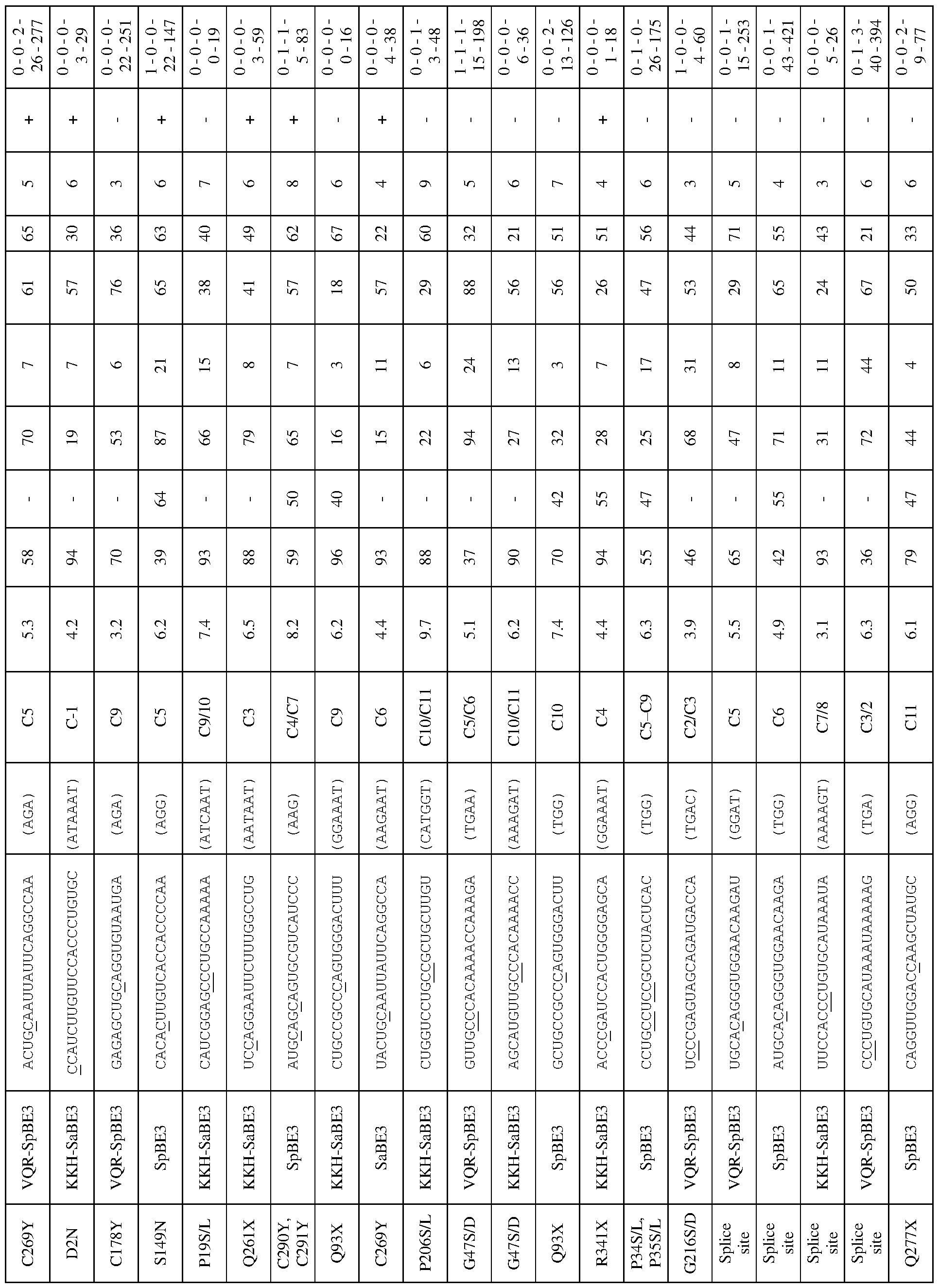
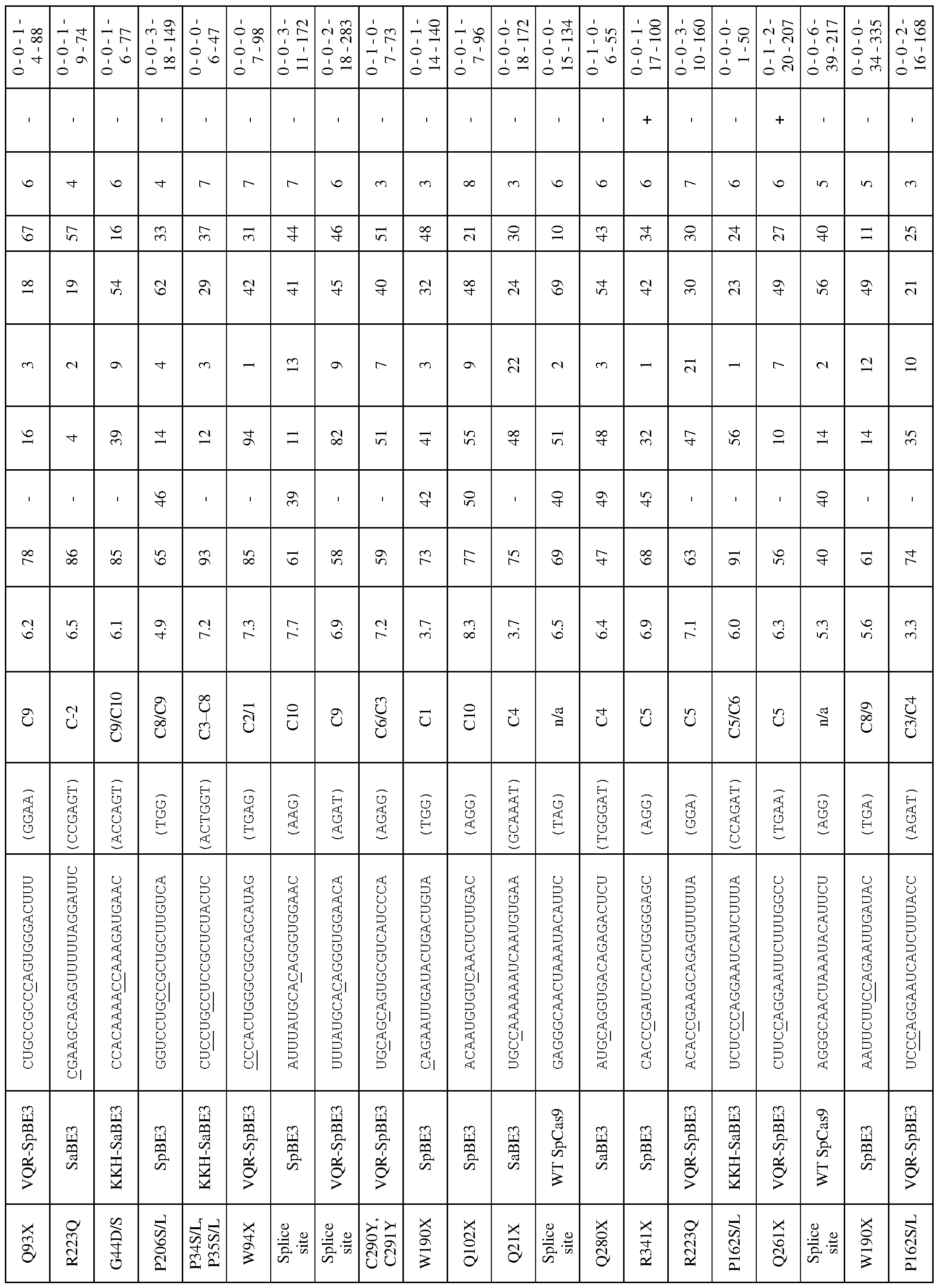
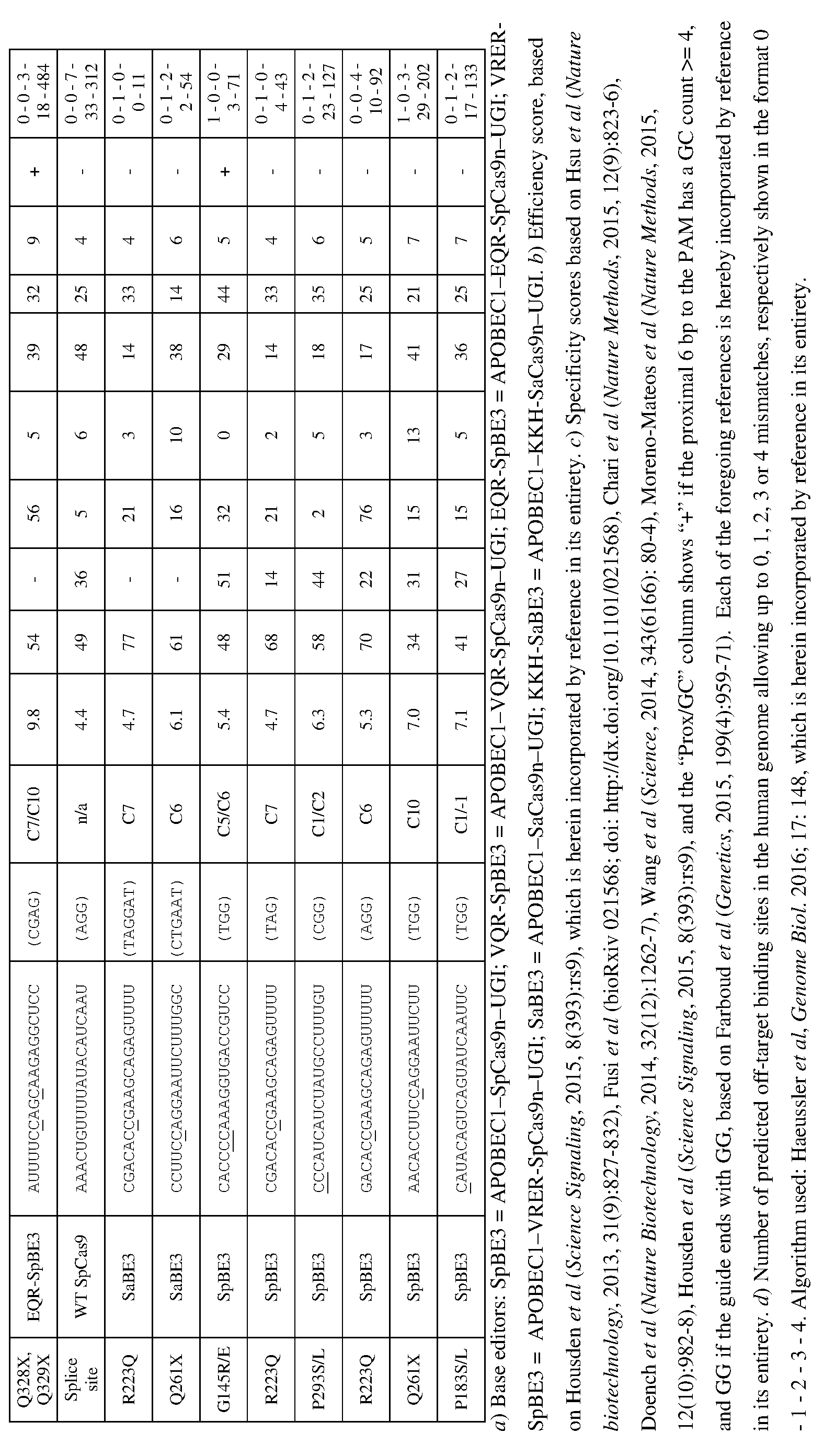
[00243] Table 9. Examples of specific guide RNA sequences used for making variants. The guide RNA sequences, from top to bottom, correspond to SEQ ID NOs: 637-657 and the CCR2 sequences, from top to bottom, correspond to SEQ ID NOs: 658-678.
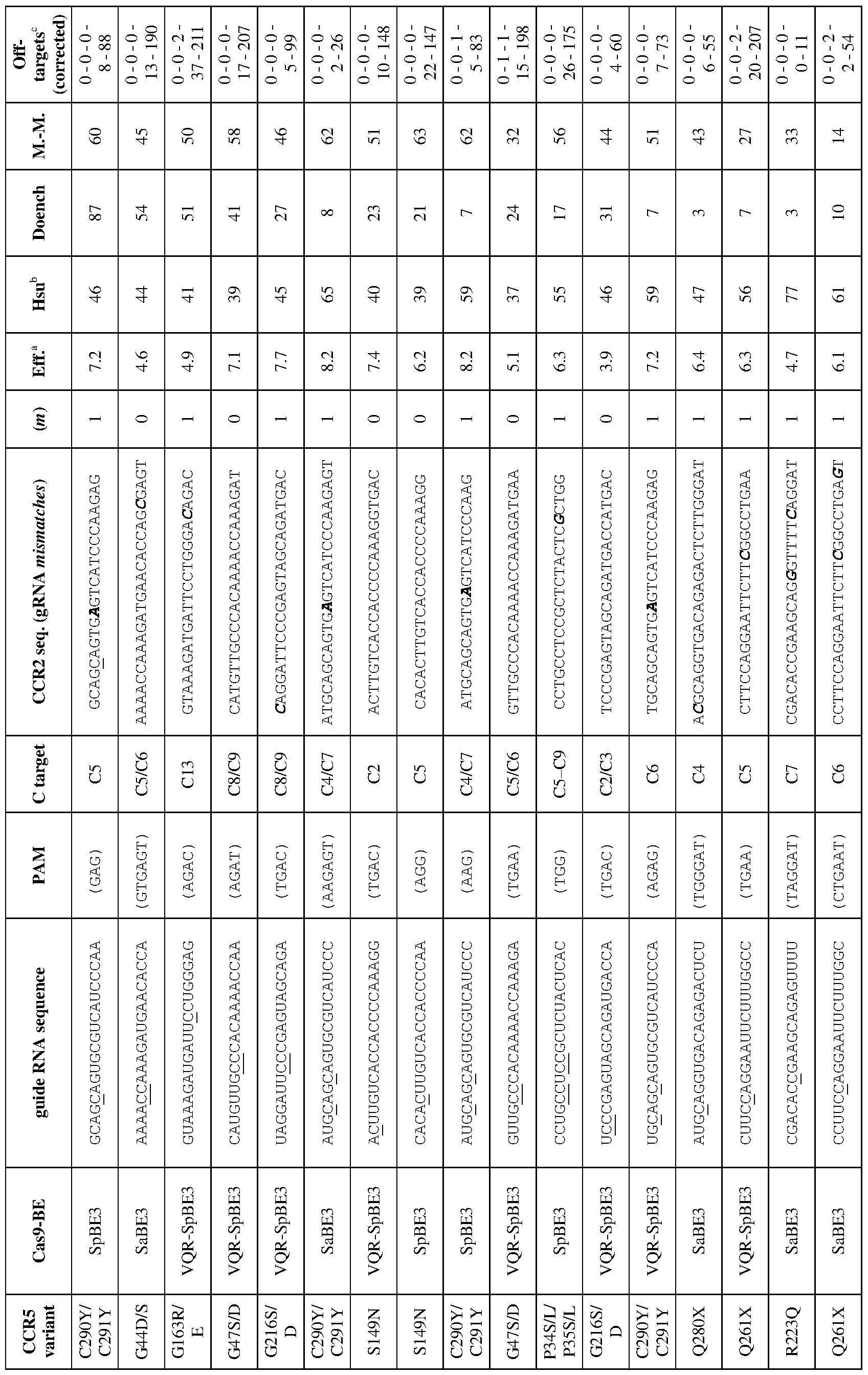
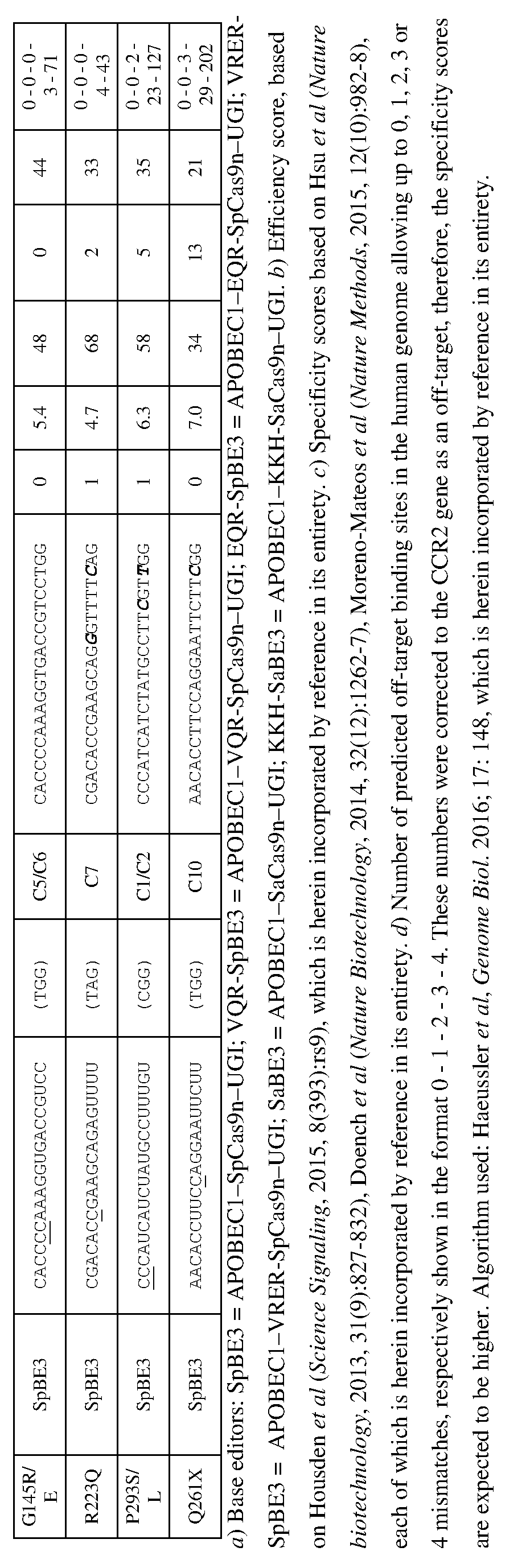
REFERENCES
1. Komor, A. C; Kim, Y. B.; Packer, M. S.; Zuris, J. A.; Liu, D. R., Programmable editing of a target base in genomic DNA without double-stranded DNA cleavage. Nature 2016, advance online publication.
2. (a) Cong, L.; Ran, F. A.; Cox, D.; Lin, S.; Barretto, R.; Habib, N.; Hsu, P. D.; Wu, X.; Jiang, W.; Marraffini, L. A.; Zhang, F., Multiplex genome engineering using CRISPR/Cas systems. Science 2013, 339 (6121), 819-23; (b) Jinek, M.; Chylinski, K.; Fonfara, I.; Hauer, M.; Doudna, J. A.;
Charpentier, E., A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science 2012, 337 (6096), 816-21; (c) Mali, P.; Yang, L.; Esvelt, K. M.; Aach, J.; Guell, M.; DiCarlo, J. E.; Norville, J. E.; Church, G. M., RNA-guided human genome engineering via Cas9. Science 2013, 339 (6121), 823-6.
3. Ran, F. A.; Hsu, P. D.; Lin, C. Y.; Gootenberg, J. S.; Konermann, S.; Trevino, A. E.; Scott, D.
A. ; Inoue, A.; Matoba, S.; Zhang, Y.; Zhang, F., Double nicking by RNA-guided CRISPR Cas9 for enhanced genome editing specificity. Cell 2013, 154 (6), 1380-9.
4. (a) Guilinger, J. P.; Thompson, D. B.; Liu, D. R., Fusion of catalytically inactive Cas9 to Fokl nuclease improves the specificity of genome modification. Nature biotechnology 2014, 32 (6), 577- 82; (b) Tsai, S. Q.; Wyvekens, N.; Khayter, C; Foden, J. A.; Thapar, V.; Reyon, D.; Goodwin, M. J.; Aryee, M. J.; Joung, J. K., Dimeric CRISPR RNA-guided Fokl nucleases for highly specific genome editing. Nature biotechnology 2014, 32 (6), 569-76.
5. (a) Capoulade-Metay, C; Ma, L.; Truong, L. X.; Dudoit, Y.; Versmisse, P.; Nguyen, N. V.; Nguyen, M.; Scott-Algara, D.; Barre-Sinoussi, F.; Debre, P.; Bismuth, G.; Pancino, G.; Theodorou, I., New CCR5 variants associated with reduced HIV coreceptor function in southeast Asia. AIDS 2004, 18 (17), 2243-52; (b) Carrington, M.; Kissner, T.; Gerrard, B.; Ivanov, S.; O'Brien, S. J.; Dean, M., Novel alleles of the chemokine-receptor gene CCR5. American journal of human genetics 1997, 61 (6), 1261-7; (c) Barmania, F.; Pepper, M. S., C-C chemokine receptor type five (CCR5): An emerging target for the control of HIV infection. Applied & Translational Genomics 2013, 2, 3-16; (d) Cox, D.
B. ; Piatt, R. J.; Zhang, F., Therapeutic genome editing: prospects and challenges. Nature medicine 2015, 21 (2), 121-31; (e) Dean, M.; Carrington, M.; Winkler, C; Huttley, G. A.; Smith, M. W.;
Allikmets, R.; Goedert, J. J.; Buchbinder, S. P.; Vittinghoff, E.; Gomperts, E.; Donfield, S.; Vlahov, D.; Kaslow, R.; Saah, A.; Rinaldo, C; Detels, R.; O'Brien, S. J., Genetic restriction of HIV-1 infection and progression to AIDS by a deletion allele of the CKR5 structural gene. Hemophilia Growth and Development Study, Multicenter AIDS Cohort Study, Multicenter Hemophilia Cohort Study, San Francisco City Cohort, ALIVE Study. Science 1996, 273 (5283), 1856-62.
6. (a) Lee, B.; Doranz, B. J.; Rana, S.; Yi, Y.; Mellado, M.; Frade, J. M.; Martinez, A. C;
O'Brien, S. J.; Dean, M.; Collman, R. G.; Doms, R. W., Influence of the CCR2-V64I polymorphism on human immunodeficiency virus type 1 coreceptor activity and on chemokine receptor function of CCR2b, CCR3, CCR5, and CXCR4. Journal of virology 1998, 72 (9), 7450-8; (b) Apostolakis, S.;
Baritaki, S.; Krambovitis, E.; Spandidos, D. A., Distribution of HIV/ AIDS protective SDF1, CCR5 and CCR2 gene variants within Cretan population. Journal of clinical virology : the official publication of the Pan American Society for Clinical Virology 2005, 34 (4), 310-4; (c) Nakayama, E. E.; Tanaka, Y.; Nagai, Y.; Iwamoto, A.; Shioda, T., A CCR2-V64I polymorphism affects stability of CCR2A isoform. AIDS 2004, 18 (5), 729-38.
7. (a) Cradick, T. J.; Fine, E. J.; Antico, C. J.; Bao, G., CRISPR/Cas9 systems targeting β-globin and CCR5 genes have substantial off -target activity. Nucleic acids research 2013; (b) Holt, N.; Wang, J.; Kim, K.; Friedman, G.; Wang, X.; Taupin, V.; Crooks, G. M.; Kohn, D. B.; Gregory, P. D.;
Holmes, M. C; Cannon, P. M., Human hematopoietic stem/progenitor cells modified by zinc -finger nucleases targeted to CCR5 control HIV-1 in vivo. Nature biotechnology 2010, 28 (8), 839-47.
8. Koonin, E. V.; Novozhilov, A. S., Origin and evolution of the genetic code: the universal enigma. IUBMB life 2009, 61 (2), 99-111.
9. (a) Thomas, M. A.; Weston, B.; Joseph, M.; Wu, W.; Nekrutenko, A.; Tonellato, P. J., Evolutionary dynamics of oncogenes and tumor suppressor genes: higher intensities of purifying selection than other genes. Molecular biology and evolution 2003, 20 (6), 964-8; (b) Iengar, P., An analysis of substitution, deletion and insertion mutations in cancer genes. Nucleic acids research 2012, 40 (14), 6401-13.
[00244] All publications, patents, patent applications, publication, and database entries
{e.g., sequence database entries) mentioned herein, e.g., in the Background, Summary, Detailed Description, Examples, and/or References sections, are hereby incorporated by reference in their entirety as if each individual publication, patent, patent application, publication, and database entry was specifically and individually incorporated herein by reference. In case of conflict, the present application, including any definitions herein, will control.
EQUIVALENTS AND SCOPE
[00245] Those skilled in the art will recognize, or be able to ascertain using no more than routine experimentation, many equivalents of the embodiments described herein. The scope of the present disclosure is not intended to be limited to the above description, but rather is as set forth in the appended claims.
[00246] Articles such as "a," "an," and "the" may mean one or more than one unless indicated to the contrary or otherwise evident from the context. Claims or descriptions that include "or" between two or more members of a group are considered satisfied if one, more than one, or all of the group members are present, unless indicated to the contrary or
otherwise evident from the context. The disclosure of a group that includes "or" between two or more group members provides embodiments in which exactly one member of the group is present, embodiments in which more than one members of the group are present, and embodiments in which all of the group members are present. For purposes of brevity those embodiments have not been individually spelled out herein, but it will be understood that each of these embodiments is provided herein and may be specifically claimed or disclaimed.
[00247] It is to be understood that the instant compositions and methods encompasses all variations, combinations, and permutations in which one or more limitation, element, clause, or descriptive term, from one or more of the claims or from one or more relevant portion of the description, is introduced into another claim. For example, a claim that is dependent on another claim can be modified to include one or more of the limitations found in any other claim that is dependent on the same base claim. Furthermore, where the claims recite a composition, it is to be understood that methods of making or using the composition according to any of the methods of making or using disclosed herein or according to methods known in the art, if any, are included, unless otherwise indicated or unless it would be evident to one of ordinary skill in the art that a contradiction or inconsistency would arise.
[00248] Where elements are presented as lists, e.g., in Markush group format, it is to be understood that every possible subgroup of the elements is also disclosed, and that any element or subgroup of elements can be removed from the group. It is also noted that the term "comprising" is intended to be open and permits the inclusion of additional elements or steps. It should be understood that, in general, where an embodiment, product, or method is referred to as comprising particular elements, features, or steps, embodiments, products, or methods that consist, or consist essentially of, such elements, features, or steps, are provided as well. For purposes of brevity those embodiments have not been individually spelled out herein, but it will be understood that each of these embodiments is provided herein and may be specifically claimed or disclaimed.
[00249] Where ranges are given, endpoints are included. Furthermore, it is to be understood that unless otherwise indicated or otherwise evident from the context and/or the understanding of one of ordinary skill in the art, values that are expressed as ranges can assume any specific value within the stated ranges in some embodiments, to the tenth of the unit of the lower limit of the range, unless the context clearly dictates otherwise. For purposes of brevity, the values in each range have not been individually spelled out herein, but it will be understood that each of these values is provided herein and may be specifically claimed or disclaimed. It is also to be understood that unless otherwise indicated or
otherwise evident from the context and/or the understanding of one of ordinary skill in the art, values expressed as ranges can assume any subrange within the given range, wherein the endpoints of the subrange are expressed to the same degree of accuracy as the tenth of the unit of the lower limit of the range.
[00250] In addition, it is to be understood that any particular embodiment of the present compositions and methods may be explicitly excluded from any one or more of the claims. Where ranges are given, any value within the range may explicitly be excluded from any one or more of the claims. Any embodiment, element, feature, application, or aspect of the compositions and/or methods of the disclosure can be excluded from any one or more claims. For purposes of brevity, all of the embodiments in which one or more elements, features, purposes, or aspects is excluded are not set forth explicitly herein.